 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Large Language Models for Quebec Insurance: From Closed-Book to Retrieval-Augmented Generation
Mar 08, 2026The digitization of insurance distribution in the Canadian province of Quebec, accelerated by legislative changes such as Bill 141, has created a significant "advice gap", leaving consumers to interpret complex financial contracts without professional guidance. While Large Language Models (LLMs) offer a scalable solution for automated advisory services, their deployment in high-stakes domains hinges on strict legal accuracy and trustworthiness. In this paper, we address this challenge by introducing AEPC-QA, a private gold-standard benchmark of 807 multiple-choice questions derived from official regulatory certification (paper) handbooks. We conduct a comprehensive evaluation of 51 LLMs across two paradigms: closed-book generation and retrieval-augmented generation (RAG) using a specialized corpus of Quebec insurance documents. Our results reveal three critical insights: 1) the supremacy of inference-time reasoning, where models leveraging chain-of-thought processing (e.g. o3-2025-04-16, o1-2024-12-17) significantly outperform standard instruction-tuned models; 2) RAG acts as a knowledge equalizer, boosting the accuracy of models with weak parametric knowledge by over 35 percentage points, yet paradoxically causing "context distraction" in others, leading to catastrophic performance regressions; and 3) a "specialization paradox", where massive generalist models consistently outperform smaller, domain-specific French fine-tuned ones. These findings suggest that while current architectures approach expert-level proficiency (~79%), the instability introduced by external context retrieval necessitates rigorous robustness calibration before autonomous deployment is viable.
COLE: a Comprehensive Benchmark for French Language Understanding Evaluation
Oct 06, 2025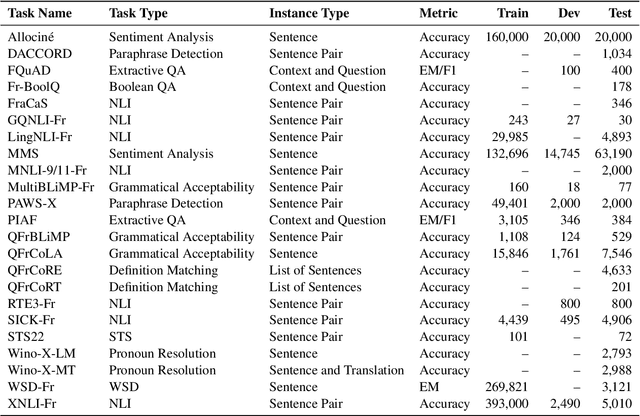
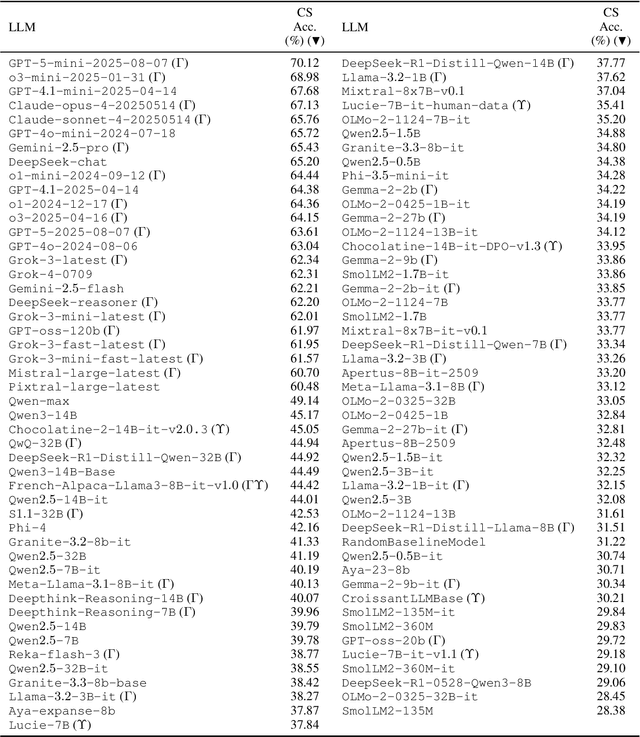


To address the need for a more comprehensive evaluation of French Natural Language Understanding (NLU), we introduce COLE, a new benchmark composed of 23 diverse task covering a broad range of NLU capabilities, including sentiment analysis, paraphrase detection, grammatical judgment, and reasoning, with a particular focus on linguistic phenomena relevant to the French language. We benchmark 94 large language models (LLM), providing an extensive analysis of the current state of French NLU. Our results highlight a significant performance gap between closed- and open-weights models and identify key challenging frontiers for current LLMs, such as zero-shot extractive question-answering (QA), fine-grained word sense disambiguation, and understanding of regional language variations. We release COLE as a public resource to foster further progress in French language modelling.
