 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHATREPORT: Democratizing Sustainability Disclosure Analysis through LLM-based Tools
Jul 28, 2023In the face of climate change, are companies really taking substantial steps toward more sustainable operations? A comprehensive answer lies in the dense, information-rich landscape of corporate sustainability reports. However, the sheer volume and complexity of these reports make human analysis very costly. Therefore, only a few entities worldwide have the resources to analyze these reports at scale, which leads to a lack of transparency in sustainability reporting. Empowering stakeholders with LLM-based automatic analysis tools can be a promising way to democratize sustainability report analysis. However, developing such tools is challenging due to (1) the hallucination of LLMs and (2) the inefficiency of bringing domain experts into the AI development loop. In this paper, we ChatReport, a novel LLM-based system to automate the analysis of corporate sustainability reports, addressing existing challenges by (1) making the answers traceable to reduce the harm of hallucination and (2) actively involving domain experts in the development loop. We make our methodology, annotated datasets, and generated analyses of 1015 reports publicly available.
Paradigm Shift in Sustainability Disclosure Analysis: Empowering Stakeholders with CHATREPORT, a Language Model-Based Tool
Jun 27, 2023This paper introduces a novel approach to enhance Large Language Models (LLMs) with expert knowledge to automate the analysis of corporate sustainability reports by benchmarking them against the Task Force for Climate-Related Financial Disclosures (TCFD) recommendations. Corporate sustainability reports are crucial in assessing organizations' environmental and social risks and impacts. However, analyzing these reports' vast amounts of information makes human analysis often too costly. As a result, only a few entities worldwide have the resources to analyze these reports, which could lead to a lack of transparency. While AI-powered tools can automatically analyze the data, they are prone to inaccuracies as they lack domain-specific expertise. This paper introduces a novel approach to enhance LLMs with expert knowledge to automate the analysis of corporate sustainability reports. We christen our tool CHATREPORT, and apply it in a first use case to assess corporate climate risk disclosures following the TCFD recommendations. CHATREPORT results from collaborating with experts in climate science, finance, economic policy, and computer science, demonstrating how domain experts can be involved in developing AI tools. We make our prompt templates, generated data, and scores available to the public to encourage transparency.
chatClimate: Grounding Conversational AI in Climate Science
Apr 28, 2023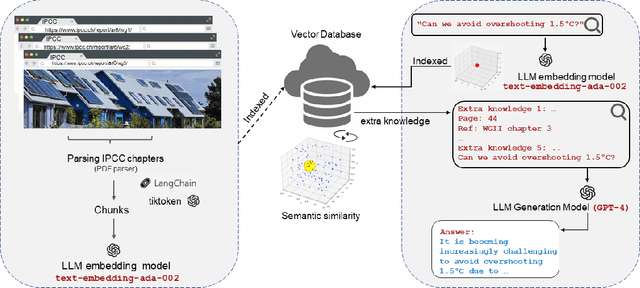
