 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing RNN from Using Sequence Length as a Feature
Dec 16, 2022Recurrent neural networks are deep learning topologies that can be trained to classify long documents. However, in our recent work, we found a critical problem with these cells: they can use the length differences between texts of different classes as a prominent classification feature. This has the effect of producing models that are brittle and fragile to concept drift, can provide misleading performances and are trivially explainable regardless of text content. This paper illustrates the problem using synthetic and real-world data and provides a simple solution using weight decay regularization.
Reducing Sequence Length Learning Impacts on Transformer Models
Dec 16, 2022Classification algorithms using Transformer architectures can be affected by the sequence length learning problem whenever observations from different classes have a different length distribution. This problem brings models to use sequence length as a predictive feature instead of relying on important textual information. Even if most public datasets are not affected by this problem, privately corpora for fields such as medicine and insurance may carry this data bias. This poses challenges throughout the value chain given their usage in a machine learning application. In this paper, we empirically expose this problem and present approaches to minimize its impacts.
Multinational Address Parsing: A Zero-Shot Evaluation
Dec 07, 2021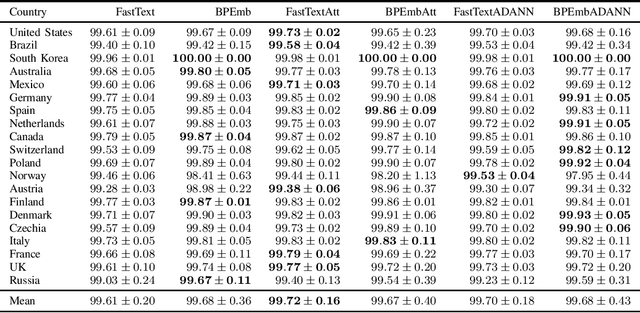
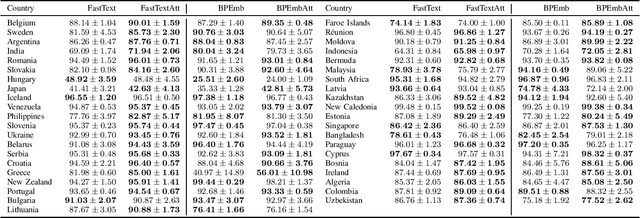
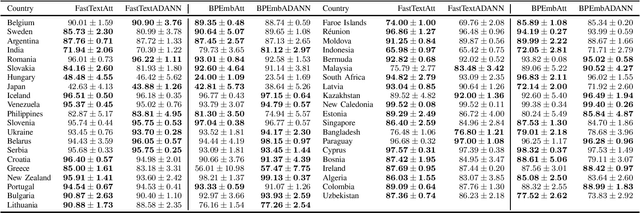
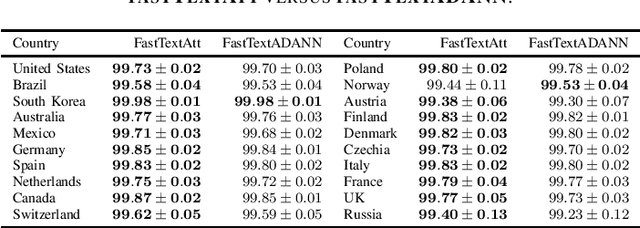
Address parsing consists of identifying the segments that make up an address, such as a street name or a postal code. Because of its importance for tasks like record linkage, address parsing has been approached with many techniques, the latest relying on neural networks. While these models yield notable results, previous work on neural networks has only focused on parsing addresses from a single source country. This paper explores the possibility of transferring the address parsing knowledge acquired by training deep learning models on some countries' addresses to others with no further training in a zero-shot transfer learning setting. We also experiment using an attention mechanism and a domain adversarial training algorithm in the same zero-shot transfer setting to improve performance. Both methods yield state-of-the-art performance for most of the tested countries while giving good results to the remaining countries. We also explore the effect of incomplete addresses on our best model, and we evaluate the impact of using incomplete addresses during training. In addition, we propose an open-source Python implementation of some of our trained models.