A Set of Quebec-French Corpus of Regional Expressions and Terms
Oct 06, 2025The tasks of idiom understanding and dialect understanding are both well-established benchmarks in natural language processing. In this paper, we propose combining them, and using regional idioms as a test of dialect understanding. Towards this end, we propose two new benchmark datasets for the Quebec dialect of French: QFrCoRE, which contains 4,633 instances of idiomatic phrases, and QFrCoRT, which comprises 171 regional instances of idiomatic words. We explain how to construct these corpora, so that our methodology can be replicated for other dialects. Our experiments with 94 LLM demonstrate that our regional idiom benchmarks are a reliable tool for measuring a model's proficiency in a specific dialect.
QFrCoLA: a Quebec-French Corpus of Linguistic Acceptability Judgments
Aug 23, 2025Large and Transformer-based language models perform outstandingly in various downstream tasks. However, there is limited understanding regarding how these models internalize linguistic knowledge, so various linguistic benchmarks have recently been proposed to facilitate syntactic evaluation of language models across languages. This paper introduces QFrCoLA (Quebec-French Corpus of Linguistic Acceptability Judgments), a normative binary acceptability judgments dataset comprising 25,153 in-domain and 2,675 out-of-domain sentences. Our study leverages the QFrCoLA dataset and seven other linguistic binary acceptability judgment corpora to benchmark seven language models. The results demonstrate that, on average, fine-tuned Transformer-based LM are strong baselines for most languages and that zero-shot binary classification large language models perform poorly on the task. However, for the QFrCoLA benchmark, on average, a fine-tuned Transformer-based LM outperformed other methods tested. It also shows that pre-trained cross-lingual LLMs selected for our experimentation do not seem to have acquired linguistic judgment capabilities during their pre-training for Quebec French. Finally, our experiment results on QFrCoLA show that our dataset, built from examples that illustrate linguistic norms rather than speakers' feelings, is similar to linguistic acceptability judgment; it is a challenging dataset that can benchmark LM on their linguistic judgment capabilities.
JUDGEBERT: Assessing Legal Meaning Preservation Between Sentences
Aug 23, 2025Simplifying text while preserving its meaning is a complex yet essential task, especially in sensitive domain applications like legal texts. When applied to a specialized field, like the legal domain, preservation differs significantly from its role in regular texts. This paper introduces FrJUDGE, a new dataset to assess legal meaning preservation between two legal texts. It also introduces JUDGEBERT, a novel evaluation metric designed to assess legal meaning preservation in French legal text simplification. JUDGEBERT demonstrates a superior correlation with human judgment compared to existing metrics. It also passes two crucial sanity checks, while other metrics did not: For two identical sentences, it always returns a score of 100%; on the other hand, it returns 0% for two unrelated sentences. Our findings highlight its potential to transform legal NLP applications, ensuring accuracy and accessibility for text simplification for legal practitioners and lay users.
