 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining Knowledge: Bridging Epistemology and Large Language Models
Oct 03, 2024

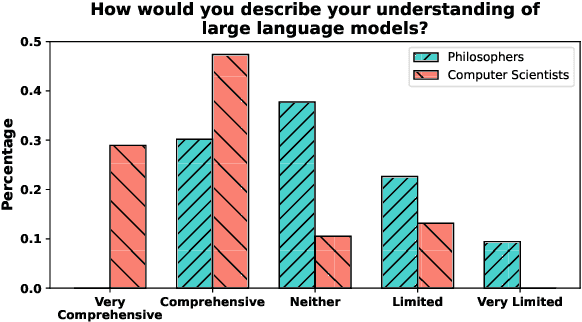

Knowledge claims are abundant in the literature on large language models (LLMs); but can we say that GPT-4 truly "knows" the Earth is round? To address this question, we review standard definitions of knowledge in epistemology and we formalize interpretations applicable to LLMs. In doing so, we identify inconsistencies and gaps in how current NLP research conceptualizes knowledge with respect to epistemological frameworks. Additionally, we conduct a survey of 100 professional philosophers and computer scientists to compare their preferences in knowledge definitions and their views on whether LLMs can really be said to know. Finally, we suggest evaluation protocols for testing knowledge in accordance to the most relevant definitions.
Does Mapo Tofu Contain Coffee? Probing LLMs for Food-related Cultural Knowledge
Apr 10, 2024



Recent studies have highlighted the presence of cultural biases in Large Language Models (LLMs), yet often lack a robust methodology to dissect these phenomena comprehensively. Our work aims to bridge this gap by delving into the Food domain, a universally relevant yet culturally diverse aspect of human life. We introduce FmLAMA, a multilingual dataset centered on food-related cultural facts and variations in food practices. We analyze LLMs across various architectures and configurations, evaluating their performance in both monolingual and multilingual settings. By leveraging templates in six different languages, we investigate how LLMs interact with language-specific and cultural knowledge. Our findings reveal that (1) LLMs demonstrate a pronounced bias towards food knowledge prevalent in the United States; (2) Incorporating relevant cultural context significantly improves LLMs' ability to access cultural knowledge; (3) The efficacy of LLMs in capturing cultural nuances is highly dependent on the interplay between the probing language, the specific model architecture, and the cultural context in question. This research underscores the complexity of integrating cultural understanding into LLMs and emphasizes the importance of culturally diverse datasets to mitigate biases and enhance model performance across different cultural domains.
MuLan: A Study of Fact Mutability in Language Models
Apr 03, 2024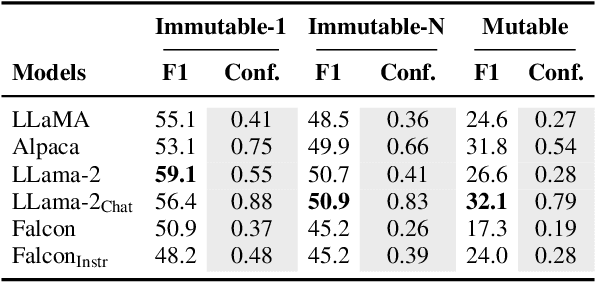
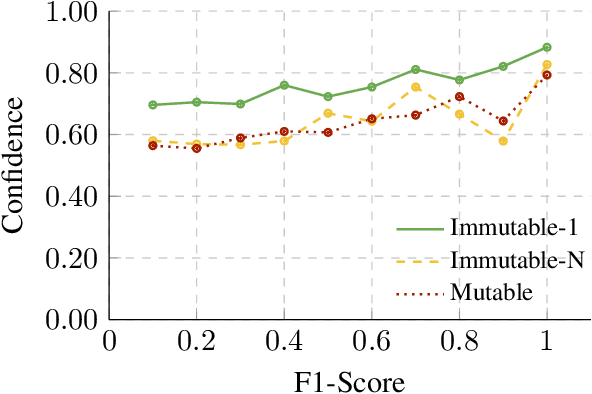
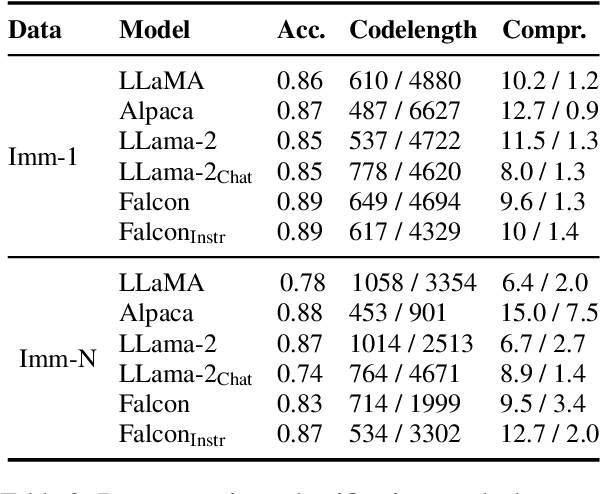
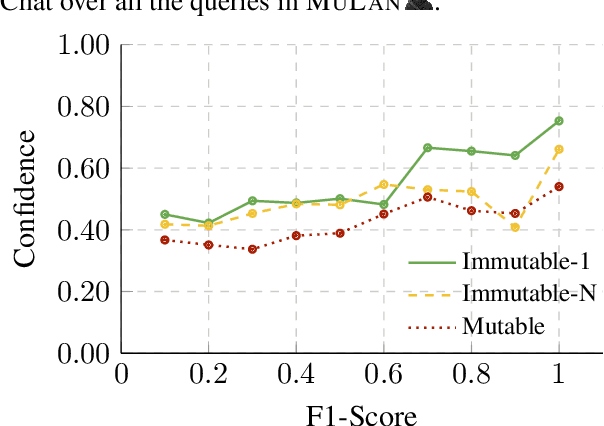
