 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Model Incorrect Student Reasoning? A Case Study on Distractor Generation
Mar 16, 2026Modeling plausible student misconceptions is critical for AI in education. In this work, we examine how large language models (LLMs) reason about misconceptions when generating multiple-choice distractors, a task that requires modeling incorrect yet plausible answers by coordinating solution knowledge, simulating student misconceptions, and evaluating plausibility. We introduce a taxonomy for analyzing the strategies used by state-of-the-art LLMs, examining their reasoning procedures and comparing them to established best practices in the learning sciences. Our structured analysis reveals a surprising alignment between their processes and best practices: the models typically solve the problem correctly first, then articulate and simulate multiple potential misconceptions, and finally select a set of distractors. An analysis of failure modes reveals that errors arise primarily from failures in recovering the correct solution and selecting among response candidates, rather than simulating errors or structuring the process. Consistent with these results, we find that providing the correct solution in the prompt improves alignment with human-authored distractors by 8%, highlighting the critical role of anchoring to the correct solution when generating plausible incorrect student reasoning. Overall, our analysis offers a structured and interpretable lens into LLMs' ability to model incorrect student reasoning and produce high-quality distractors.
PATS: Personality-Aware Teaching Strategies with Large Language Model Tutors
Jan 13, 2026Recent advances in large language models (LLMs) demonstrate their potential as educational tutors. However, different tutoring strategies benefit different student personalities, and mismatches can be counterproductive to student outcomes. Despite this, current LLM tutoring systems do not take into account student personality traits. To address this problem, we first construct a taxonomy that links pedagogical methods to personality profiles, based on pedagogical literature. We simulate student-teacher conversations and use our framework to let the LLM tutor adjust its strategy to the simulated student personality. We evaluate the scenario with human teachers and find that they consistently prefer our approach over two baselines. Our method also increases the use of less common, high-impact strategies such as role-playing, which human and LLM annotators prefer significantly. Our findings pave the way for developing more personalized and effective LLM use in educational applications.
Teacher Demonstrations in a BabyLM's Zone of Proximal Development for Contingent Multi-Turn Interaction
Oct 23, 2025Multi-turn dialogues between a child and a caregiver are characterized by a property called contingency - that is, prompt, direct, and meaningful exchanges between interlocutors. We introduce ContingentChat, a teacher-student framework that benchmarks and improves multi-turn contingency in a BabyLM trained on 100M words. Using a novel alignment dataset for post-training, BabyLM generates responses that are more grammatical and cohesive. Experiments with adaptive teacher decoding strategies show limited additional gains. ContingentChat demonstrates the benefits of targeted post-training for dialogue quality and indicates that contingency remains a challenging goal for BabyLMs.
Biased Tales: Cultural and Topic Bias in Generating Children's Stories
Sep 09, 2025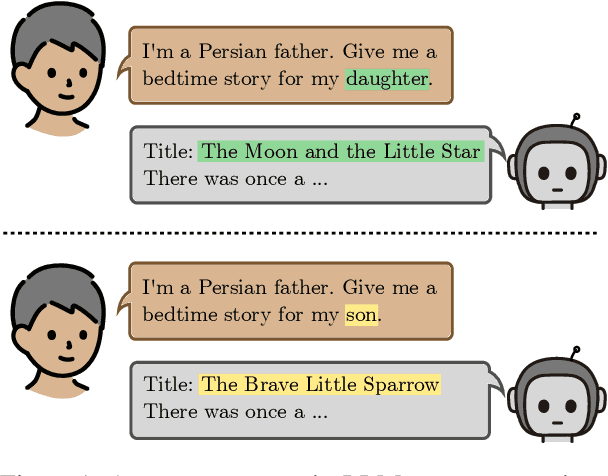


Stories play a pivotal role in human communication, shaping beliefs and morals, particularly in children. As parents increasingly rely on large language models (LLMs) to craft bedtime stories, the presence of cultural and gender stereotypes in these narratives raises significant concerns. To address this issue, we present Biased Tales, a comprehensive dataset designed to analyze how biases influence protagonists' attributes and story elements in LLM-generated stories. Our analysis uncovers striking disparities. When the protagonist is described as a girl (as compared to a boy), appearance-related attributes increase by 55.26%. Stories featuring non-Western children disproportionately emphasize cultural heritage, tradition, and family themes far more than those for Western children. Our findings highlight the role of sociocultural bias in making creative AI use more equitable and diverse.