Quebec Automobile Insurance Question-Answering With Retrieval-Augmented Generation
Oct 12, 2024



Large Language Models (LLMs) perform outstandingly in various downstream tasks, and the use of the Retrieval-Augmented Generation (RAG) architecture has been shown to improve performance for legal question answering (Nuruzzaman and Hussain, 2020; Louis et al., 2024). However, there are limited applications in insurance questions-answering, a specific type of legal document. This paper introduces two corpora: the Quebec Automobile Insurance Expertise Reference Corpus and a set of 82 Expert Answers to Layperson Automobile Insurance Questions. Our study leverages both corpora to automatically and manually assess a GPT4-o, a state-of-the-art LLM, to answer Quebec automobile insurance questions. Our results demonstrate that, on average, using our expertise reference corpus generates better responses on both automatic and manual evaluation metrics. However, they also highlight that LLM QA is unreliable enough for mass utilization in critical areas. Indeed, our results show that between 5% to 13% of answered questions include a false statement that could lead to customer misunderstanding.
Deepparse : An Extendable, and Fine-Tunable State-Of-The-Art Library for Parsing Multinational Street Addresses
Nov 20, 2023



Segmenting an address into meaningful components, also known as address parsing, is an essential step in many applications from record linkage to geocoding and package delivery. Consequently, a lot of work has been dedicated to develop accurate address parsing techniques, with machine learning and neural network methods leading the state-of-the-art scoreboard. However, most of the work on address parsing has been confined to academic endeavours with little availability of free and easy-to-use open-source solutions. This paper presents Deepparse, a Python open-source, extendable, fine-tunable address parsing solution under LGPL-3.0 licence to parse multinational addresses using state-of-the-art deep learning algorithms and evaluated on over 60 countries. It can parse addresses written in any language and use any address standard. The pre-trained model achieves average $99~\%$ parsing accuracies on the countries used for training with no pre-processing nor post-processing needed. Moreover, the library supports fine-tuning with new data to generate a custom address parser.
RISC: Generating Realistic Synthetic Bilingual Insurance Contract
Apr 09, 2023This paper presents RISC, an open-source Python package data generator (https://github.com/GRAAL-Research/risc). RISC generates look-alike automobile insurance contracts based on the Quebec regulatory insurance form in French and English. Insurance contracts are 90 to 100 pages long and use complex legal and insurance-specific vocabulary for a layperson. Hence, they are a much more complex class of documents than those in traditional NLP corpora. Therefore, we introduce RISCBAC, a Realistic Insurance Synthetic Bilingual Automobile Contract dataset based on the mandatory Quebec car insurance contract. The dataset comprises 10,000 French and English unannotated insurance contracts. RISCBAC enables NLP research for unsupervised automatic summarisation, question answering, text simplification, machine translation and more. Moreover, it can be further automatically annotated as a dataset for supervised tasks such as NER
Quantifying French Document Complexity
Aug 27, 2022
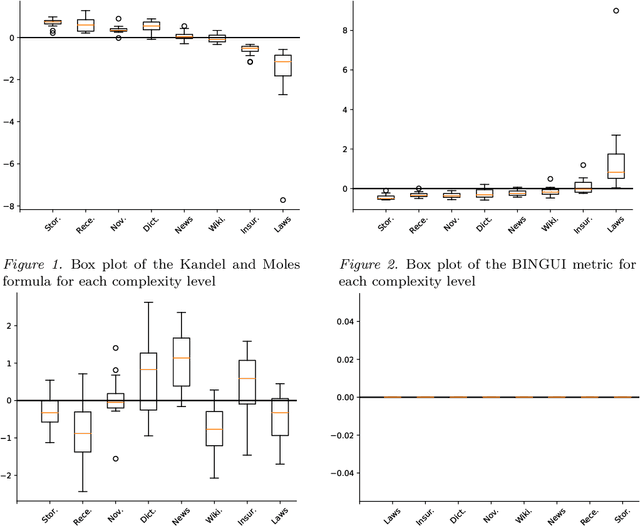
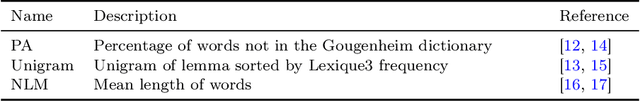
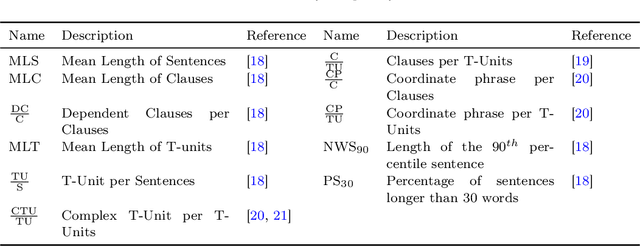
Measuring a document's complexity level is an open challenge, particularly when one is working on a diverse corpus of documents rather than comparing several documents on a similar topic or working on a language other than English. In this paper, we define a methodology to measure the complexity of French documents, using a new general and diversified corpus of texts, the "French Canadian complexity level corpus", and a wide range of metrics. We compare different learning algorithms to this task and contrast their performances and their observations on which characteristics of the texts are more significant to their complexity. Our results show that our methodology gives a general-purpose measurement of text complexity in French.