Facts are subject to contingencies and can be true or false in different circumstances. One such contingency is time, wherein some facts mutate over a given period, e.g., the president of a country or the winner of a championship. Trustworthy language models ideally identify mutable facts as such and process them accordingly. We create MuLan, a benchmark for evaluating the ability of English language models to anticipate time-contingency, covering both 1:1 and 1:N relations. We hypothesize that mutable facts are encoded differently than immutable ones, hence being easier to update. In a detailed evaluation of six popular large language models, we consistently find differences in the LLMs' confidence, representations, and update behavior, depending on the mutability of a fact. Our findings should inform future work on the injection of and induction of time-contingent knowledge to/from LLMs.
Word Order and World Knowledge
Mar 01, 2024



Word order is an important concept in natural language, and in this work, we study how word order affects the induction of world knowledge from raw text using language models. We use word analogies to probe for such knowledge. Specifically, in addition to the natural word order, we first respectively extract texts of six fixed word orders from five languages and then pretrain the language models on these texts. Finally, we analyze the experimental results of the fixed word orders on word analogies and show that i) certain fixed word orders consistently outperform or underperform others, though the specifics vary across languages, and ii) the Wov2Lex hypothesis is not hold in pre-trained language models, and the natural word order typically yields mediocre results. The source code will be made publicly available at https://github.com/lshowway/probing_by_analogy.
LeXFiles and LegalLAMA: Facilitating English Multinational Legal Language Model Development
May 22, 2023



In this work, we conduct a detailed analysis on the performance of legal-oriented pre-trained language models (PLMs). We examine the interplay between their original objective, acquired knowledge, and legal language understanding capacities which we define as the upstream, probing, and downstream performance, respectively. We consider not only the models' size but also the pre-training corpora used as important dimensions in our study. To this end, we release a multinational English legal corpus (LeXFiles) and a legal knowledge probing benchmark (LegalLAMA) to facilitate training and detailed analysis of legal-oriented PLMs. We release two new legal PLMs trained on LeXFiles and evaluate them alongside others on LegalLAMA and LexGLUE. We find that probing performance strongly correlates with upstream performance in related legal topics. On the other hand, downstream performance is mainly driven by the model's size and prior legal knowledge which can be estimated by upstream and probing performance. Based on these findings, we can conclude that both dimensions are important for those seeking the development of domain-specific PLMs.
