 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-Sphere Quantization: Communication-Efficient SGD for Federated Learning
Paper and Code



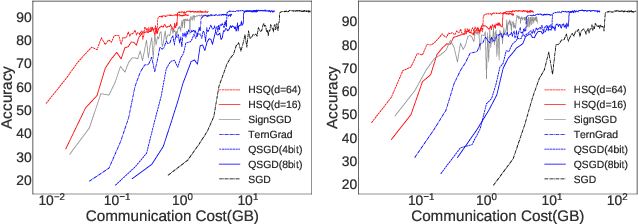
The high cost of communicating gradients is a major bottleneck for federated learning, as the bandwidth of the participating user devices is limited. Existing gradient compression algorithms are mainly designed for data centers with high-speed network and achieve $O(\sqrt{d} \log d)$ per-iteration communication cost at best, where $d$ is the size of the model. We propose hyper-sphere quantization (HSQ), a general framework that can be configured to achieve a continuum of trade-offs between communication efficiency and gradient accuracy. In particular, at the high compression ratio end, HSQ provides a low per-iteration communication cost of $O(\log d)$, which is favorable for federated learning. We prove the convergence of HSQ theoretically and show by experiments that HSQ significantly reduces the communication cost of model training without hurting convergence accuracy.