 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Dialect Adaptation of Large Language Models: A French Dialect Case-Study
Oct 26, 2025Despite the widespread adoption of large language models (LLMs), their strongest capabilities remain largely confined to a small number of high-resource languages for which there is abundant training data. Recently, continual pre-training (CPT) has emerged as a means to fine-tune these models to low-resource regional dialects. In this paper, we study the use of CPT for dialect learning under tight data and compute budgets. Using low-rank adaptation (LoRA) and compute-efficient continual pre-training, we adapt three LLMs to the Qu\'ebec French dialect using a very small dataset and benchmark them on the COLE suite. Our experiments demonstrate an improvement on the minority dialect benchmarks with minimal regression on the prestige language benchmarks with under 1% of model parameters updated. Analysis of the results demonstrate that gains are highly contingent on corpus composition. These findings indicate that CPT with parameter-efficient fine-tuning (PEFT) can narrow the dialect gap by providing cost-effective and sustainable language resource creation, expanding high-quality LLM access to minority linguistic communities. We release the first Qu\'ebec French LLMs on HuggingFace.
A Set of Quebec-French Corpus of Regional Expressions and Terms
Oct 06, 2025The tasks of idiom understanding and dialect understanding are both well-established benchmarks in natural language processing. In this paper, we propose combining them, and using regional idioms as a test of dialect understanding. Towards this end, we propose two new benchmark datasets for the Quebec dialect of French: QFrCoRE, which contains 4,633 instances of idiomatic phrases, and QFrCoRT, which comprises 171 regional instances of idiomatic words. We explain how to construct these corpora, so that our methodology can be replicated for other dialects. Our experiments with 94 LLM demonstrate that our regional idiom benchmarks are a reliable tool for measuring a model's proficiency in a specific dialect.
COLE: a Comprehensive Benchmark for French Language Understanding Evaluation
Oct 06, 2025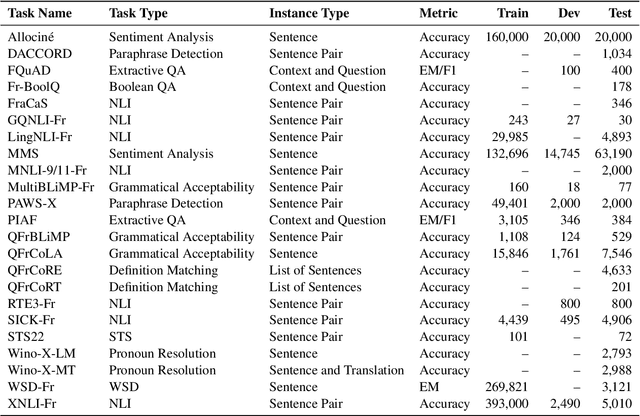
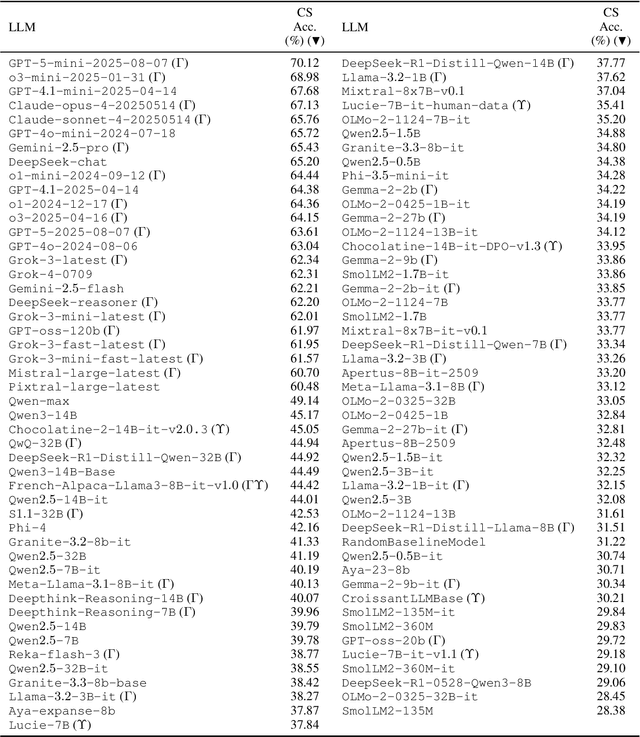


To address the need for a more comprehensive evaluation of French Natural Language Understanding (NLU), we introduce COLE, a new benchmark composed of 23 diverse task covering a broad range of NLU capabilities, including sentiment analysis, paraphrase detection, grammatical judgment, and reasoning, with a particular focus on linguistic phenomena relevant to the French language. We benchmark 94 large language models (LLM), providing an extensive analysis of the current state of French NLU. Our results highlight a significant performance gap between closed- and open-weights models and identify key challenging frontiers for current LLMs, such as zero-shot extractive question-answering (QA), fine-grained word sense disambiguation, and understanding of regional language variations. We release COLE as a public resource to foster further progress in French language modelling.
