 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Representation Learning Framework for Property Graphs
Jun 27, 2022
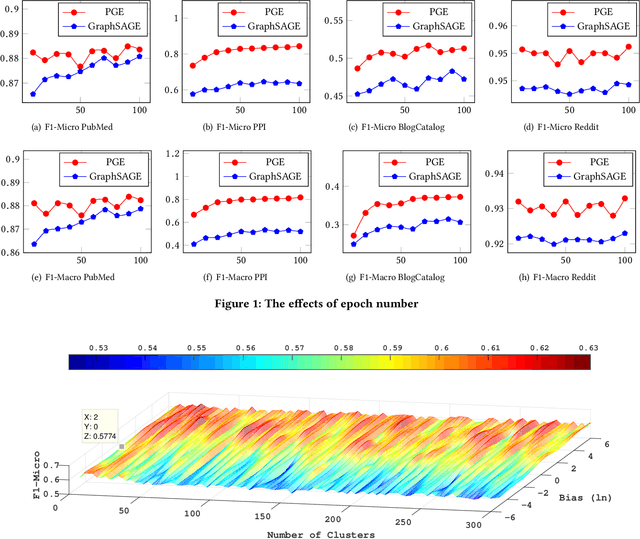

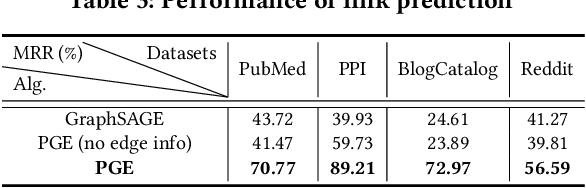
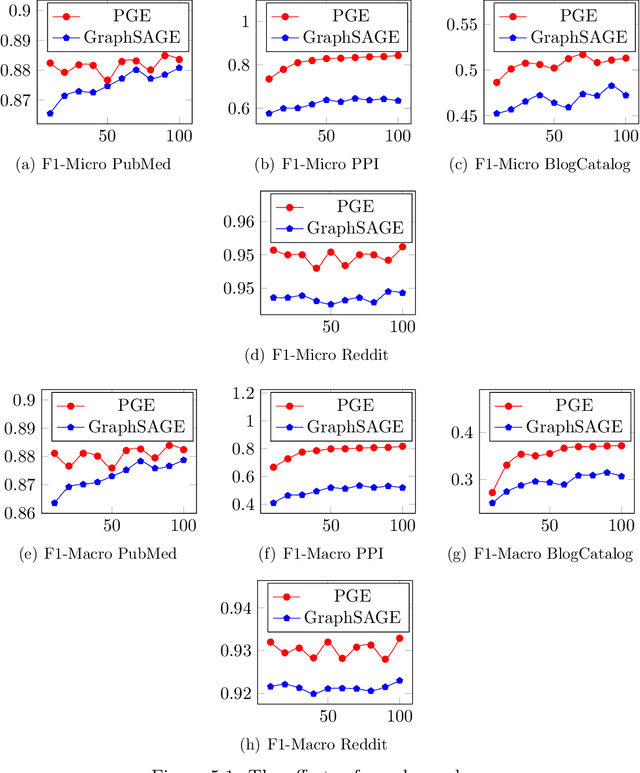
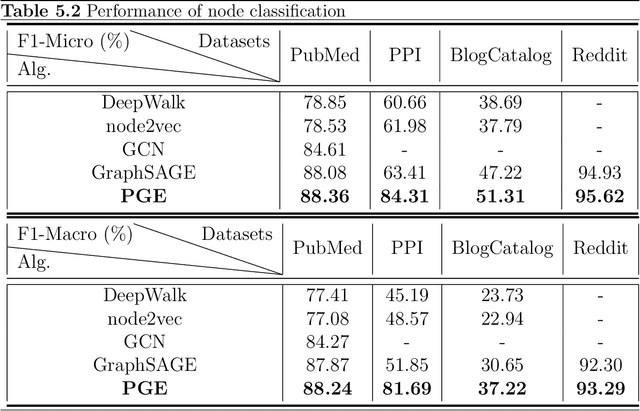
Representation learning on graphs, also called graph embedding, has demonstrated its significant impact on a series of machine learning applications such as classification, prediction and recommendation. However, existing work has largely ignored the rich information contained in the properties (or attributes) of both nodes and edges of graphs in modern applications, e.g., those represented by property graphs. To date, most existing graph embedding methods either focus on plain graphs with only the graph topology, or consider properties on nodes only. We propose PGE, a graph representation learning framework that incorporates both node and edge properties into the graph embedding procedure. PGE uses node clustering to assign biases to differentiate neighbors of a node and leverages multiple data-driven matrices to aggregate the property information of neighbors sampled based on a biased strategy. PGE adopts the popular inductive model for neighborhood aggregation. We provide detailed analyses on the efficacy of our method and validate the performance of PGE by showing how PGE achieves better embedding results than the state-of-the-art graph embedding methods on benchmark applications such as node classification and link prediction over real-world datasets.
Measuring and Improving the Use of Graph Information in Graph Neural Networks
Jun 27, 2022
Graph neural networks (GNNs) have been widely used for representation learning on graph data. However, there is limited understanding on how much performance GNNs actually gain from graph data. This paper introduces a context-surrounding GNN framework and proposes two smoothness metrics to measure the quantity and quality of information obtained from graph data. A new GNN model, called CS-GNN, is then designed to improve the use of graph information based on the smoothness values of a graph. CS-GNN is shown to achieve better performance than existing methods in different types of real graphs.
BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing
Dec 16, 2021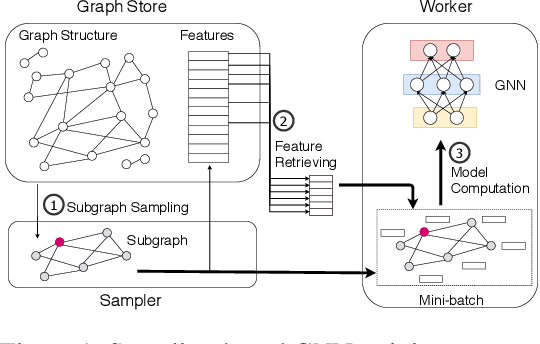
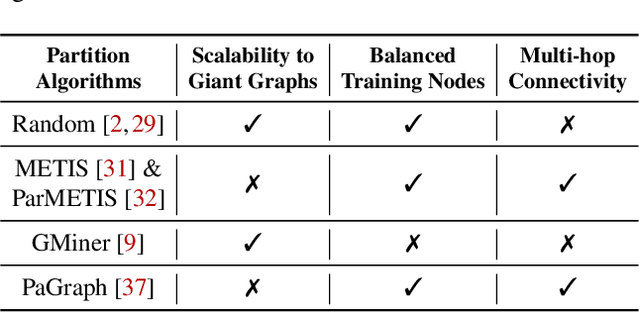
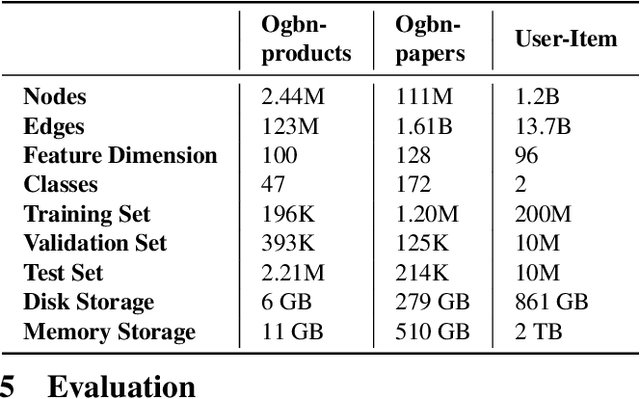
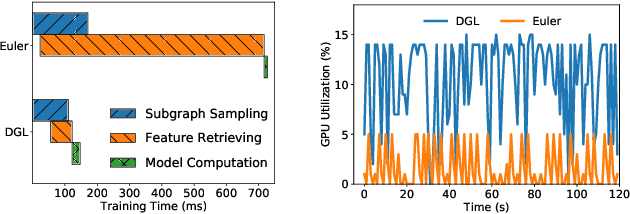
Graph neural networks (GNNs) have extended the success of deep neural networks (DNNs) to non-Euclidean graph data, achieving ground-breaking performance on various tasks such as node classification and graph property prediction. Nonetheless, existing systems are inefficient to train large graphs with billions of nodes and edges with GPUs. The main bottlenecks are the process of preparing data for GPUs - subgraph sampling and feature retrieving. This paper proposes BGL, a distributed GNN training system designed to address the bottlenecks with a few key ideas. First, we propose a dynamic cache engine to minimize feature retrieving traffic. By a co-design of caching policy and the order of sampling, we find a sweet spot of low overhead and high cache hit ratio. Second, we improve the graph partition algorithm to reduce cross-partition communication during subgraph sampling. Finally, careful resource isolation reduces contention between different data preprocessing stages. Extensive experiments on various GNN models and large graph datasets show that BGL significantly outperforms existing GNN training systems by 20.68x on average.
Norm-Ranging LSH for Maximum Inner Product Search
Oct 22, 2018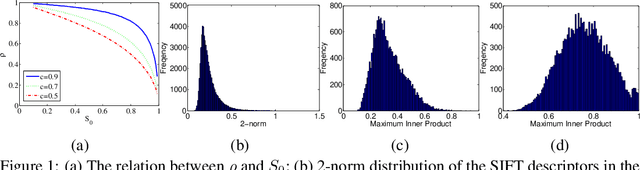

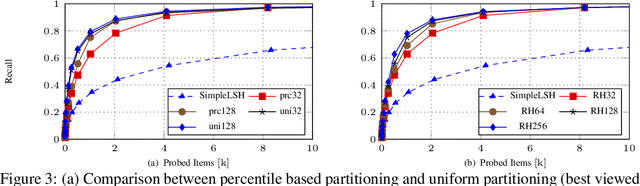
Neyshabur and Srebro proposed Simple-LSH, which is the state-of-the-art hashing method for maximum inner product search (MIPS) with performance guarantee. We found that the performance of Simple-LSH, in both theory and practice, suffers from long tails in the 2-norm distribution of real datasets. We propose Norm-ranging LSH, which addresses the excessive normalization problem caused by long tails in Simple-LSH by partitioning a dataset into multiple sub-datasets and building a hash index for each sub-dataset independently. We prove that Norm-ranging LSH has lower query time complexity than Simple-LSH. We also show that the idea of partitioning the dataset can improve other hashing based methods for MIPS. To support efficient query processing on the hash indexes of the sub-datasets, a novel similarity metric is formulated. Experiments show that Norm-ranging LSH achieves an order of magnitude speedup over Simple-LSH for the same recall, thus significantly benefiting applications that involve MIPS.