 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttending Form and Context to Generate Specialized Out-of-VocabularyWords Representations
Paper and Code
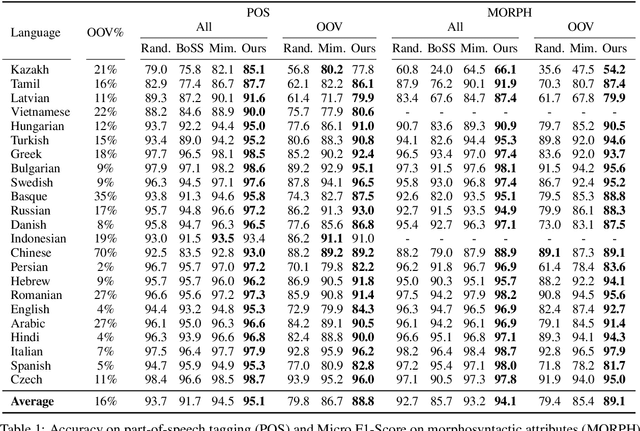
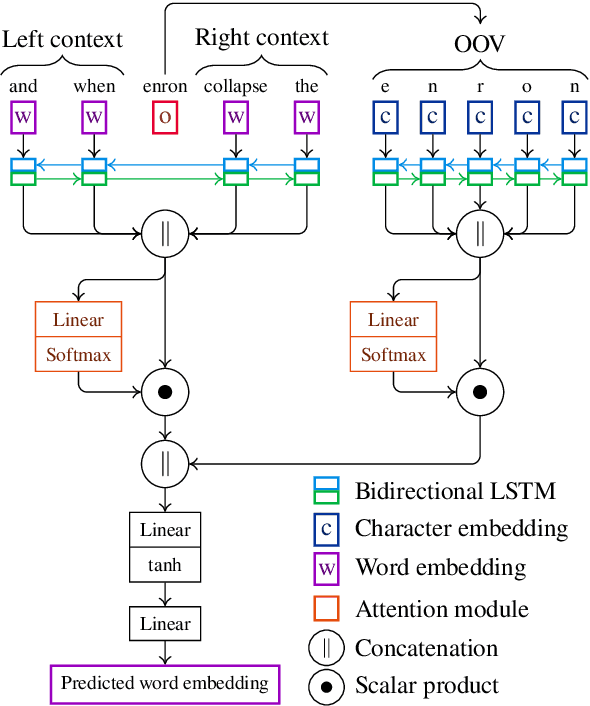
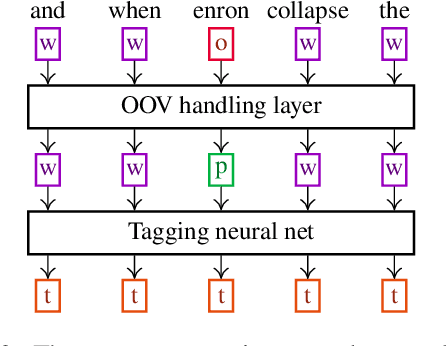

We propose a new contextual-compositional neural network layer that handles out-of-vocabulary (OOV) words in natural language processing (NLP) tagging tasks. This layer consists of a model that attends to both the character sequence and the context in which the OOV words appear. We show that our model learns to generate task-specific \textit{and} sentence-dependent OOV word representations without the need for pre-training on an embedding table, unlike previous attempts. We insert our layer in the state-of-the-art tagging model of \citet{plank2016multilingual} and thoroughly evaluate its contribution on 23 different languages on the task of jointly tagging part-of-speech and morphosyntactic attributes. Our OOV handling method successfully improves performances of this model on every language but one to achieve a new state-of-the-art on the Universal Dependencies Dataset 1.4.