 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegal Retrieval for Public Defenders
Jan 20, 2026AI tools are increasingly suggested as solutions to assist public agencies with heavy workloads. In public defense, where a constitutional right to counsel meets the complexities of law, overwhelming caseloads and constrained resources, practitioners face especially taxing conditions. Yet, there is little evidence of how AI could meaningfully support defenders' day-to-day work. In partnership with the New Jersey Office of the Public Defender, we develop the NJ BriefBank, a retrieval tool which surfaces relevant appellate briefs to streamline legal research and writing. We show that existing legal retrieval benchmarks fail to transfer to public defense search, however adding domain knowledge improves retrieval quality. This includes query expansion with legal reasoning, domain-specific data and curated synthetic examples. To facilitate further research, we provide a taxonomy of realistic defender search queries and release a manually annotated public defense retrieval dataset. Together, our work offers starting points towards building practical, reliable retrieval AI tools for public defense, and towards more realistic legal retrieval benchmarks.
A Multimodal Benchmark for Framing of Oil & Gas Advertising and Potential Greenwashing Detection
Oct 24, 2025Companies spend large amounts of money on public relations campaigns to project a positive brand image. However, sometimes there is a mismatch between what they say and what they do. Oil & gas companies, for example, are accused of "greenwashing" with imagery of climate-friendly initiatives. Understanding the framing, and changes in framing, at scale can help better understand the goals and nature of public relations campaigns. To address this, we introduce a benchmark dataset of expert-annotated video ads obtained from Facebook and YouTube. The dataset provides annotations for 13 framing types for more than 50 companies or advocacy groups across 20 countries. Our dataset is especially designed for the evaluation of vision-language models (VLMs), distinguishing it from past text-only framing datasets. Baseline experiments show some promising results, while leaving room for improvement for future work: GPT-4.1 can detect environmental messages with 79% F1 score, while our best model only achieves 46% F1 score on identifying framing around green innovation. We also identify challenges that VLMs must address, such as implicit framing, handling videos of various lengths, or implicit cultural backgrounds. Our dataset contributes to research in multimodal analysis of strategic communication in the energy sector.
What Is The Political Content in LLMs' Pre- and Post-Training Data?
Sep 26, 2025
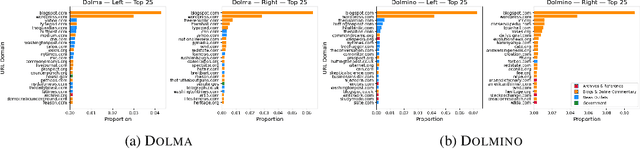


Large language models (LLMs) are known to generate politically biased text, yet how such biases arise remains unclear. A crucial step toward answering this question is the analysis of training data, whose political content remains largely underexplored in current LLM research. To address this gap, we present in this paper an analysis of the pre- and post-training corpora of OLMO2, the largest fully open-source model released together with its complete dataset. From these corpora, we draw large random samples, automatically annotate documents for political orientation, and analyze their source domains and content. We then assess how political content in the training data correlates with models' stance on specific policy issues. Our analysis shows that left-leaning documents predominate across datasets, with pre-training corpora containing significantly more politically engaged content than post-training data. We also find that left- and right-leaning documents frame similar topics through distinct values and sources of legitimacy. Finally, the predominant stance in the training data strongly correlates with models' political biases when evaluated on policy issues. These findings underscore the need to integrate political content analysis into future data curation pipelines as well as in-depth documentation of filtering strategies for transparency.
NLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
Aligning Large Language Models with Diverse Political Viewpoints
Jun 20, 2024Large language models such as ChatGPT often exhibit striking political biases. If users query them about political information, they might take a normative stance and reinforce such biases. To overcome this, we align LLMs with diverse political viewpoints from 100,000 comments written by candidates running for national parliament in Switzerland. Such aligned models are able to generate more accurate political viewpoints from Swiss parties compared to commercial models such as ChatGPT. We also propose a procedure to generate balanced overviews from multiple viewpoints using such models.
AFaCTA: Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators
Feb 16, 2024