Beer2Vec : Extracting Flavors from Reviews for Thirst-Quenching Recommandations
Aug 04, 2022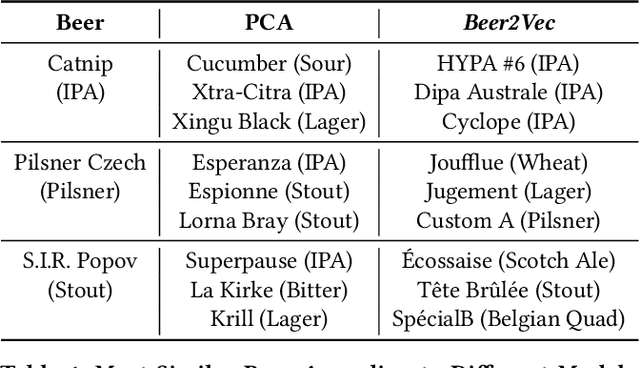
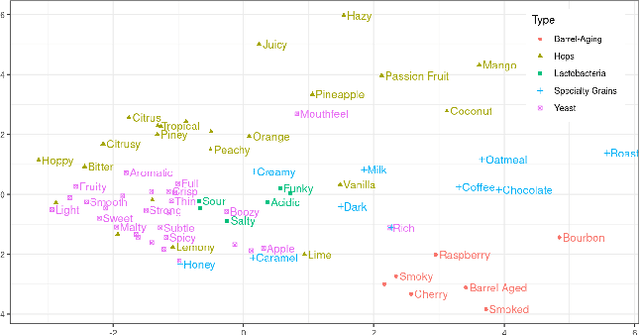
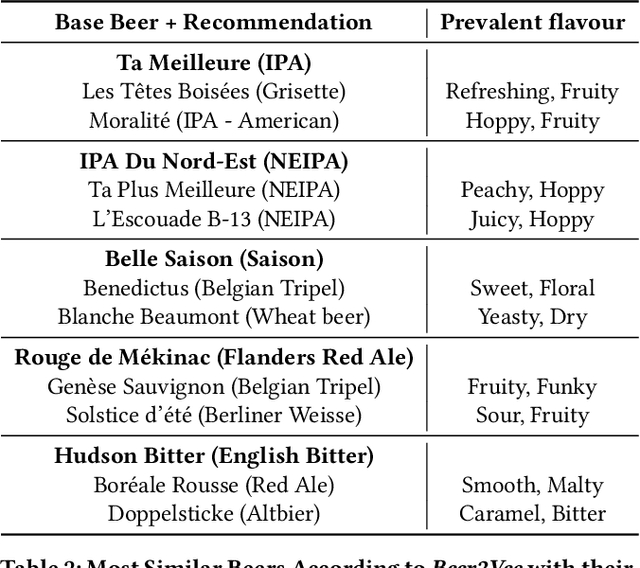
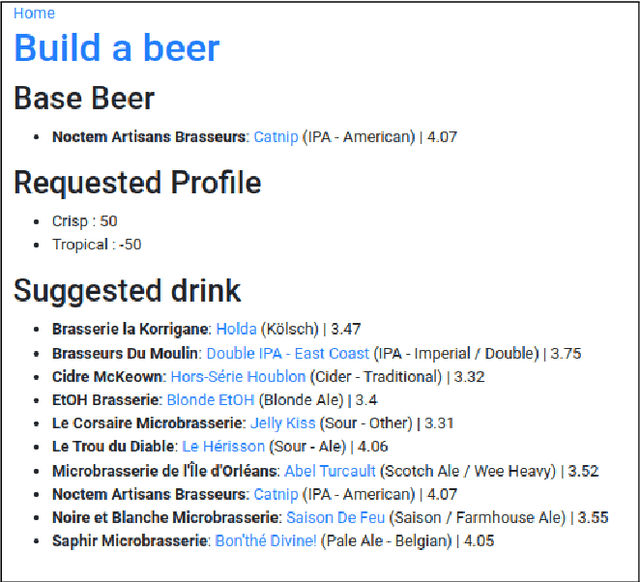
This paper introduces the Beer2Vec model that allows the most popular alcoholic beverage in the world to be encoded into vectors enabling flavorful recommendations. We present our algorithm using a unique dataset focused on the analysis of craft beers. We thoroughly explain how we encode the flavors and how useful, from an empirical point of view, the beer vectors are to generate meaningful recommendations. We also present three different ways to use Beer2Vec in a real-world environment to enlighten the pool of craft beer consumers. Finally, we make our model and functionalities available to everybody through a web application.
