 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepdfQA: Diverse, Challenging, and Realistic Question Answering over PDFs
Jan 06, 2026PDFs are the second-most used document type on the internet (after HTML). Yet, existing QA datasets commonly start from text sources or only address specific domains. In this paper, we present pdfQA, a multi-domain 2K human-annotated (real-pdfQA) and 2K synthetic dataset (syn-pdfQA) differentiating QA pairs in ten complexity dimensions (e.g., file type, source modality, source position, answer type). We apply and evaluate quality and difficulty filters on both datasets, obtaining valid and challenging QA pairs. We answer the questions with open-source LLMs, revealing existing challenges that correlate with our complexity dimensions. pdfQA presents a basis for end-to-end QA pipeline evaluation, testing diverse skill sets and local optimizations (e.g., in information retrieval or parsing).
DIRAS: Efficient LLM-Assisted Annotation of Document Relevance in Retrieval Augmented Generation
Jun 20, 2024



Retrieval Augmented Generation (RAG) is widely employed to ground responses to queries on domain-specific documents. But do RAG implementations leave out important information or excessively include irrelevant information? To allay these concerns, it is necessary to annotate domain-specific benchmarks to evaluate information retrieval (IR) performance, as relevance definitions vary across queries and domains. Furthermore, such benchmarks should be cost-efficiently annotated to avoid annotation selection bias. In this paper, we propose DIRAS (Domain-specific Information Retrieval Annotation with Scalability), a manual-annotation-free schema that fine-tunes open-sourced LLMs to annotate relevance labels with calibrated relevance probabilities. Extensive evaluation shows that DIRAS fine-tuned models achieve GPT-4-level performance on annotating and ranking unseen (query, document) pairs, and is helpful for real-world RAG development.
ClimRetrieve: A Benchmarking Dataset for Information Retrieval from Corporate Climate Disclosures
Jun 14, 2024To handle the vast amounts of qualitative data produced in corporate climate communication, stakeholders increasingly rely on Retrieval Augmented Generation (RAG) systems. However, a significant gap remains in evaluating domain-specific information retrieval - the basis for answer generation. To address this challenge, this work simulates the typical tasks of a sustainability analyst by examining 30 sustainability reports with 16 detailed climate-related questions. As a result, we obtain a dataset with over 8.5K unique question-source-answer pairs labeled by different levels of relevance. Furthermore, we develop a use case with the dataset to investigate the integration of expert knowledge into information retrieval with embeddings. Although we show that incorporating expert knowledge works, we also outline the critical limitations of embeddings in knowledge-intensive downstream domains like climate change communication.
Towards Faithful and Robust LLM Specialists for Evidence-Based Question-Answering
Feb 26, 2024Advances towards more faithful and traceable answers of Large Language Models (LLMs) are crucial for various research and practical endeavors. One avenue in reaching this goal is basing the answers on reliable sources. However, this Evidence-Based QA has proven to work insufficiently with LLMs in terms of citing the correct sources (source quality) and truthfully representing the information within sources (answer attributability). In this work, we systematically investigate how to robustly fine-tune LLMs for better source quality and answer attributability. Specifically, we introduce a data generation pipeline with automated data quality filters, which can synthesize diversified high-quality training and testing data at scale. We further introduce four test sets to benchmark the robustness of fine-tuned specialist models. Extensive evaluation shows that fine-tuning on synthetic data improves performance on both in- and out-of-distribution. Furthermore, we show that data quality, which can be drastically improved by proposed quality filters, matters more than quantity in improving Evidence-Based QA.