With the rise of generative AI, automated fact-checking methods to combat misinformation are becoming more and more important. However, factual claim detection, the first step in a fact-checking pipeline, suffers from two key issues that limit its scalability and generalizability: (1) inconsistency in definitions of the task and what a claim is, and (2) the high cost of manual annotation. To address (1), we review the definitions in related work and propose a unifying definition of factual claims that focuses on verifiability. To address (2), we introduce AFaCTA (Automatic Factual Claim deTection Annotator), a novel framework that assists in the annotation of factual claims with the help of large language models (LLMs). AFaCTA calibrates its annotation confidence with consistency along three predefined reasoning paths. Extensive evaluation and experiments in the domain of political speech reveal that AFaCTA can efficiently assist experts in annotating factual claims and training high-quality classifiers, and can work with or without expert supervision. Our analyses also result in PoliClaim, a comprehensive claim detection dataset spanning diverse political topics.
Automated Fact-Checking of Climate Change Claims with Large Language Models
Jan 23, 2024This paper presents Climinator, a novel AI-based tool designed to automate the fact-checking of climate change claims. Utilizing an array of Large Language Models (LLMs) informed by authoritative sources like the IPCC reports and peer-reviewed scientific literature, Climinator employs an innovative Mediator-Advocate framework. This design allows Climinator to effectively synthesize varying scientific perspectives, leading to robust, evidence-based evaluations. Our model demonstrates remarkable accuracy when testing claims collected from Climate Feedback and Skeptical Science. Notably, when integrating an advocate with a climate science denial perspective in our framework, Climinator's iterative debate process reliably converges towards scientific consensus, underscoring its adeptness at reconciling diverse viewpoints into science-based, factual conclusions. While our research is subject to certain limitations and necessitates careful interpretation, our approach holds significant potential. We hope to stimulate further research and encourage exploring its applicability in other contexts, including political fact-checking and legal domains.
LePaRD: A Large-Scale Dataset of Judges Citing Precedents
Nov 15, 2023



We present the Legal Passage Retrieval Dataset LePaRD. LePaRD is a massive collection of U.S. federal judicial citations to precedent in context. The dataset aims to facilitate work on legal passage prediction, a challenging practice-oriented legal retrieval and reasoning task. Legal passage prediction seeks to predict relevant passages from precedential court decisions given the context of a legal argument. We extensively evaluate various retrieval approaches on LePaRD, and find that classification appears to work best. However, we note that legal precedent prediction is a difficult task, and there remains significant room for improvement. We hope that by publishing LePaRD, we will encourage others to engage with a legal NLP task that promises to help expand access to justice by reducing the burden associated with legal research. A subset of the LePaRD dataset is freely available and the whole dataset will be released upon publication.
Enhancing Public Understanding of Court Opinions with Automated Summarizers
Nov 11, 2023Written judicial opinions are an important tool for building public trust in court decisions, yet they can be difficult for non-experts to understand. We present a pipeline for using an AI assistant to generate simplified summaries of judicial opinions. These are more accessible to the public and more easily understood by non-experts, We show in a survey experiment that the simplified summaries help respondents understand the key features of a ruling. We discuss how to integrate legal domain knowledge into studies using large language models. Our results suggest a role both for AI assistants to inform the public, and for lawyers to guide the process of generating accessible summaries.
The Law and NLP: Bridging Disciplinary Disconnects
Oct 22, 2023

Legal practice is intrinsically rooted in the fabric of language, yet legal practitioners and scholars have been slow to adopt tools from natural language processing (NLP). At the same time, the legal system is experiencing an access to justice crisis, which could be partially alleviated with NLP. In this position paper, we argue that the slow uptake of NLP in legal practice is exacerbated by a disconnect between the needs of the legal community and the focus of NLP researchers. In a review of recent trends in the legal NLP literature, we find limited overlap between the legal NLP community and legal academia. Our interpretation is that some of the most popular legal NLP tasks fail to address the needs of legal practitioners. We discuss examples of legal NLP tasks that promise to bridge disciplinary disconnects and highlight interesting areas for legal NLP research that remain underexplored.