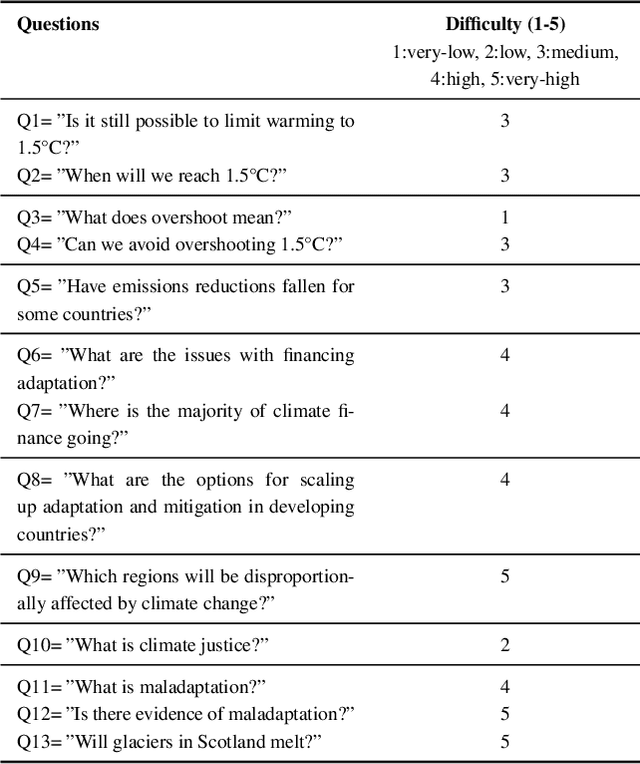


Large Language Models (LLMs) have made significant progress in recent years, achieving remarkable results in question-answering tasks (QA). However, they still face two major challenges: hallucination and outdated information after the training phase. These challenges take center stage in critical domains like climate change, where obtaining accurate and up-to-date information from reliable sources in a limited time is essential and difficult. To overcome these barriers, one potential solution is to provide LLMs with access to external, scientifically accurate, and robust sources (long-term memory) to continuously update their knowledge and prevent the propagation of inaccurate, incorrect, or outdated information. In this study, we enhanced GPT-4 by integrating the information from the Sixth Assessment Report of the Intergovernmental (IPCC AR6), the most comprehensive, up-to-date, and reliable source in this domain. We present our conversational AI prototype, available at www.chatclimate.ai and demonstrate its ability to answer challenging questions accurately in three different QA scenarios: asking from 1) GPT-4, 2) chatClimate, and 3) hybrid chatClimate. The answers and their sources were evaluated by our team of IPCC authors, who used their expert knowledge to score the accuracy of the answers from 1 (very-low) to 5 (very-high). The evaluation showed that the hybrid chatClimate provided more accurate answers, highlighting the effectiveness of our solution. This approach can be easily scaled for chatbots in specific domains, enabling the delivery of reliable and accurate information.
Enhancing Large Language Models with Climate Resources
Mar 31, 2023
Large language models (LLMs) have significantly transformed the landscape of artificial intelligence by demonstrating their ability in generating human-like text across diverse topics. However, despite their impressive capabilities, LLMs lack recent information and often employ imprecise language, which can be detrimental in domains where accuracy is crucial, such as climate change. In this study, we make use of recent ideas to harness the potential of LLMs by viewing them as agents that access multiple sources, including databases containing recent and precise information about organizations, institutions, and companies. We demonstrate the effectiveness of our method through a prototype agent that retrieves emission data from ClimateWatch (https://www.climatewatchdata.org/) and leverages general Google search. By integrating these resources with LLMs, our approach overcomes the limitations associated with imprecise language and delivers more reliable and accurate information in the critical domain of climate change. This work paves the way for future advancements in LLMs and their application in domains where precision is of paramount importance.