Automated Fact-Checking of Climate Change Claims with Large Language Models
Jan 23, 2024This paper presents Climinator, a novel AI-based tool designed to automate the fact-checking of climate change claims. Utilizing an array of Large Language Models (LLMs) informed by authoritative sources like the IPCC reports and peer-reviewed scientific literature, Climinator employs an innovative Mediator-Advocate framework. This design allows Climinator to effectively synthesize varying scientific perspectives, leading to robust, evidence-based evaluations. Our model demonstrates remarkable accuracy when testing claims collected from Climate Feedback and Skeptical Science. Notably, when integrating an advocate with a climate science denial perspective in our framework, Climinator's iterative debate process reliably converges towards scientific consensus, underscoring its adeptness at reconciling diverse viewpoints into science-based, factual conclusions. While our research is subject to certain limitations and necessitates careful interpretation, our approach holds significant potential. We hope to stimulate further research and encourage exploring its applicability in other contexts, including political fact-checking and legal domains.
Exploring Nature: Datasets and Models for Analyzing Nature-Related Disclosures
Dec 28, 2023Nature is an amorphous concept. Yet, it is essential for the planet's well-being to understand how the economy interacts with it. To address the growing demand for information on corporate nature disclosure, we provide datasets and classifiers to detect nature communication by companies. We ground our approach in the guidelines of the Taskforce on Nature-related Financial Disclosures (TNFD). Particularly, we focus on the specific dimensions of water, forest, and biodiversity. For each dimension, we create an expert-annotated dataset with 2,200 text samples and train classifier models. Furthermore, we show that nature communication is more prevalent in hotspot areas and directly effected industries like agriculture and utilities. Our approach is the first to respond to calls to assess corporate nature communication on a large scale.
ClimateBERT-NetZero: Detecting and Assessing Net Zero and Reduction Targets
Oct 12, 2023



Public and private actors struggle to assess the vast amounts of information about sustainability commitments made by various institutions. To address this problem, we create a novel tool for automatically detecting corporate, national, and regional net zero and reduction targets in three steps. First, we introduce an expert-annotated data set with 3.5K text samples. Second, we train and release ClimateBERT-NetZero, a natural language classifier to detect whether a text contains a net zero or reduction target. Third, we showcase its analysis potential with two use cases: We first demonstrate how ClimateBERT-NetZero can be combined with conventional question-answering (Q&A) models to analyze the ambitions displayed in net zero and reduction targets. Furthermore, we employ the ClimateBERT-NetZero model on quarterly earning call transcripts and outline how communication patterns evolve over time. Our experiments demonstrate promising pathways for extracting and analyzing net zero and emission reduction targets at scale.
CHATREPORT: Democratizing Sustainability Disclosure Analysis through LLM-based Tools
Jul 28, 2023In the face of climate change, are companies really taking substantial steps toward more sustainable operations? A comprehensive answer lies in the dense, information-rich landscape of corporate sustainability reports. However, the sheer volume and complexity of these reports make human analysis very costly. Therefore, only a few entities worldwide have the resources to analyze these reports at scale, which leads to a lack of transparency in sustainability reporting. Empowering stakeholders with LLM-based automatic analysis tools can be a promising way to democratize sustainability report analysis. However, developing such tools is challenging due to (1) the hallucination of LLMs and (2) the inefficiency of bringing domain experts into the AI development loop. In this paper, we ChatReport, a novel LLM-based system to automate the analysis of corporate sustainability reports, addressing existing challenges by (1) making the answers traceable to reduce the harm of hallucination and (2) actively involving domain experts in the development loop. We make our methodology, annotated datasets, and generated analyses of 1015 reports publicly available.
Paradigm Shift in Sustainability Disclosure Analysis: Empowering Stakeholders with CHATREPORT, a Language Model-Based Tool
Jun 27, 2023This paper introduces a novel approach to enhance Large Language Models (LLMs) with expert knowledge to automate the analysis of corporate sustainability reports by benchmarking them against the Task Force for Climate-Related Financial Disclosures (TCFD) recommendations. Corporate sustainability reports are crucial in assessing organizations' environmental and social risks and impacts. However, analyzing these reports' vast amounts of information makes human analysis often too costly. As a result, only a few entities worldwide have the resources to analyze these reports, which could lead to a lack of transparency. While AI-powered tools can automatically analyze the data, they are prone to inaccuracies as they lack domain-specific expertise. This paper introduces a novel approach to enhance LLMs with expert knowledge to automate the analysis of corporate sustainability reports. We christen our tool CHATREPORT, and apply it in a first use case to assess corporate climate risk disclosures following the TCFD recommendations. CHATREPORT results from collaborating with experts in climate science, finance, economic policy, and computer science, demonstrating how domain experts can be involved in developing AI tools. We make our prompt templates, generated data, and scores available to the public to encourage transparency.
