 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-Sphere Quantization: Communication-Efficient SGD for Federated Learning
Nov 25, 2019


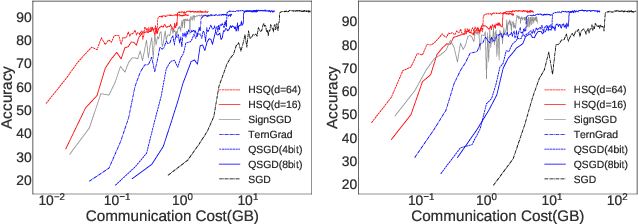
The high cost of communicating gradients is a major bottleneck for federated learning, as the bandwidth of the participating user devices is limited. Existing gradient compression algorithms are mainly designed for data centers with high-speed network and achieve $O(\sqrt{d} \log d)$ per-iteration communication cost at best, where $d$ is the size of the model. We propose hyper-sphere quantization (HSQ), a general framework that can be configured to achieve a continuum of trade-offs between communication efficiency and gradient accuracy. In particular, at the high compression ratio end, HSQ provides a low per-iteration communication cost of $O(\log d)$, which is favorable for federated learning. We prove the convergence of HSQ theoretically and show by experiments that HSQ significantly reduces the communication cost of model training without hurting convergence accuracy.
Norm-Explicit Quantization: Improving Vector Quantization for Maximum Inner Product Search
Nov 20, 2019
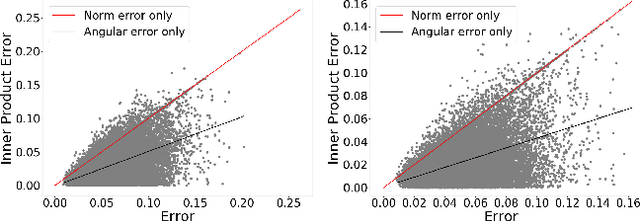


Vector quantization (VQ) techniques are widely used in similarity search for data compression, fast metric computation and etc. Originally designed for Euclidean distance, existing VQ techniques (e.g., PQ, AQ) explicitly or implicitly minimize the quantization error. In this paper, we present a new angle to analyze the quantization error, which decomposes the quantization error into norm error and direction error. We show that quantization errors in norm have much higher influence on inner products than quantization errors in direction, and small quantization error does not necessarily lead to good performance in maximum inner product search (MIPS). Based on this observation, we propose norm-explicit quantization (NEQ) --- a general paradigm that improves existing VQ techniques for MIPS. NEQ quantizes the norms of items in a dataset explicitly to reduce errors in norm, which is crucial for MIPS. For the direction vectors, NEQ can simply reuse an existing VQ technique to quantize them without modification. We conducted extensive experiments on a variety of datasets and parameter configurations. The experimental results show that NEQ improves the performance of various VQ techniques for MIPS, including PQ, OPQ, RQ and AQ.
Guaranteed Sufficient Decrease for Stochastic Variance Reduced Gradient Optimization
Feb 26, 2018
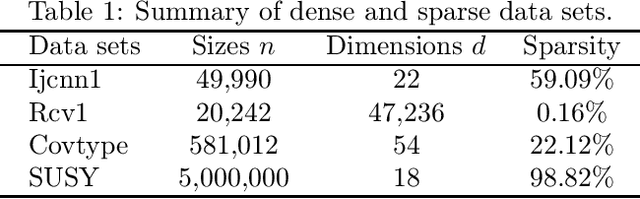
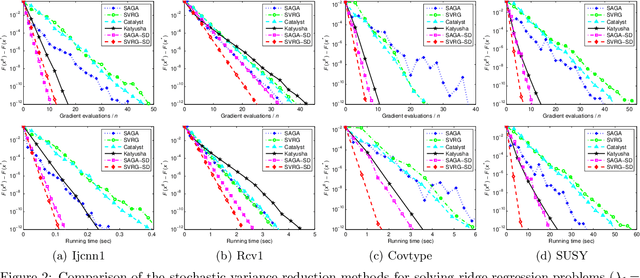

In this paper, we propose a novel sufficient decrease technique for stochastic variance reduced gradient descent methods such as SVRG and SAGA. In order to make sufficient decrease for stochastic optimization, we design a new sufficient decrease criterion, which yields sufficient decrease versions of stochastic variance reduction algorithms such as SVRG-SD and SAGA-SD as a byproduct. We introduce a coefficient to scale current iterate and to satisfy the sufficient decrease property, which takes the decisions to shrink, expand or even move in the opposite direction, and then give two specific update rules of the coefficient for Lasso and ridge regression. Moreover, we analyze the convergence properties of our algorithms for strongly convex problems, which show that our algorithms attain linear convergence rates. We also provide the convergence guarantees of our algorithms for non-strongly convex problems. Our experimental results further verify that our algorithms achieve significantly better performance than their counterparts.