 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealist and Pluralist Conceptions of Intelligence and Their Implications on AI Research
Nov 19, 2025In this paper, we argue that current AI research operates on a spectrum between two different underlying conceptions of intelligence: Intelligence Realism, which holds that intelligence represents a single, universal capacity measurable across all systems, and Intelligence Pluralism, which views intelligence as diverse, context-dependent capacities that cannot be reduced to a single universal measure. Through an analysis of current debates in AI research, we demonstrate how the conceptions remain largely implicit yet fundamentally shape how empirical evidence gets interpreted across a wide range of areas. These underlying views generate fundamentally different research approaches across three areas. Methodologically, they produce different approaches to model selection, benchmark design, and experimental validation. Interpretively, they lead to contradictory readings of the same empirical phenomena, from capability emergence to system limitations. Regarding AI risk, they generate categorically different assessments: realists view superintelligence as the primary risk and search for unified alignment solutions, while pluralists see diverse threats across different domains requiring context-specific solutions. We argue that making explicit these underlying assumptions can contribute to a clearer understanding of disagreements in AI research.
On the Measure of a Model: From Intelligence to Generality
Nov 14, 2025Benchmarks such as ARC, Raven-inspired tests, and the Blackbird Task are widely used to evaluate the intelligence of large language models (LLMs). Yet, the concept of intelligence remains elusive- lacking a stable definition and failing to predict performance on practical tasks such as question answering, summarization, or coding. Optimizing for such benchmarks risks misaligning evaluation with real-world utility. Our perspective is that evaluation should be grounded in generality rather than abstract notions of intelligence. We identify three assumptions that often underpin intelligence-focused evaluation: generality, stability, and realism. Through conceptual and formal analysis, we show that only generality withstands conceptual and empirical scrutiny. Intelligence is not what enables generality; generality is best understood as a multitask learning problem that directly links evaluation to measurable performance breadth and reliability. This perspective reframes how progress in AI should be assessed and proposes generality as a more stable foundation for evaluating capability across diverse and evolving tasks.
Mechanistic Interpretability Needs Philosophy
Jun 23, 2025
Mechanistic interpretability (MI) aims to explain how neural networks work by uncovering their underlying causal mechanisms. As the field grows in influence, it is increasingly important to examine not just models themselves, but the assumptions, concepts and explanatory strategies implicit in MI research. We argue that mechanistic interpretability needs philosophy: not as an afterthought, but as an ongoing partner in clarifying its concepts, refining its methods, and assessing the epistemic and ethical stakes of interpreting AI systems. Taking three open problems from the MI literature as examples, this position paper illustrates the value philosophy can add to MI research, and outlines a path toward deeper interdisciplinary dialogue.
Evaluating Multimodal Language Models as Visual Assistants for Visually Impaired Users
Mar 28, 2025This paper explores the effectiveness of Multimodal Large Language models (MLLMs) as assistive technologies for visually impaired individuals. We conduct a user survey to identify adoption patterns and key challenges users face with such technologies. Despite a high adoption rate of these models, our findings highlight concerns related to contextual understanding, cultural sensitivity, and complex scene understanding, particularly for individuals who may rely solely on them for visual interpretation. Informed by these results, we collate five user-centred tasks with image and video inputs, including a novel task on Optical Braille Recognition. Our systematic evaluation of twelve MLLMs reveals that further advancements are necessary to overcome limitations related to cultural context, multilingual support, Braille reading comprehension, assistive object recognition, and hallucinations. This work provides critical insights into the future direction of multimodal AI for accessibility, underscoring the need for more inclusive, robust, and trustworthy visual assistance technologies.
