 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepparse : An Extendable, and Fine-Tunable State-Of-The-Art Library for Parsing Multinational Street Addresses
Nov 20, 2023



Segmenting an address into meaningful components, also known as address parsing, is an essential step in many applications from record linkage to geocoding and package delivery. Consequently, a lot of work has been dedicated to develop accurate address parsing techniques, with machine learning and neural network methods leading the state-of-the-art scoreboard. However, most of the work on address parsing has been confined to academic endeavours with little availability of free and easy-to-use open-source solutions. This paper presents Deepparse, a Python open-source, extendable, fine-tunable address parsing solution under LGPL-3.0 licence to parse multinational addresses using state-of-the-art deep learning algorithms and evaluated on over 60 countries. It can parse addresses written in any language and use any address standard. The pre-trained model achieves average $99~\%$ parsing accuracies on the countries used for training with no pre-processing nor post-processing needed. Moreover, the library supports fine-tuning with new data to generate a custom address parser.
"FIJO": a French Insurance Soft Skill Detection Dataset
Apr 11, 2022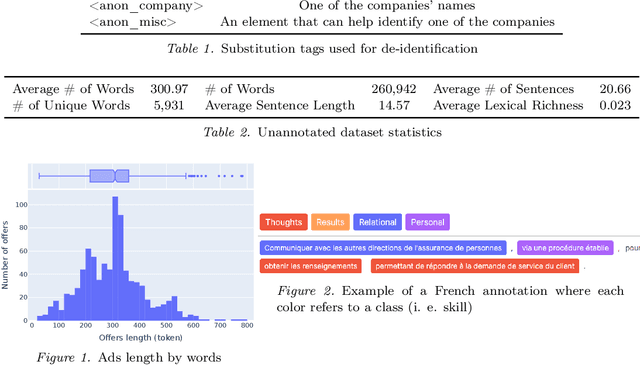

