 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepdfQA: Diverse, Challenging, and Realistic Question Answering over PDFs
Jan 06, 2026PDFs are the second-most used document type on the internet (after HTML). Yet, existing QA datasets commonly start from text sources or only address specific domains. In this paper, we present pdfQA, a multi-domain 2K human-annotated (real-pdfQA) and 2K synthetic dataset (syn-pdfQA) differentiating QA pairs in ten complexity dimensions (e.g., file type, source modality, source position, answer type). We apply and evaluate quality and difficulty filters on both datasets, obtaining valid and challenging QA pairs. We answer the questions with open-source LLMs, revealing existing challenges that correlate with our complexity dimensions. pdfQA presents a basis for end-to-end QA pipeline evaluation, testing diverse skill sets and local optimizations (e.g., in information retrieval or parsing).
Reasoning with Confidence: Efficient Verification of LLM Reasoning Steps via Uncertainty Heads
Nov 11, 2025Solving complex tasks usually requires LLMs to generate long multi-step reasoning chains. Previous work has shown that verifying the correctness of individual reasoning steps can further improve the performance and efficiency of LLMs on such tasks and enhance solution interpretability. However, existing verification approaches, such as Process Reward Models (PRMs), are either computationally expensive, limited to specific domains, or require large-scale human or model-generated annotations. Thus, we propose a lightweight alternative for step-level reasoning verification based on data-driven uncertainty scores. We train transformer-based uncertainty quantification heads (UHeads) that use the internal states of a frozen LLM to estimate the uncertainty of its reasoning steps during generation. The approach is fully automatic: target labels are generated either by another larger LLM (e.g., DeepSeek R1) or in a self-supervised manner by the original model itself. UHeads are both effective and lightweight, containing less than 10M parameters. Across multiple domains, including mathematics, planning, and general knowledge question answering, they match or even surpass the performance of PRMs that are up to 810x larger. Our findings suggest that the internal states of LLMs encode their uncertainty and can serve as reliable signals for reasoning verification, offering a promising direction toward scalable and generalizable introspective LLMs.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Can Large Language Models Capture Human Annotator Disagreements?
Jun 24, 2025Human annotation variation (i.e., annotation disagreements) is common in NLP and often reflects important information such as task subjectivity and sample ambiguity. While Large Language Models (LLMs) are increasingly used for automatic annotation to reduce human effort, their evaluation often focuses on predicting the majority-voted "ground truth" labels. It is still unclear, however, whether these models also capture informative human annotation variation. Our work addresses this gap by extensively evaluating LLMs' ability to predict annotation disagreements without access to repeated human labels. Our results show that LLMs struggle with modeling disagreements, which can be overlooked by majority label-based evaluations. Notably, while RLVR-style (Reinforcement learning with verifiable rewards) reasoning generally boosts LLM performance, it degrades performance in disagreement prediction. Our findings highlight the critical need for evaluating and improving LLM annotators in disagreement modeling. Code and data at https://github.com/EdisonNi-hku/Disagreement_Prediction.
LEXam: Benchmarking Legal Reasoning on 340 Law Exams
May 19, 2025
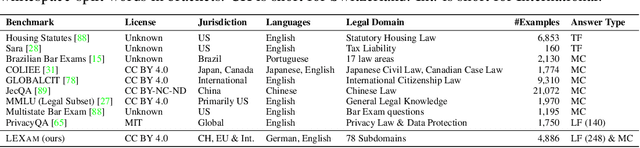
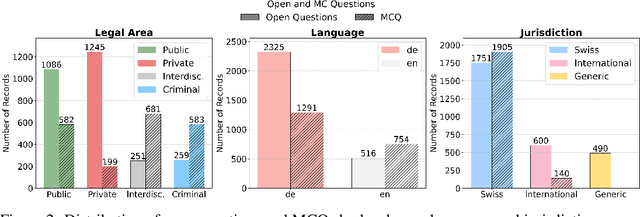
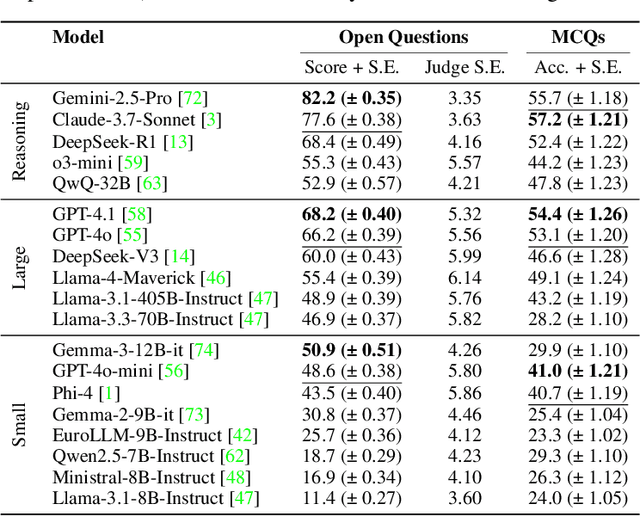
Long-form legal reasoning remains a key challenge for large language models (LLMs) in spite of recent advances in test-time scaling. We introduce LEXam, a novel benchmark derived from 340 law exams spanning 116 law school courses across a range of subjects and degree levels. The dataset comprises 4,886 law exam questions in English and German, including 2,841 long-form, open-ended questions and 2,045 multiple-choice questions. Besides reference answers, the open questions are also accompanied by explicit guidance outlining the expected legal reasoning approach such as issue spotting, rule recall, or rule application. Our evaluation on both open-ended and multiple-choice questions present significant challenges for current LLMs; in particular, they notably struggle with open questions that require structured, multi-step legal reasoning. Moreover, our results underscore the effectiveness of the dataset in differentiating between models with varying capabilities. Adopting an LLM-as-a-Judge paradigm with rigorous human expert validation, we demonstrate how model-generated reasoning steps can be evaluated consistently and accurately. Our evaluation setup provides a scalable method to assess legal reasoning quality beyond simple accuracy metrics. Project page: https://lexam-benchmark.github.io/
Navigating the Helpfulness-Truthfulness Trade-Off with Uncertainty-Aware Instruction Fine-Tuning
