 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Do Language Models Endorse Limitations on Human Rights Principles?
Mar 04, 2026As Large Language Models (LLMs) increasingly mediate global information access with the potential to shape public discourse, their alignment with universal human rights principles becomes important to ensure that these rights are abided by in high stakes AI-mediated interactions. In this paper, we evaluate how LLMs navigate trade-offs involving the Universal Declaration of Human Rights (UDHR), leveraging 1,152 synthetically generated scenarios across 24 rights articles and eight languages. Our analysis of eleven major LLMs reveals systematic biases where models: (1) accept limiting Economic, Social, and Cultural rights more often than Political and Civil rights, (2) demonstrate significant cross-linguistic variation with elevated endorsement rates of rights-limiting actions in Chinese and Hindi compared to English or Romanian, (3) show substantial susceptibility to prompt-based steering, and (4) exhibit noticeable differences between Likert and open-ended responses, highlighting critical challenges in LLM preference assessment.
Do LLMs Understand Wine Descriptors Across Cultures? A Benchmark for Cultural Adaptations of Wine Reviews
Sep 16, 2025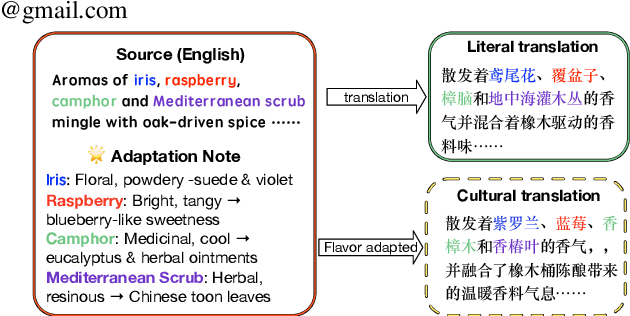
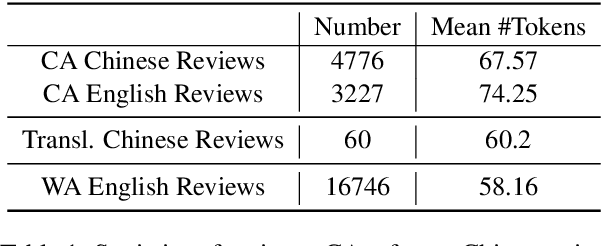
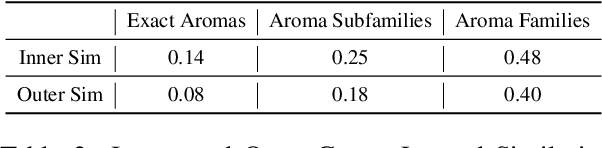
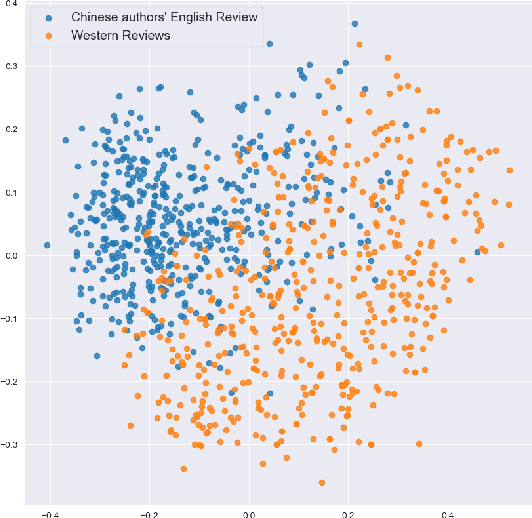
Recent advances in large language models (LLMs) have opened the door to culture-aware language tasks. We introduce the novel problem of adapting wine reviews across Chinese and English, which goes beyond literal translation by incorporating regional taste preferences and culture-specific flavor descriptors. In a case study on cross-cultural wine review adaptation, we compile the first parallel corpus of professional reviews, containing 8k Chinese and 16k Anglophone reviews. We benchmark both neural-machine-translation baselines and state-of-the-art LLMs with automatic metrics and human evaluation. For the latter, we propose three culture-oriented criteria -- Cultural Proximity, Cultural Neutrality, and Cultural Genuineness -- to assess how naturally a translated review resonates with target-culture readers. Our analysis shows that current models struggle to capture cultural nuances, especially in translating wine descriptions across different cultures. This highlights the challenges and limitations of translation models in handling cultural content.