Geographic ratemaking with spatial embeddings
Apr 26, 2021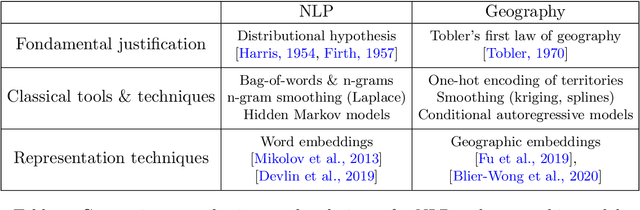
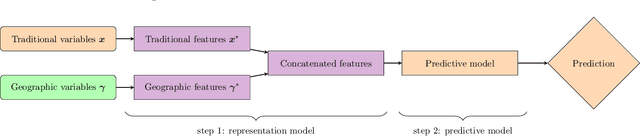
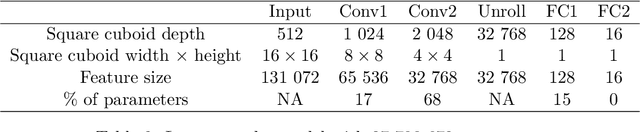
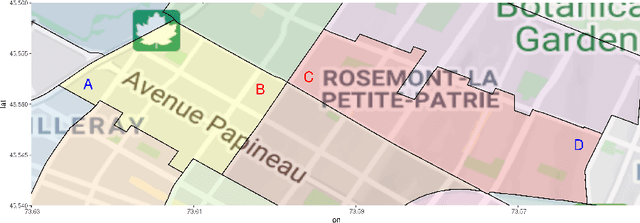
Spatial data is a rich source of information for actuarial applications: knowledge of a risk's location could improve an insurance company's ratemaking, reserving or risk management processes. Insurance companies with high exposures in a territory typically have a competitive advantage since they may use historical losses in a region to model spatial risk non-parametrically. Relying on geographic losses is problematic for areas where past loss data is unavailable. This paper presents a method based on data (instead of smoothing historical insurance claim losses) to construct a geographic ratemaking model. In particular, we construct spatial features within a complex representation model, then use the features as inputs to a simpler predictive model (like a generalized linear model). Our approach generates predictions with smaller bias and smaller variance than other spatial interpolation models such as bivariate splines in most situations. This method also enables us to generate rates in territories with no historical experience.
Generating Intelligible Plumitifs Descriptions: Use Case Application with Ethical Considerations
Nov 24, 2020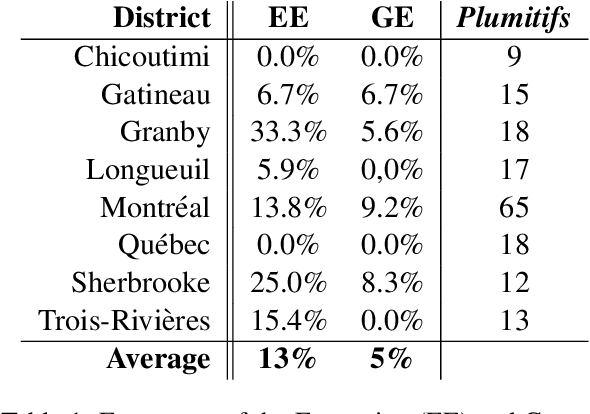
Plumitifs (dockets) were initially a tool for law clerks. Nowadays, they are used as summaries presenting all the steps of a judicial case. Information concerning parties' identity, jurisdiction in charge of administering the case, and some information relating to the nature and the course of the preceding are available through plumitifs. They are publicly accessible but barely understandable; they are written using abbreviations and referring to provisions from the Criminal Code of Canada, which makes them hard to reason about. In this paper, we propose a simple yet efficient multi-source language generation architecture that leverages both the plumitif and the Criminal Code's content to generate intelligible plumitifs descriptions. It goes without saying that ethical considerations rise with these sensitive documents made readable and available at scale, legitimate concerns that we address in this paper.