Generating Intelligible Plumitifs Descriptions: Use Case Application with Ethical Considerations
Nov 24, 2020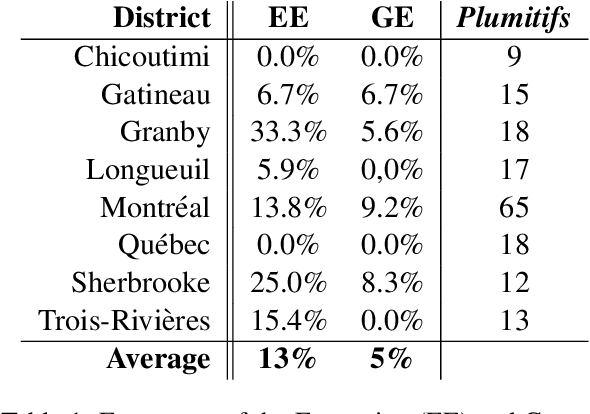
Plumitifs (dockets) were initially a tool for law clerks. Nowadays, they are used as summaries presenting all the steps of a judicial case. Information concerning parties' identity, jurisdiction in charge of administering the case, and some information relating to the nature and the course of the preceding are available through plumitifs. They are publicly accessible but barely understandable; they are written using abbreviations and referring to provisions from the Criminal Code of Canada, which makes them hard to reason about. In this paper, we propose a simple yet efficient multi-source language generation architecture that leverages both the plumitif and the Criminal Code's content to generate intelligible plumitifs descriptions. It goes without saying that ethical considerations rise with these sensitive documents made readable and available at scale, legitimate concerns that we address in this paper.
Attending Form and Context to Generate Specialized Out-of-VocabularyWords Representations
Dec 14, 2019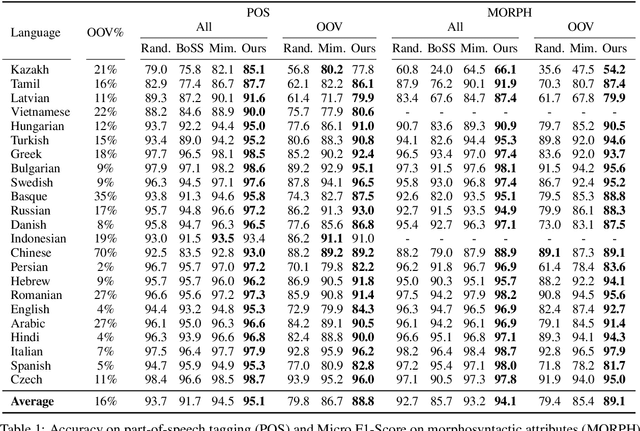
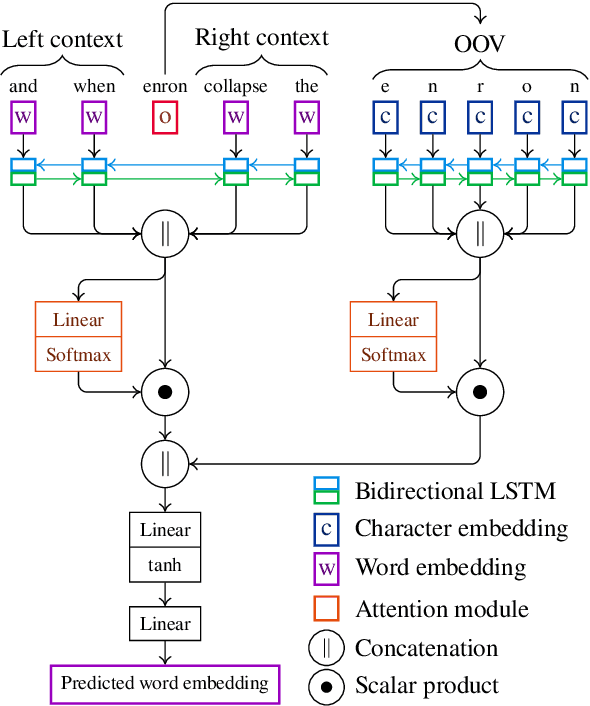
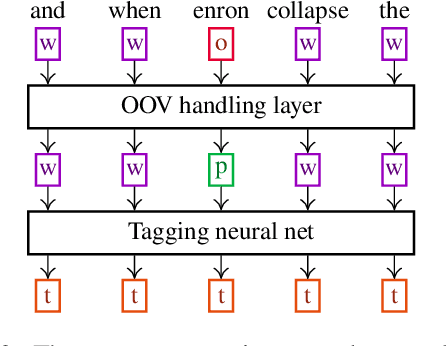

We propose a new contextual-compositional neural network layer that handles out-of-vocabulary (OOV) words in natural language processing (NLP) tagging tasks. This layer consists of a model that attends to both the character sequence and the context in which the OOV words appear. We show that our model learns to generate task-specific \textit{and} sentence-dependent OOV word representations without the need for pre-training on an embedding table, unlike previous attempts. We insert our layer in the state-of-the-art tagging model of \citet{plank2016multilingual} and thoroughly evaluate its contribution on 23 different languages on the task of jointly tagging part-of-speech and morphosyntactic attributes. Our OOV handling method successfully improves performances of this model on every language but one to achieve a new state-of-the-art on the Universal Dependencies Dataset 1.4.