chatClimate: Grounding Conversational AI in Climate Science
Apr 28, 2023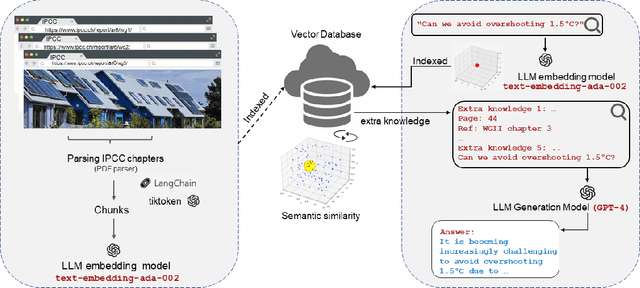
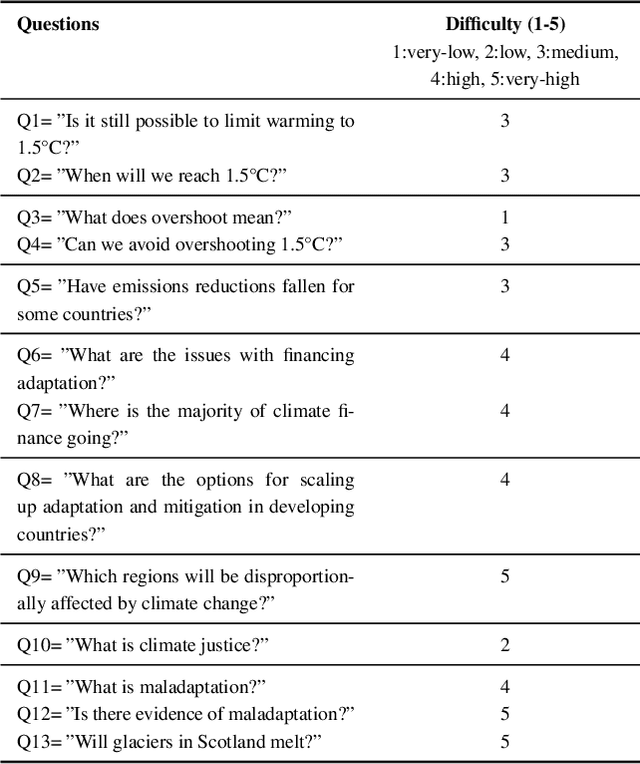


Large Language Models (LLMs) have made significant progress in recent years, achieving remarkable results in question-answering tasks (QA). However, they still face two major challenges: hallucination and outdated information after the training phase. These challenges take center stage in critical domains like climate change, where obtaining accurate and up-to-date information from reliable sources in a limited time is essential and difficult. To overcome these barriers, one potential solution is to provide LLMs with access to external, scientifically accurate, and robust sources (long-term memory) to continuously update their knowledge and prevent the propagation of inaccurate, incorrect, or outdated information. In this study, we enhanced GPT-4 by integrating the information from the Sixth Assessment Report of the Intergovernmental (IPCC AR6), the most comprehensive, up-to-date, and reliable source in this domain. We present our conversational AI prototype, available at www.chatclimate.ai and demonstrate its ability to answer challenging questions accurately in three different QA scenarios: asking from 1) GPT-4, 2) chatClimate, and 3) hybrid chatClimate. The answers and their sources were evaluated by our team of IPCC authors, who used their expert knowledge to score the accuracy of the answers from 1 (very-low) to 5 (very-high). The evaluation showed that the hybrid chatClimate provided more accurate answers, highlighting the effectiveness of our solution. This approach can be easily scaled for chatbots in specific domains, enabling the delivery of reliable and accurate information.