 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Large Language Models with Climate Resources
Mar 31, 2023
Large language models (LLMs) have significantly transformed the landscape of artificial intelligence by demonstrating their ability in generating human-like text across diverse topics. However, despite their impressive capabilities, LLMs lack recent information and often employ imprecise language, which can be detrimental in domains where accuracy is crucial, such as climate change. In this study, we make use of recent ideas to harness the potential of LLMs by viewing them as agents that access multiple sources, including databases containing recent and precise information about organizations, institutions, and companies. We demonstrate the effectiveness of our method through a prototype agent that retrieves emission data from ClimateWatch (https://www.climatewatchdata.org/) and leverages general Google search. By integrating these resources with LLMs, our approach overcomes the limitations associated with imprecise language and delivers more reliable and accurate information in the critical domain of climate change. This work paves the way for future advancements in LLMs and their application in domains where precision is of paramount importance.
Towards Climate Awareness in NLP Research
May 16, 2022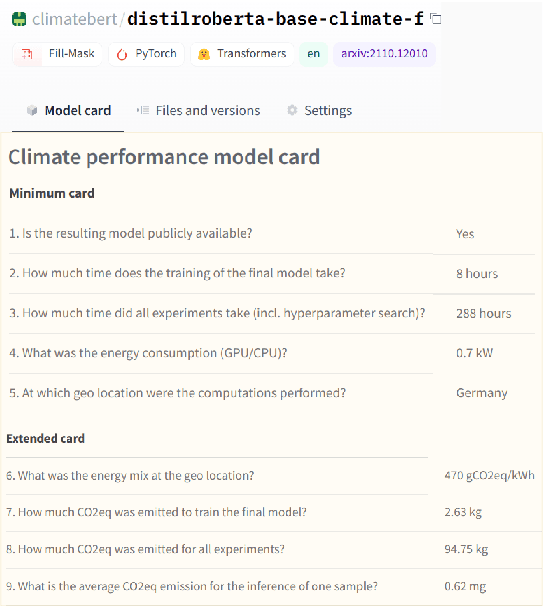

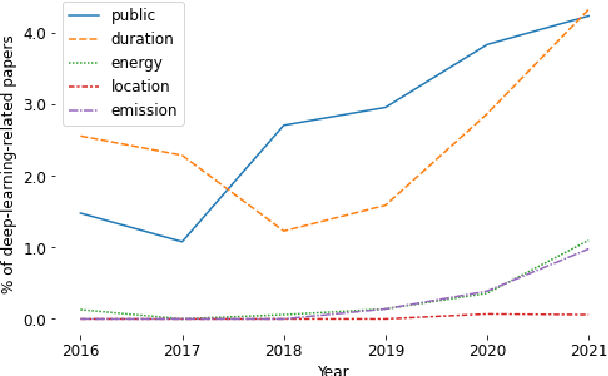

The climate impact of AI, and NLP research in particular, has become a serious issue given the enormous amount of energy that is increasingly being used for training and running computational models. Consequently, increasing focus is placed on efficient NLP. However, this important initiative lacks simple guidelines that would allow for systematic climate reporting of NLP research. We argue that this deficiency is one of the reasons why very few publications in NLP report key figures that would allow a more thorough examination of environmental impact. As a remedy, we propose a climate performance model card with the primary purpose of being practically usable with only limited information about experiments and the underlying computer hardware. We describe why this step is essential to increase awareness about the environmental impact of NLP research and, thereby, paving the way for more thorough discussions.
ClimateBert: A Pretrained Language Model for Climate-Related Text
Oct 22, 2021
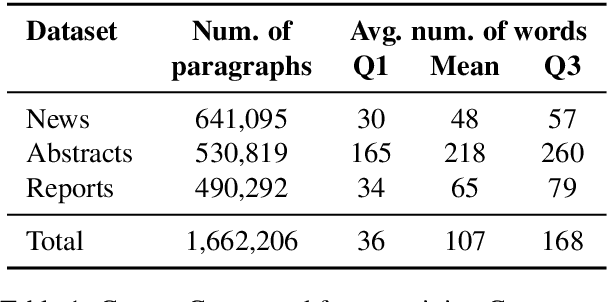
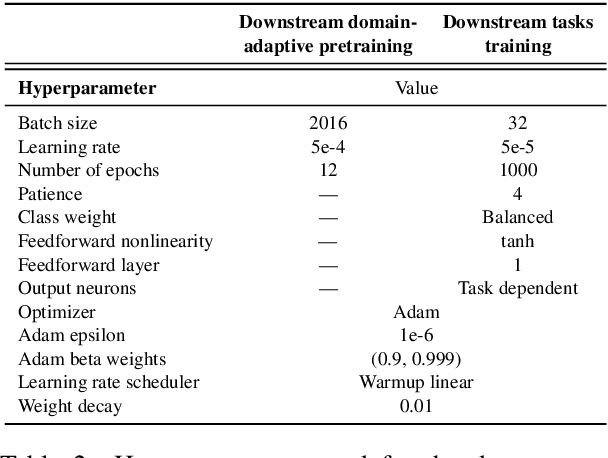

Over the recent years, large pretrained language models (LM) have revolutionized the field of natural language processing (NLP). However, while pretraining on general language has been shown to work very well for common language, it has been observed that niche language poses problems. In particular, climate-related texts include specific language that common LMs can not represent accurately. We argue that this shortcoming of today's LMs limits the applicability of modern NLP to the broad field of text processing of climate-related texts. As a remedy, we propose ClimateBert, a transformer-based language model that is further pretrained on over 1.6 million paragraphs of climate-related texts, crawled from various sources such as common news, research articles, and climate reporting of companies. We find that ClimateBertleads to a 46% improvement on a masked language model objective which, in turn, leads to lowering error rates by 3.57% to 35.71% for various climate-related downstream tasks like text classification, sentiment analysis, and fact-checking.