Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Words to Worlds: Compositionality for Cognitive Architectures
Paper and Code
Jul 18, 2024
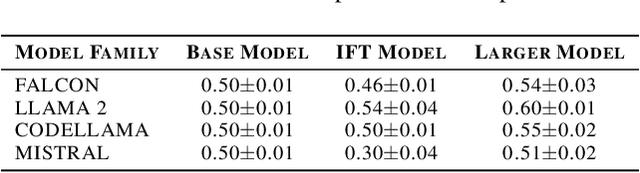
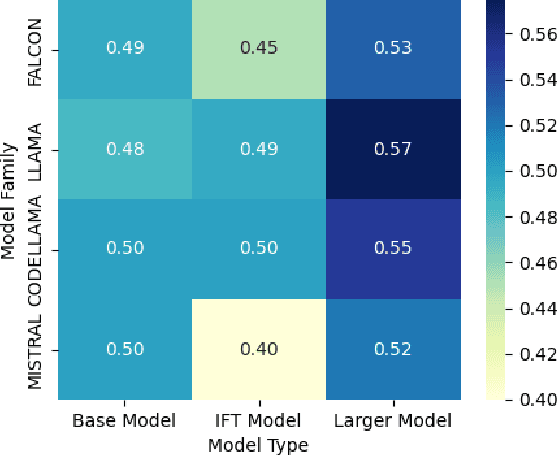
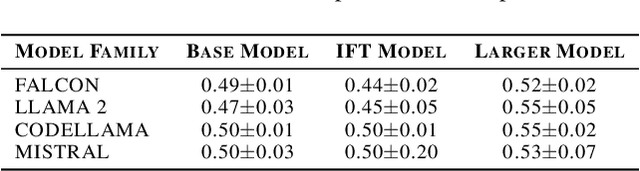
Large language models (LLMs) are very performant connectionist systems, but do they exhibit more compositionality? More importantly, is that part of why they perform so well? We present empirical analyses across four LLM families (12 models) and three task categories, including a novel task introduced below. Our findings reveal a nuanced relationship in learning of compositional strategies by LLMs -- while scaling enhances compositional abilities, instruction tuning often has a reverse effect. Such disparity brings forth some open issues regarding the development and improvement of large language models in alignment with human cognitive capacities.
* Accepted to ICML 2024 Workshop on LLMs & Cognition
View paper on