Defining Knowledge: Bridging Epistemology and Large Language Models
Oct 03, 2024

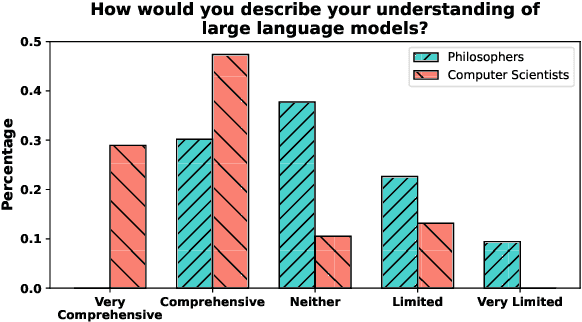

Knowledge claims are abundant in the literature on large language models (LLMs); but can we say that GPT-4 truly "knows" the Earth is round? To address this question, we review standard definitions of knowledge in epistemology and we formalize interpretations applicable to LLMs. In doing so, we identify inconsistencies and gaps in how current NLP research conceptualizes knowledge with respect to epistemological frameworks. Additionally, we conduct a survey of 100 professional philosophers and computer scientists to compare their preferences in knowledge definitions and their views on whether LLMs can really be said to know. Finally, we suggest evaluation protocols for testing knowledge in accordance to the most relevant definitions.
From Words to Worlds: Compositionality for Cognitive Architectures
Jul 18, 2024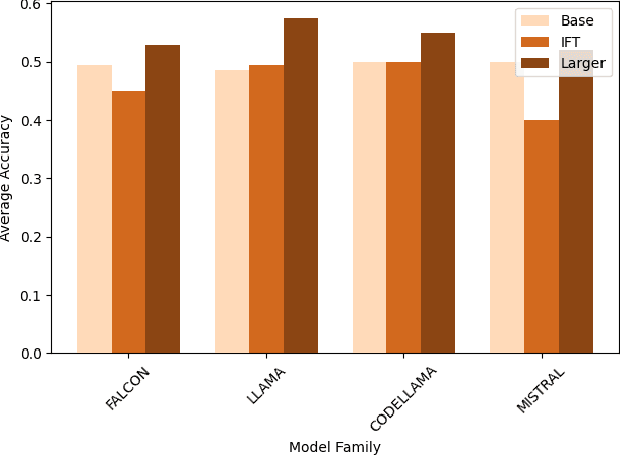
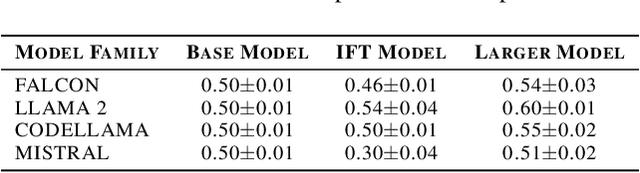
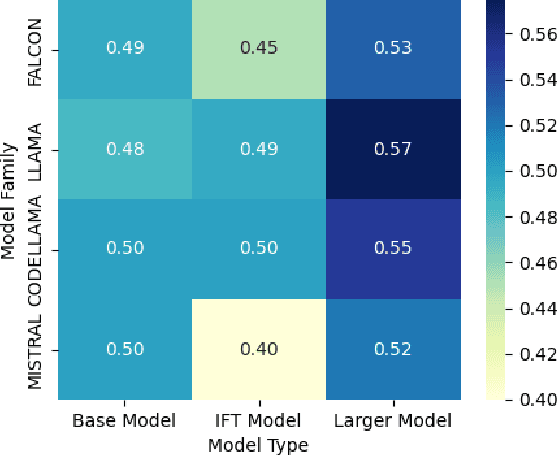
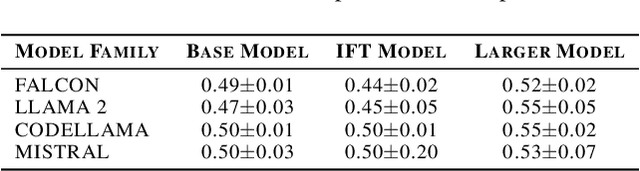
Large language models (LLMs) are very performant connectionist systems, but do they exhibit more compositionality? More importantly, is that part of why they perform so well? We present empirical analyses across four LLM families (12 models) and three task categories, including a novel task introduced below. Our findings reveal a nuanced relationship in learning of compositional strategies by LLMs -- while scaling enhances compositional abilities, instruction tuning often has a reverse effect. Such disparity brings forth some open issues regarding the development and improvement of large language models in alignment with human cognitive capacities.