"FIJO": a French Insurance Soft Skill Detection Dataset
Apr 11, 2022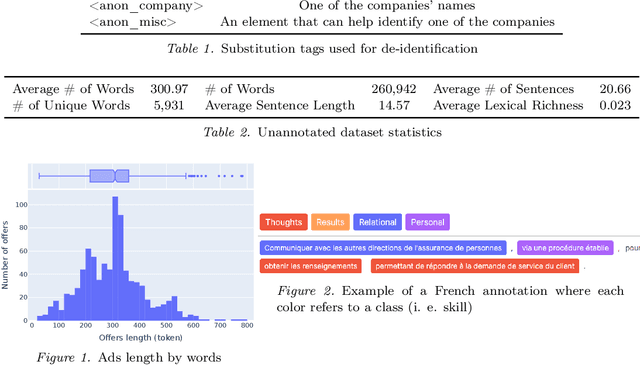

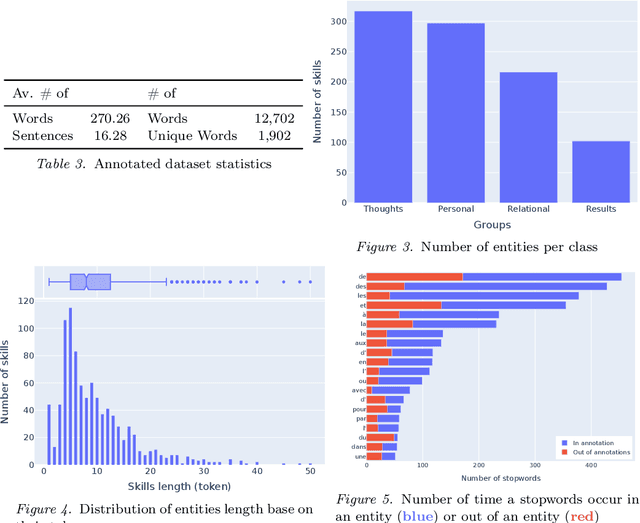

Understanding the evolution of job requirements is becoming more important for workers, companies and public organizations to follow the fast transformation of the employment market. Fortunately, recent natural language processing (NLP) approaches allow for the development of methods to automatically extract information from job ads and recognize skills more precisely. However, these efficient approaches need a large amount of annotated data from the studied domain which is difficult to access, mainly due to intellectual property. This article proposes a new public dataset, FIJO, containing insurance job offers, including many soft skill annotations. To understand the potential of this dataset, we detail some characteristics and some limitations. Then, we present the results of skill detection algorithms using a named entity recognition approach and show that transformers-based models have good token-wise performances on this dataset. Lastly, we analyze some errors made by our best model to emphasize the difficulties that may arise when applying NLP approaches.