Leveraging Subword Embeddings for Multinational Address Parsing
Jun 29, 2020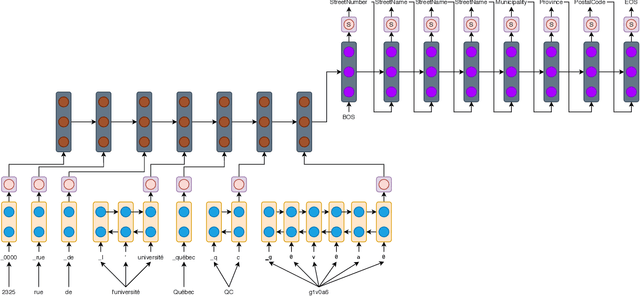
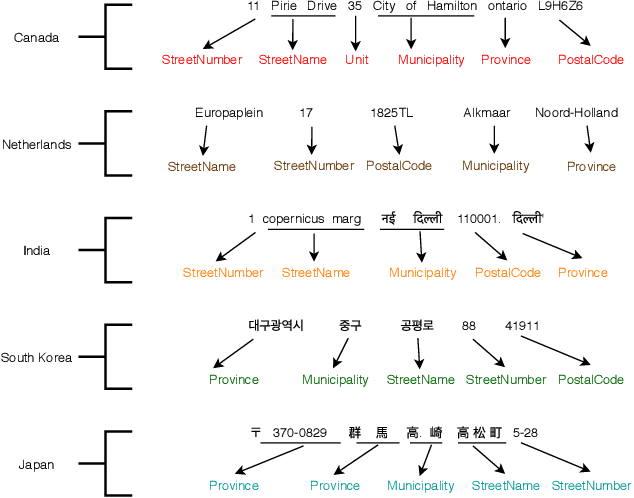


Address parsing consists of identifying the segments that make up an address such as a street name or a postal code. Because of its importance for tasks like record linkage, address parsing has been approached with many techniques. Neural network methods defined a new state-of-the-art for address parsing. While this approach yielded notable results, previous work has only focused on applying neural networks to achieve address parsing of addresses from one source country. We propose an approach in which we employ subword embeddings and a Recurrent Neural Network architecture to build a single model capable of learning to parse addresses from multiple countries at the same time while taking into account the difference in languages and address formatting systems. We achieved accuracies around 99 % on the countries used for training with no pre-processing nor post-processing needed. In addition, we explore the possibility of transferring the address parsing knowledge attained by training on some countries' addresses to others with no further training. This setting is also called zero-shot transfer learning. We achieve good results for 80 % of the countries (34 out of 41), almost 50 % of which (19 out of 41) is near state-of-the-art performance.
Attending Form and Context to Generate Specialized Out-of-VocabularyWords Representations
Dec 14, 2019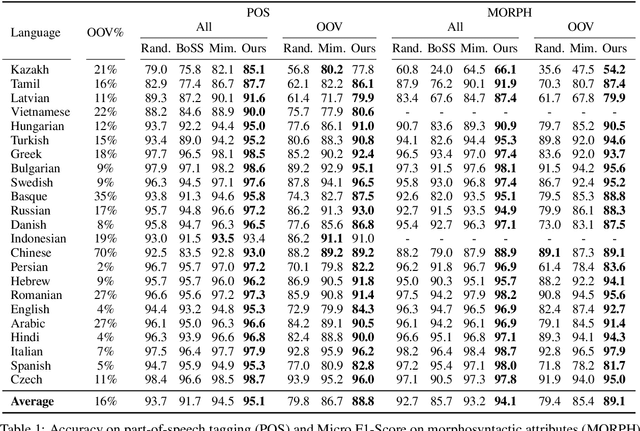
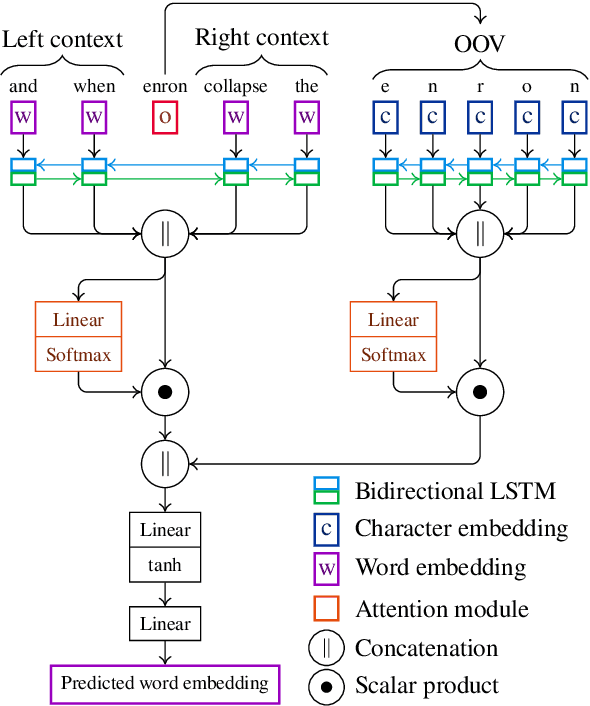
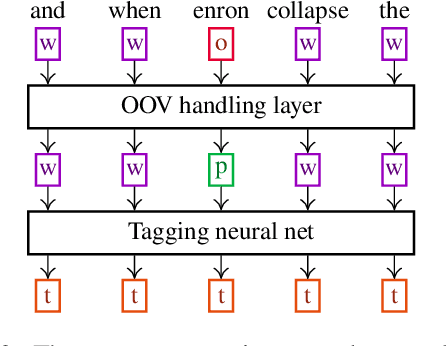

We propose a new contextual-compositional neural network layer that handles out-of-vocabulary (OOV) words in natural language processing (NLP) tagging tasks. This layer consists of a model that attends to both the character sequence and the context in which the OOV words appear. We show that our model learns to generate task-specific \textit{and} sentence-dependent OOV word representations without the need for pre-training on an embedding table, unlike previous attempts. We insert our layer in the state-of-the-art tagging model of \citet{plank2016multilingual} and thoroughly evaluate its contribution on 23 different languages on the task of jointly tagging part-of-speech and morphosyntactic attributes. Our OOV handling method successfully improves performances of this model on every language but one to achieve a new state-of-the-art on the Universal Dependencies Dataset 1.4.