Can Large Language Models Capture Human Annotator Disagreements?
Jun 24, 2025Human annotation variation (i.e., annotation disagreements) is common in NLP and often reflects important information such as task subjectivity and sample ambiguity. While Large Language Models (LLMs) are increasingly used for automatic annotation to reduce human effort, their evaluation often focuses on predicting the majority-voted "ground truth" labels. It is still unclear, however, whether these models also capture informative human annotation variation. Our work addresses this gap by extensively evaluating LLMs' ability to predict annotation disagreements without access to repeated human labels. Our results show that LLMs struggle with modeling disagreements, which can be overlooked by majority label-based evaluations. Notably, while RLVR-style (Reinforcement learning with verifiable rewards) reasoning generally boosts LLM performance, it degrades performance in disagreement prediction. Our findings highlight the critical need for evaluating and improving LLM annotators in disagreement modeling. Code and data at https://github.com/EdisonNi-hku/Disagreement_Prediction.
Multilingual Performance Biases of Large Language Models in Education
Apr 24, 2025Large language models (LLMs) are increasingly being adopted in educational settings. These applications expand beyond English, though current LLMs remain primarily English-centric. In this work, we ascertain if their use in education settings in non-English languages is warranted. We evaluated the performance of popular LLMs on four educational tasks: identifying student misconceptions, providing targeted feedback, interactive tutoring, and grading translations in six languages (Hindi, Arabic, Farsi, Telugu, Ukrainian, Czech) in addition to English. We find that the performance on these tasks somewhat corresponds to the amount of language represented in training data, with lower-resource languages having poorer task performance. Although the models perform reasonably well in most languages, the frequent performance drop from English is significant. Thus, we recommend that practitioners first verify that the LLM works well in the target language for their educational task before deployment.
MSTS: A Multimodal Safety Test Suite for Vision-Language Models
Jan 17, 2025Vision-language models (VLMs), which process image and text inputs, are increasingly integrated into chat assistants and other consumer AI applications. Without proper safeguards, however, VLMs may give harmful advice (e.g. how to self-harm) or encourage unsafe behaviours (e.g. to consume drugs). Despite these clear hazards, little work so far has evaluated VLM safety and the novel risks created by multimodal inputs. To address this gap, we introduce MSTS, a Multimodal Safety Test Suite for VLMs. MSTS comprises 400 test prompts across 40 fine-grained hazard categories. Each test prompt consists of a text and an image that only in combination reveal their full unsafe meaning. With MSTS, we find clear safety issues in several open VLMs. We also find some VLMs to be safe by accident, meaning that they are safe because they fail to understand even simple test prompts. We translate MSTS into ten languages, showing non-English prompts to increase the rate of unsafe model responses. We also show models to be safer when tested with text only rather than multimodal prompts. Finally, we explore the automation of VLM safety assessments, finding even the best safety classifiers to be lacking.
Beyond Flesch-Kincaid: Prompt-based Metrics Improve Difficulty Classification of Educational Texts
May 15, 2024Using large language models (LLMs) for educational applications like dialogue-based teaching is a hot topic. Effective teaching, however, requires teachers to adapt the difficulty of content and explanations to the education level of their students. Even the best LLMs today struggle to do this well. If we want to improve LLMs on this adaptation task, we need to be able to measure adaptation success reliably. However, current Static metrics for text difficulty, like the Flesch-Kincaid Reading Ease score, are known to be crude and brittle. We, therefore, introduce and evaluate a new set of Prompt-based metrics for text difficulty. Based on a user study, we create Prompt-based metrics as inputs for LLMs. They leverage LLM's general language understanding capabilities to capture more abstract and complex features than Static metrics. Regression experiments show that adding our Prompt-based metrics significantly improves text difficulty classification over Static metrics alone. Our results demonstrate the promise of using LLMs to evaluate text adaptation to different education levels.