Feb 17, 2025Instruction Fine-tuning (IFT) can enhance the helpfulness of Large Language Models (LLMs), but it may lower their truthfulness. This trade-off arises because IFT steers LLMs to generate responses with long-tail knowledge that is not well covered during pre-training, leading to more informative but less truthful answers when generalizing to unseen tasks. In this paper, we empirically demonstrate this helpfulness-truthfulness trade-off in IFT and propose $\textbf{UNIT}$, a novel IFT paradigm to address it. UNIT teaches LLMs to recognize their uncertainty and explicitly reflect it at the end of their responses. Experimental results show that UNIT-tuned models maintain their helpfulness while distinguishing between certain and uncertain claims, thereby reducing hallucinations.
DIRAS: Efficient LLM-Assisted Annotation of Document Relevance in Retrieval Augmented Generation
Jun 20, 2024



Retrieval Augmented Generation (RAG) is widely employed to ground responses to queries on domain-specific documents. But do RAG implementations leave out important information or excessively include irrelevant information? To allay these concerns, it is necessary to annotate domain-specific benchmarks to evaluate information retrieval (IR) performance, as relevance definitions vary across queries and domains. Furthermore, such benchmarks should be cost-efficiently annotated to avoid annotation selection bias. In this paper, we propose DIRAS (Domain-specific Information Retrieval Annotation with Scalability), a manual-annotation-free schema that fine-tunes open-sourced LLMs to annotate relevance labels with calibrated relevance probabilities. Extensive evaluation shows that DIRAS fine-tuned models achieve GPT-4-level performance on annotating and ranking unseen (query, document) pairs, and is helpful for real-world RAG development.
ClimRetrieve: A Benchmarking Dataset for Information Retrieval from Corporate Climate Disclosures
Jun 14, 2024To handle the vast amounts of qualitative data produced in corporate climate communication, stakeholders increasingly rely on Retrieval Augmented Generation (RAG) systems. However, a significant gap remains in evaluating domain-specific information retrieval - the basis for answer generation. To address this challenge, this work simulates the typical tasks of a sustainability analyst by examining 30 sustainability reports with 16 detailed climate-related questions. As a result, we obtain a dataset with over 8.5K unique question-source-answer pairs labeled by different levels of relevance. Furthermore, we develop a use case with the dataset to investigate the integration of expert knowledge into information retrieval with embeddings. Although we show that incorporating expert knowledge works, we also outline the critical limitations of embeddings in knowledge-intensive downstream domains like climate change communication.
Towards Faithful and Robust LLM Specialists for Evidence-Based Question-Answering
Feb 26, 2024Advances towards more faithful and traceable answers of Large Language Models (LLMs) are crucial for various research and practical endeavors. One avenue in reaching this goal is basing the answers on reliable sources. However, this Evidence-Based QA has proven to work insufficiently with LLMs in terms of citing the correct sources (source quality) and truthfully representing the information within sources (answer attributability). In this work, we systematically investigate how to robustly fine-tune LLMs for better source quality and answer attributability. Specifically, we introduce a data generation pipeline with automated data quality filters, which can synthesize diversified high-quality training and testing data at scale. We further introduce four test sets to benchmark the robustness of fine-tuned specialist models. Extensive evaluation shows that fine-tuning on synthetic data improves performance on both in- and out-of-distribution. Furthermore, we show that data quality, which can be drastically improved by proposed quality filters, matters more than quantity in improving Evidence-Based QA.
AFaCTA: Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators
Feb 16, 2024



With the rise of generative AI, automated fact-checking methods to combat misinformation are becoming more and more important. However, factual claim detection, the first step in a fact-checking pipeline, suffers from two key issues that limit its scalability and generalizability: (1) inconsistency in definitions of the task and what a claim is, and (2) the high cost of manual annotation. To address (1), we review the definitions in related work and propose a unifying definition of factual claims that focuses on verifiability. To address (2), we introduce AFaCTA (Automatic Factual Claim deTection Annotator), a novel framework that assists in the annotation of factual claims with the help of large language models (LLMs). AFaCTA calibrates its annotation confidence with consistency along three predefined reasoning paths. Extensive evaluation and experiments in the domain of political speech reveal that AFaCTA can efficiently assist experts in annotating factual claims and training high-quality classifiers, and can work with or without expert supervision. Our analyses also result in PoliClaim, a comprehensive claim detection dataset spanning diverse political topics.