A Robust Self-Learning Method for Fully Unsupervised Cross-Lingual Mappings of Word Embeddings: Making the Method Robustly Reproducible as Well
Dec 03, 2019


In this paper, we reproduce the experiments of Artetxe et al. (2018b) regarding the robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings. We show that the reproduction of their method is indeed feasible with some minor assumptions. We further investigate the robustness of their model by introducing four new languages that are less similar to English than the ones proposed by the original paper. In order to assess the stability of their model, we also conduct a grid search over sensible hyperparameters. We then propose key recommendations applicable to any research project in order to deliver fully reproducible research.
Predicting and interpreting embeddings for out of vocabulary words in downstream tasks
Mar 02, 2019
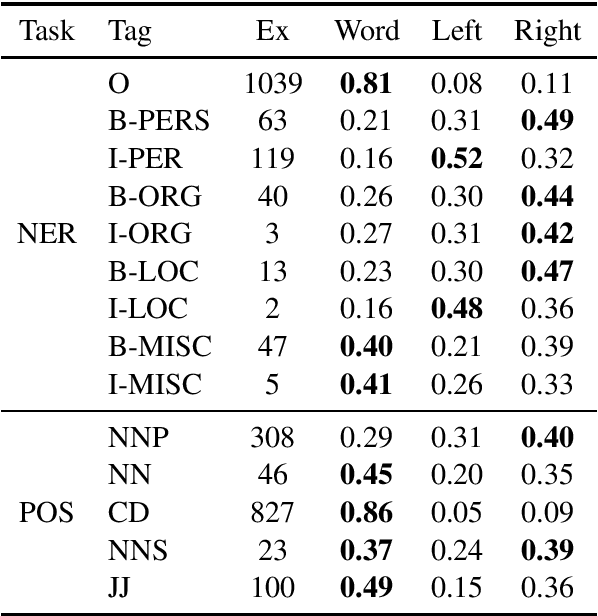

We propose a novel way to handle out of vocabulary (OOV) words in downstream natural language processing (NLP) tasks. We implement a network that predicts useful embeddings for OOV words based on their morphology and on the context in which they appear. Our model also incorporates an attention mechanism indicating the focus allocated to the left context words, the right context words or the word's characters, hence making the prediction more interpretable. The model is a ``drop-in'' module that is jointly trained with the downstream task's neural network, thus producing embeddings specialized for the task at hand. When the task is mostly syntactical, we observe that our model aims most of its attention on surface form characters. On the other hand, for tasks more semantical, the network allocates more attention to the surrounding words. In all our tests, the module helps the network to achieve better performances in comparison to the use of simple random embeddings.
* 2 pages, 0 figures, 2 tables