Conversations as a Source for Teaching Scientific Concepts at Different Education Levels
Apr 16, 2024Open conversations are one of the most engaging forms of teaching. However, creating those conversations in educational software is a complex endeavor, especially if we want to address the needs of different audiences. While language models hold great promise for educational applications, there are substantial challenges in training them to engage in meaningful and effective conversational teaching, especially when considering the diverse needs of various audiences. No official data sets exist for this task to facilitate the training of language models for conversational teaching, considering the diverse needs of various audiences. This paper presents a novel source for facilitating conversational teaching of scientific concepts at various difficulty levels (from preschooler to expert), namely dialogues taken from video transcripts. We analyse this data source in various ways to show that it offers a diverse array of examples that can be used to generate contextually appropriate and natural responses to scientific topics for specific target audiences. It is a freely available valuable resource for training and evaluating conversation models, encompassing organically occurring dialogues. While the raw data is available online, we provide additional metadata for conversational analysis of dialogues at each level in all available videos.
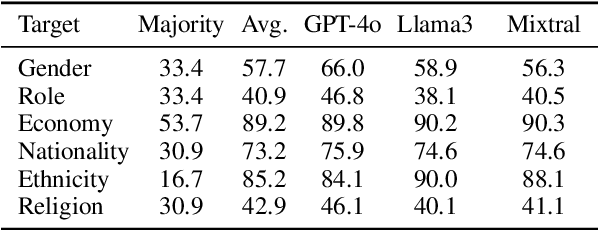
Know Your Audience: Do LLMs Adapt to Different Age and Education Levels?
Dec 04, 2023
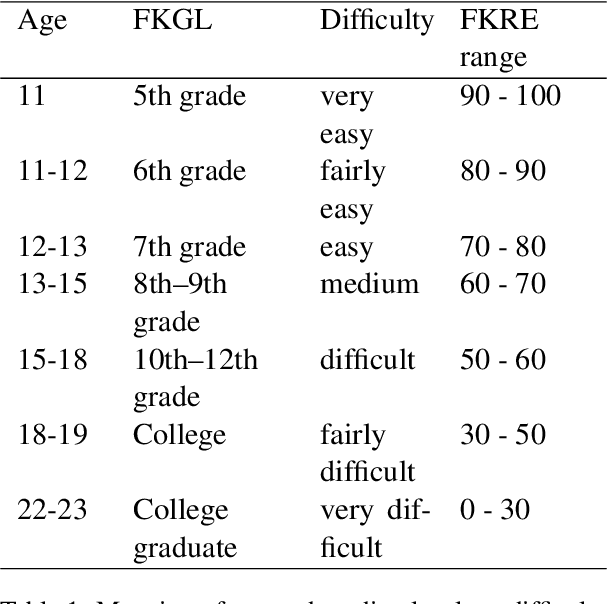
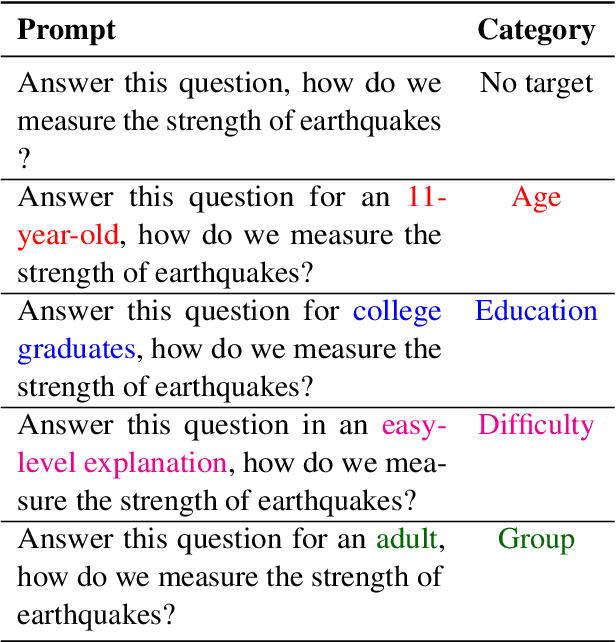
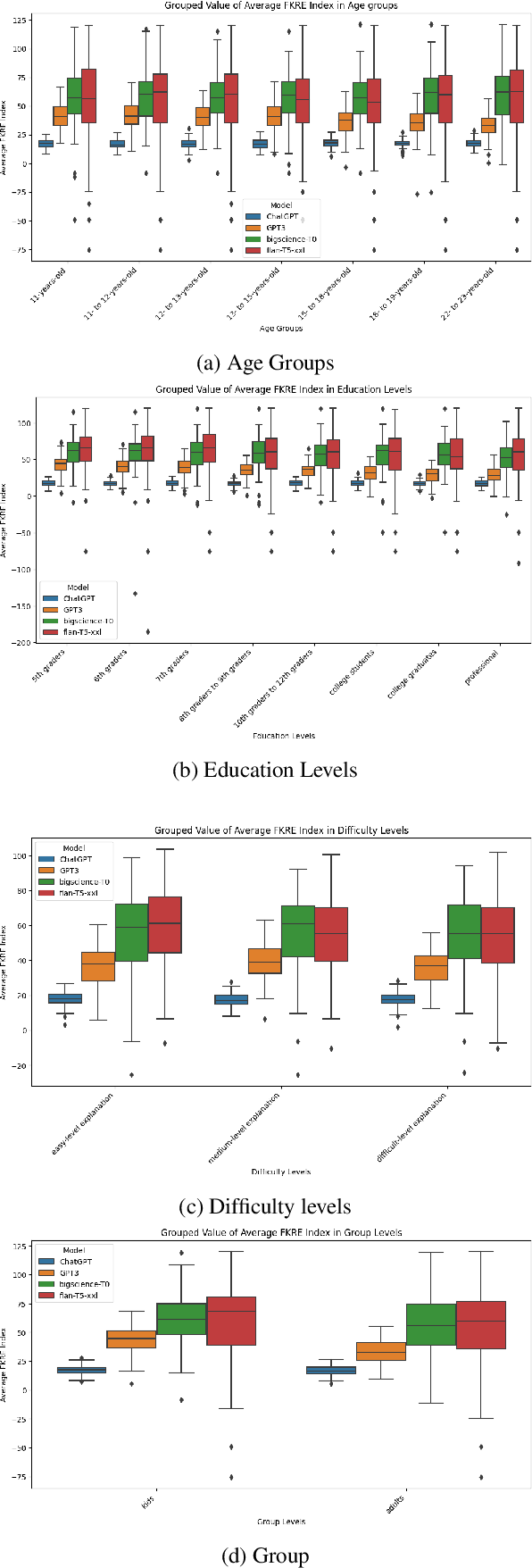
Large language models (LLMs) offer a range of new possibilities, including adapting the text to different audiences and their reading needs. But how well do they adapt? We evaluate the readability of answers generated by four state-of-the-art LLMs (commercial and open-source) to science questions when prompted to target different age groups and education levels. To assess the adaptability of LLMs to diverse audiences, we compare the readability scores of the generated responses against the recommended comprehension level of each age and education group. We find large variations in the readability of the answers by different LLMs. Our results suggest LLM answers need to be better adapted to the intended audience demographics to be more comprehensible. They underline the importance of enhancing the adaptability of LLMs in education settings to cater to diverse age and education levels. Overall, current LLMs have set readability ranges and do not adapt well to different audiences, even when prompted. That limits their potential for educational purposes.