Towards Climate Awareness in NLP Research
May 16, 2022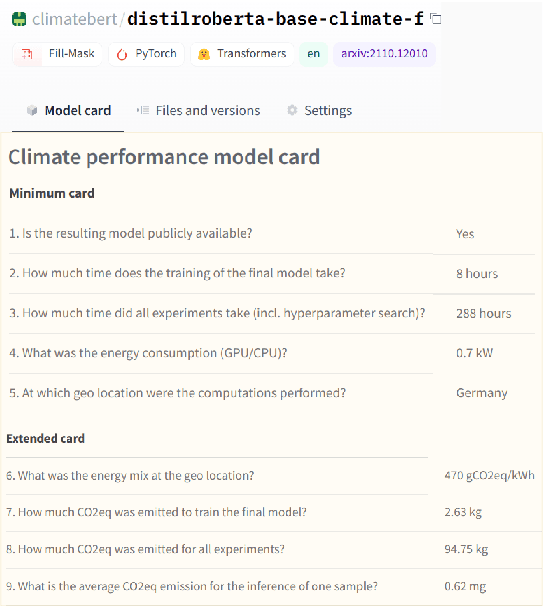

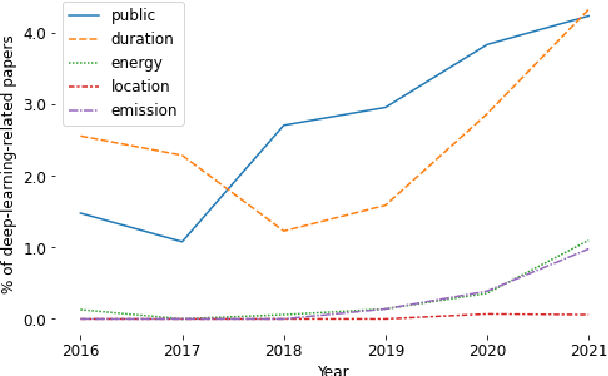

The climate impact of AI, and NLP research in particular, has become a serious issue given the enormous amount of energy that is increasingly being used for training and running computational models. Consequently, increasing focus is placed on efficient NLP. However, this important initiative lacks simple guidelines that would allow for systematic climate reporting of NLP research. We argue that this deficiency is one of the reasons why very few publications in NLP report key figures that would allow a more thorough examination of environmental impact. As a remedy, we propose a climate performance model card with the primary purpose of being practically usable with only limited information about experiments and the underlying computer hardware. We describe why this step is essential to increase awareness about the environmental impact of NLP research and, thereby, paving the way for more thorough discussions.
ClimateBert: A Pretrained Language Model for Climate-Related Text
Oct 22, 2021
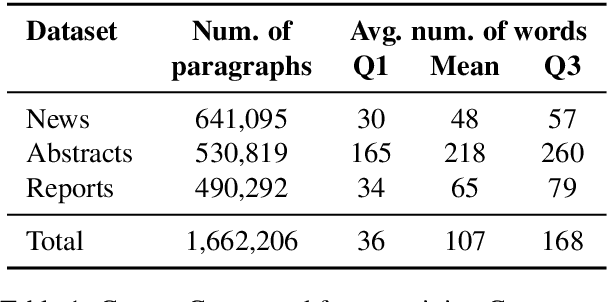
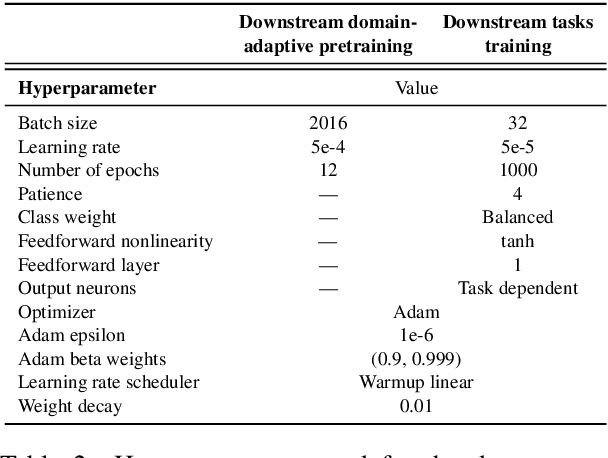

Over the recent years, large pretrained language models (LM) have revolutionized the field of natural language processing (NLP). However, while pretraining on general language has been shown to work very well for common language, it has been observed that niche language poses problems. In particular, climate-related texts include specific language that common LMs can not represent accurately. We argue that this shortcoming of today's LMs limits the applicability of modern NLP to the broad field of text processing of climate-related texts. As a remedy, we propose ClimateBert, a transformer-based language model that is further pretrained on over 1.6 million paragraphs of climate-related texts, crawled from various sources such as common news, research articles, and climate reporting of companies. We find that ClimateBertleads to a 46% improvement on a masked language model objective which, in turn, leads to lowering error rates by 3.57% to 35.71% for various climate-related downstream tasks like text classification, sentiment analysis, and fact-checking.