A Robust Self-Learning Method for Fully Unsupervised Cross-Lingual Mappings of Word Embeddings: Making the Method Robustly Reproducible as Well
Dec 03, 2019


In this paper, we reproduce the experiments of Artetxe et al. (2018b) regarding the robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings. We show that the reproduction of their method is indeed feasible with some minor assumptions. We further investigate the robustness of their model by introducing four new languages that are less similar to English than the ones proposed by the original paper. In order to assess the stability of their model, we also conduct a grid search over sensible hyperparameters. We then propose key recommendations applicable to any research project in order to deliver fully reproducible research.
Predicting and interpreting embeddings for out of vocabulary words in downstream tasks
Mar 02, 2019
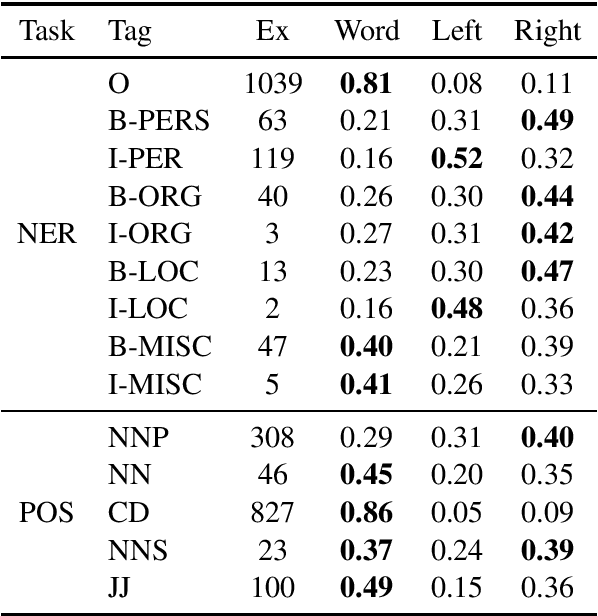

We propose a novel way to handle out of vocabulary (OOV) words in downstream natural language processing (NLP) tasks. We implement a network that predicts useful embeddings for OOV words based on their morphology and on the context in which they appear. Our model also incorporates an attention mechanism indicating the focus allocated to the left context words, the right context words or the word's characters, hence making the prediction more interpretable. The model is a ``drop-in'' module that is jointly trained with the downstream task's neural network, thus producing embeddings specialized for the task at hand. When the task is mostly syntactical, we observe that our model aims most of its attention on surface form characters. On the other hand, for tasks more semantical, the network allocates more attention to the surrounding words. In all our tests, the module helps the network to achieve better performances in comparison to the use of simple random embeddings.
* 2 pages, 0 figures, 2 tables