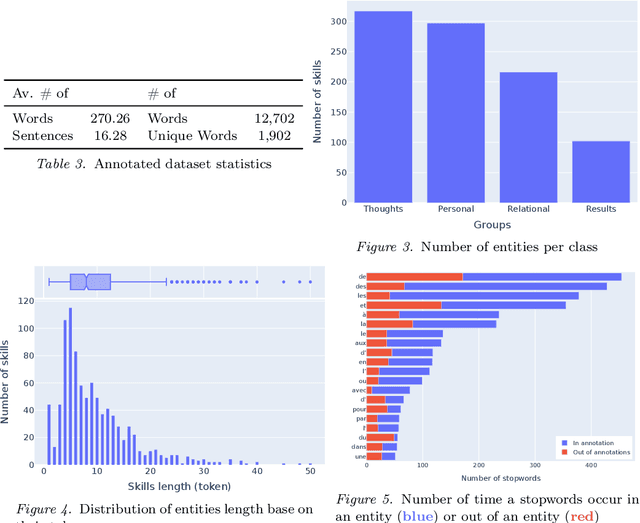

Understanding the evolution of job requirements is becoming more important for workers, companies and public organizations to follow the fast transformation of the employment market. Fortunately, recent natural language processing (NLP) approaches allow for the development of methods to automatically extract information from job ads and recognize skills more precisely. However, these efficient approaches need a large amount of annotated data from the studied domain which is difficult to access, mainly due to intellectual property. This article proposes a new public dataset, FIJO, containing insurance job offers, including many soft skill annotations. To understand the potential of this dataset, we detail some characteristics and some limitations. Then, we present the results of skill detection algorithms using a named entity recognition approach and show that transformers-based models have good token-wise performances on this dataset. Lastly, we analyze some errors made by our best model to emphasize the difficulties that may arise when applying NLP approaches.
Multinational Address Parsing: A Zero-Shot Evaluation
Dec 07, 2021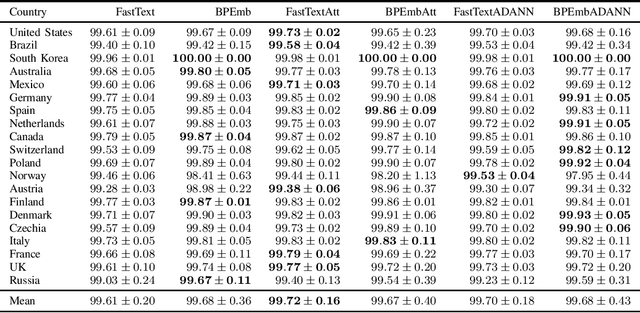
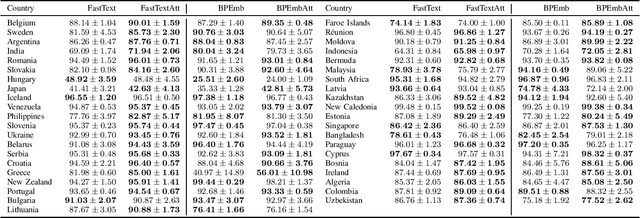
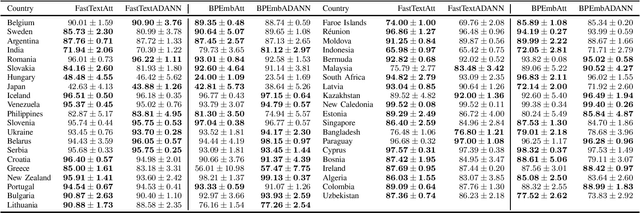
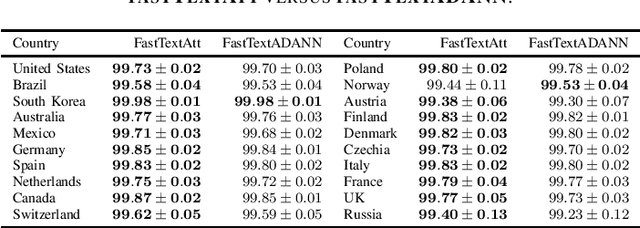
Address parsing consists of identifying the segments that make up an address, such as a street name or a postal code. Because of its importance for tasks like record linkage, address parsing has been approached with many techniques, the latest relying on neural networks. While these models yield notable results, previous work on neural networks has only focused on parsing addresses from a single source country. This paper explores the possibility of transferring the address parsing knowledge acquired by training deep learning models on some countries' addresses to others with no further training in a zero-shot transfer learning setting. We also experiment using an attention mechanism and a domain adversarial training algorithm in the same zero-shot transfer setting to improve performance. Both methods yield state-of-the-art performance for most of the tested countries while giving good results to the remaining countries. We also explore the effect of incomplete addresses on our best model, and we evaluate the impact of using incomplete addresses during training. In addition, we propose an open-source Python implementation of some of our trained models.
Leveraging Subword Embeddings for Multinational Address Parsing
Jun 29, 2020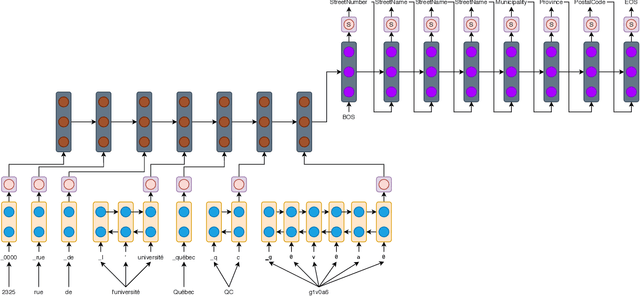
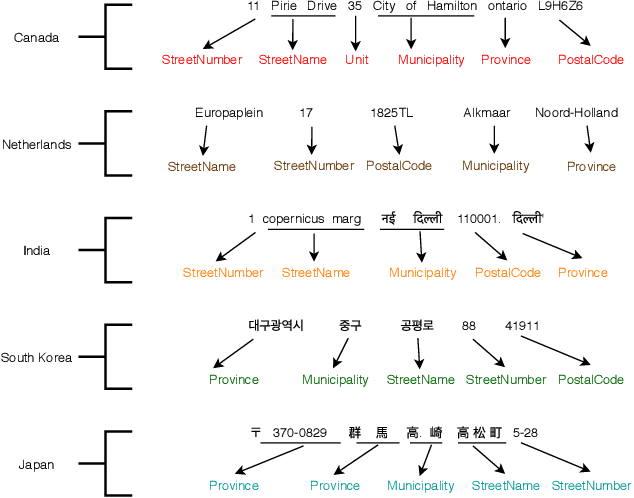


Address parsing consists of identifying the segments that make up an address such as a street name or a postal code. Because of its importance for tasks like record linkage, address parsing has been approached with many techniques. Neural network methods defined a new state-of-the-art for address parsing. While this approach yielded notable results, previous work has only focused on applying neural networks to achieve address parsing of addresses from one source country. We propose an approach in which we employ subword embeddings and a Recurrent Neural Network architecture to build a single model capable of learning to parse addresses from multiple countries at the same time while taking into account the difference in languages and address formatting systems. We achieved accuracies around 99 % on the countries used for training with no pre-processing nor post-processing needed. In addition, we explore the possibility of transferring the address parsing knowledge attained by training on some countries' addresses to others with no further training. This setting is also called zero-shot transfer learning. We achieve good results for 80 % of the countries (34 out of 41), almost 50 % of which (19 out of 41) is near state-of-the-art performance.