Beyond Demographics: Enhancing Cultural Value Survey Simulation with Multi-Stage Personality-Driven Cognitive Reasoning
Aug 25, 2025



Introducing MARK, the Multi-stAge Reasoning frameworK for cultural value survey response simulation, designed to enhance the accuracy, steerability, and interpretability of large language models in this task. The system is inspired by the type dynamics theory in the MBTI psychological framework for personality research. It effectively predicts and utilizes human demographic information for simulation: life-situational stress analysis, group-level personality prediction, and self-weighted cognitive imitation. Experiments on the World Values Survey show that MARK outperforms existing baselines by 10% accuracy and reduces the divergence between model predictions and human preferences. This highlights the potential of our framework to improve zero-shot personalization and help social scientists interpret model predictions.
HapticLLaMA: A Multimodal Sensory Language Model for Haptic Captioning
Aug 08, 2025Haptic captioning is the task of generating natural language descriptions from haptic signals, such as vibrations, for use in virtual reality, accessibility, and rehabilitation applications. While previous multimodal research has focused primarily on vision and audio, haptic signals for the sense of touch remain underexplored. To address this gap, we formalize the haptic captioning task and propose HapticLLaMA, a multimodal sensory language model that interprets vibration signals into descriptions in a given sensory, emotional, or associative category. We investigate two types of haptic tokenizers, a frequency-based tokenizer and an EnCodec-based tokenizer, that convert haptic signals into sequences of discrete units, enabling their integration with the LLaMA model. HapticLLaMA is trained in two stages: (1) supervised fine-tuning using the LLaMA architecture with LoRA-based adaptation, and (2) fine-tuning via reinforcement learning from human feedback (RLHF). We assess HapticLLaMA's captioning performance using both automated n-gram metrics and human evaluation. HapticLLaMA demonstrates strong capability in interpreting haptic vibration signals, achieving a METEOR score of 59.98 and a BLEU-4 score of 32.06 respectively. Additionally, over 61% of the generated captions received human ratings above 3.5 on a 7-point scale, with RLHF yielding a 10% improvement in the overall rating distribution, indicating stronger alignment with human haptic perception. These findings highlight the potential of large language models to process and adapt to sensory data.
Culinary Crossroads: A RAG Framework for Enhancing Diversity in Cross-Cultural Recipe Adaptation
Jul 29, 2025In cross-cultural recipe adaptation, the goal is not only to ensure cultural appropriateness and retain the original dish's essence, but also to provide diverse options for various dietary needs and preferences. Retrieval Augmented Generation (RAG) is a promising approach, combining the retrieval of real recipes from the target cuisine for cultural adaptability with large language models (LLMs) for relevance. However, it remains unclear whether RAG can generate diverse adaptation results. Our analysis shows that RAG tends to overly rely on a limited portion of the context across generations, failing to produce diverse outputs even when provided with varied contextual inputs. This reveals a key limitation of RAG in creative tasks with multiple valid answers: it fails to leverage contextual diversity for generating varied responses. To address this issue, we propose CARRIAGE, a plug-and-play RAG framework for cross-cultural recipe adaptation that enhances diversity in both retrieval and context organization. To our knowledge, this is the first RAG framework that explicitly aims to generate highly diverse outputs to accommodate multiple user preferences. Our experiments show that CARRIAGE achieves Pareto efficiency in terms of diversity and quality of recipe adaptation compared to closed-book LLMs.
HapticCap: A Multimodal Dataset and Task for Understanding User Experience of Vibration Haptic Signals
Jul 17, 2025Haptic signals, from smartphone vibrations to virtual reality touch feedback, can effectively convey information and enhance realism, but designing signals that resonate meaningfully with users is challenging. To facilitate this, we introduce a multimodal dataset and task, of matching user descriptions to vibration haptic signals, and highlight two primary challenges: (1) lack of large haptic vibration datasets annotated with textual descriptions as collecting haptic descriptions is time-consuming, and (2) limited capability of existing tasks and models to describe vibration signals in text. To advance this area, we create HapticCap, the first fully human-annotated haptic-captioned dataset, containing 92,070 haptic-text pairs for user descriptions of sensory, emotional, and associative attributes of vibrations. Based on HapticCap, we propose the haptic-caption retrieval task and present the results of this task from a supervised contrastive learning framework that brings together text representations within specific categories and vibrations. Overall, the combination of language model T5 and audio model AST yields the best performance in the haptic-caption retrieval task, especially when separately trained for each description category.
Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory
May 28, 2025Modern vision-language models (VLMs) often fail at cultural competency evaluations and benchmarks. Given the diversity of applications built upon VLMs, there is renewed interest in understanding how they encode cultural nuances. While individual aspects of this problem have been studied, we still lack a comprehensive framework for systematically identifying and annotating the nuanced cultural dimensions present in images for VLMs. This position paper argues that foundational methodologies from visual culture studies (cultural studies, semiotics, and visual studies) are necessary for cultural analysis of images. Building upon this review, we propose a set of five frameworks, corresponding to cultural dimensions, that must be considered for a more complete analysis of the cultural competencies of VLMs.
RAVENEA: A Benchmark for Multimodal Retrieval-Augmented Visual Culture Understanding
May 20, 2025As vision-language models (VLMs) become increasingly integrated into daily life, the need for accurate visual culture understanding is becoming critical. Yet, these models frequently fall short in interpreting cultural nuances effectively. Prior work has demonstrated the effectiveness of retrieval-augmented generation (RAG) in enhancing cultural understanding in text-only settings, while its application in multimodal scenarios remains underexplored. To bridge this gap, we introduce RAVENEA (Retrieval-Augmented Visual culturE uNdErstAnding), a new benchmark designed to advance visual culture understanding through retrieval, focusing on two tasks: culture-focused visual question answering (cVQA) and culture-informed image captioning (cIC). RAVENEA extends existing datasets by integrating over 10,000 Wikipedia documents curated and ranked by human annotators. With RAVENEA, we train and evaluate seven multimodal retrievers for each image query, and measure the downstream impact of retrieval-augmented inputs across fourteen state-of-the-art VLMs. Our results show that lightweight VLMs, when augmented with culture-aware retrieval, outperform their non-augmented counterparts (by at least 3.2% absolute on cVQA and 6.2% absolute on cIC). This highlights the value of retrieval-augmented methods and culturally inclusive benchmarks for multimodal understanding.
Evaluating Multimodal Language Models as Visual Assistants for Visually Impaired Users
Mar 28, 2025This paper explores the effectiveness of Multimodal Large Language models (MLLMs) as assistive technologies for visually impaired individuals. We conduct a user survey to identify adoption patterns and key challenges users face with such technologies. Despite a high adoption rate of these models, our findings highlight concerns related to contextual understanding, cultural sensitivity, and complex scene understanding, particularly for individuals who may rely solely on them for visual interpretation. Informed by these results, we collate five user-centred tasks with image and video inputs, including a novel task on Optical Braille Recognition. Our systematic evaluation of twelve MLLMs reveals that further advancements are necessary to overcome limitations related to cultural context, multilingual support, Braille reading comprehension, assistive object recognition, and hallucinations. This work provides critical insights into the future direction of multimodal AI for accessibility, underscoring the need for more inclusive, robust, and trustworthy visual assistance technologies.
Beyond Words: Exploring Cultural Value Sensitivity in Multimodal Models
Feb 18, 2025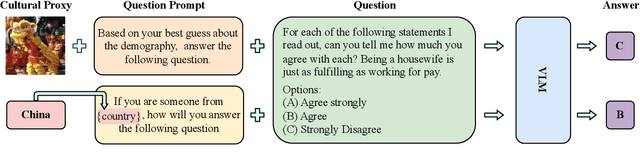


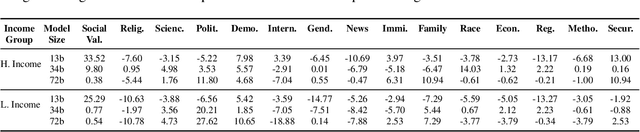
Investigating value alignment in Large Language Models (LLMs) based on cultural context has become a critical area of research. However, similar biases have not been extensively explored in large vision-language models (VLMs). As the scale of multimodal models continues to grow, it becomes increasingly important to assess whether images can serve as reliable proxies for culture and how these values are embedded through the integration of both visual and textual data. In this paper, we conduct a thorough evaluation of multimodal model at different scales, focusing on their alignment with cultural values. Our findings reveal that, much like LLMs, VLMs exhibit sensitivity to cultural values, but their performance in aligning with these values is highly context-dependent. While VLMs show potential in improving value understanding through the use of images, this alignment varies significantly across contexts highlighting the complexities and underexplored challenges in the alignment of multimodal models.