 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMA: Online RAG Alignment with Human Feedback
Nov 06, 2025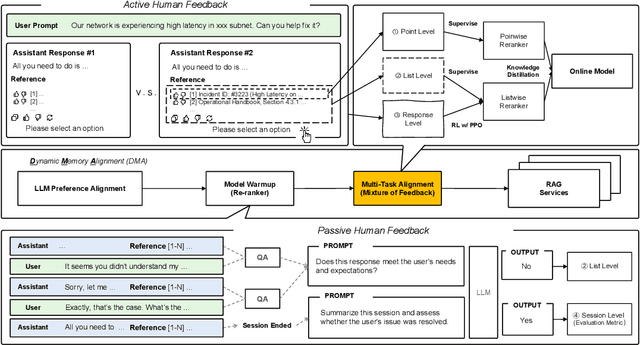

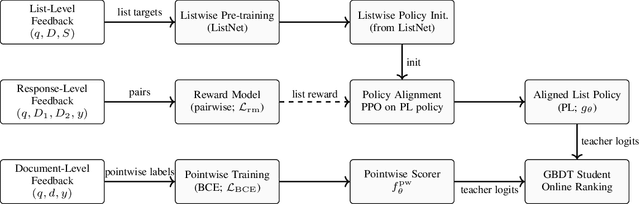
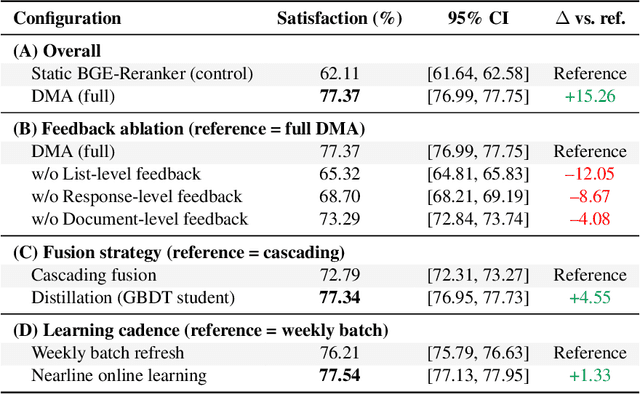
Retrieval-augmented generation (RAG) systems often rely on static retrieval, limiting adaptation to evolving intent and content drift. We introduce Dynamic Memory Alignment (DMA), an online learning framework that systematically incorporates multi-granularity human feedback to align ranking in interactive settings. DMA organizes document-, list-, and response-level signals into a coherent learning pipeline: supervised training for pointwise and listwise rankers, policy optimization driven by response-level preferences, and knowledge distillation into a lightweight scorer for low-latency serving. Throughout this paper, memory refers to the model's working memory, which is the entire context visible to the LLM for In-Context Learning. We adopt a dual-track evaluation protocol mirroring deployment: (i) large-scale online A/B ablations to isolate the utility of each feedback source, and (ii) few-shot offline tests on knowledge-intensive benchmarks. Online, a multi-month industrial deployment further shows substantial improvements in human engagement. Offline, DMA preserves competitive foundational retrieval while yielding notable gains on conversational QA (TriviaQA, HotpotQA). Taken together, these results position DMA as a principled approach to feedback-driven, real-time adaptation in RAG without sacrificing baseline capability.
BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing
Dec 16, 2021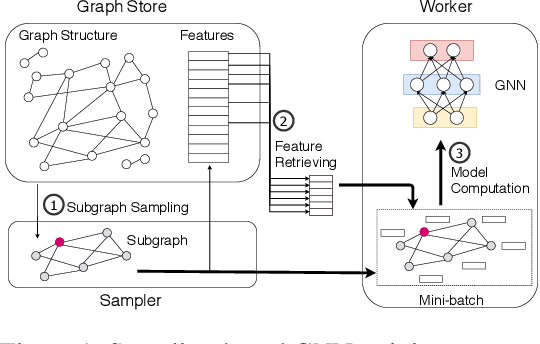
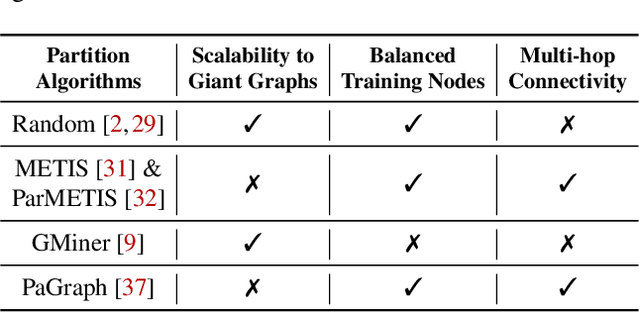
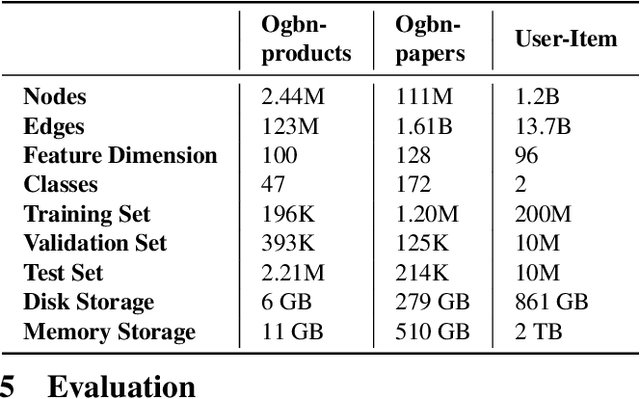
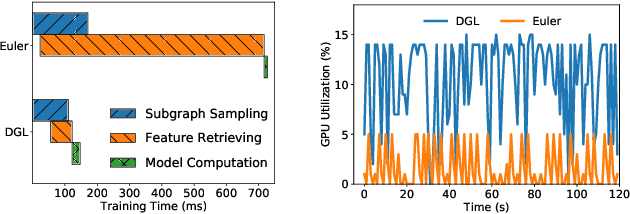
Graph neural networks (GNNs) have extended the success of deep neural networks (DNNs) to non-Euclidean graph data, achieving ground-breaking performance on various tasks such as node classification and graph property prediction. Nonetheless, existing systems are inefficient to train large graphs with billions of nodes and edges with GPUs. The main bottlenecks are the process of preparing data for GPUs - subgraph sampling and feature retrieving. This paper proposes BGL, a distributed GNN training system designed to address the bottlenecks with a few key ideas. First, we propose a dynamic cache engine to minimize feature retrieving traffic. By a co-design of caching policy and the order of sampling, we find a sweet spot of low overhead and high cache hit ratio. Second, we improve the graph partition algorithm to reduce cross-partition communication during subgraph sampling. Finally, careful resource isolation reduces contention between different data preprocessing stages. Extensive experiments on various GNN models and large graph datasets show that BGL significantly outperforms existing GNN training systems by 20.68x on average.