QFrCoLA: a Quebec-French Corpus of Linguistic Acceptability Judgments
Aug 23, 2025Large and Transformer-based language models perform outstandingly in various downstream tasks. However, there is limited understanding regarding how these models internalize linguistic knowledge, so various linguistic benchmarks have recently been proposed to facilitate syntactic evaluation of language models across languages. This paper introduces QFrCoLA (Quebec-French Corpus of Linguistic Acceptability Judgments), a normative binary acceptability judgments dataset comprising 25,153 in-domain and 2,675 out-of-domain sentences. Our study leverages the QFrCoLA dataset and seven other linguistic binary acceptability judgment corpora to benchmark seven language models. The results demonstrate that, on average, fine-tuned Transformer-based LM are strong baselines for most languages and that zero-shot binary classification large language models perform poorly on the task. However, for the QFrCoLA benchmark, on average, a fine-tuned Transformer-based LM outperformed other methods tested. It also shows that pre-trained cross-lingual LLMs selected for our experimentation do not seem to have acquired linguistic judgment capabilities during their pre-training for Quebec French. Finally, our experiment results on QFrCoLA show that our dataset, built from examples that illustrate linguistic norms rather than speakers' feelings, is similar to linguistic acceptability judgment; it is a challenging dataset that can benchmark LM on their linguistic judgment capabilities.
JUDGEBERT: Assessing Legal Meaning Preservation Between Sentences
Aug 23, 2025Simplifying text while preserving its meaning is a complex yet essential task, especially in sensitive domain applications like legal texts. When applied to a specialized field, like the legal domain, preservation differs significantly from its role in regular texts. This paper introduces FrJUDGE, a new dataset to assess legal meaning preservation between two legal texts. It also introduces JUDGEBERT, a novel evaluation metric designed to assess legal meaning preservation in French legal text simplification. JUDGEBERT demonstrates a superior correlation with human judgment compared to existing metrics. It also passes two crucial sanity checks, while other metrics did not: For two identical sentences, it always returns a score of 100%; on the other hand, it returns 0% for two unrelated sentences. Our findings highlight its potential to transform legal NLP applications, ensuring accuracy and accessibility for text simplification for legal practitioners and lay users.
Automated Journalistic Questions: A New Method for Extracting 5W1H in French
May 20, 2025The 5W1H questions -- who, what, when, where, why and how -- are commonly used in journalism to ensure that an article describes events clearly and systematically. Answering them is a crucial prerequisites for tasks such as summarization, clustering, and news aggregation. In this paper, we design the first automated extraction pipeline to get 5W1H information from French news articles. To evaluate the performance of our algo- rithm, we also create a corpus of 250 Quebec news articles with 5W1H answers marked by four human annotators. Our results demonstrate that our pipeline performs as well in this task as the large language model GPT-4o.
Association Rules Mining with Auto-Encoders
Apr 26, 2023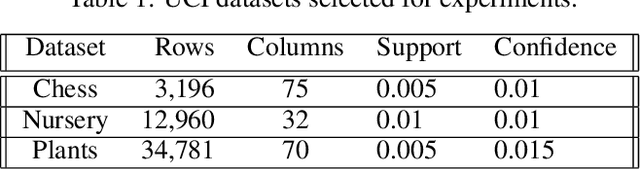
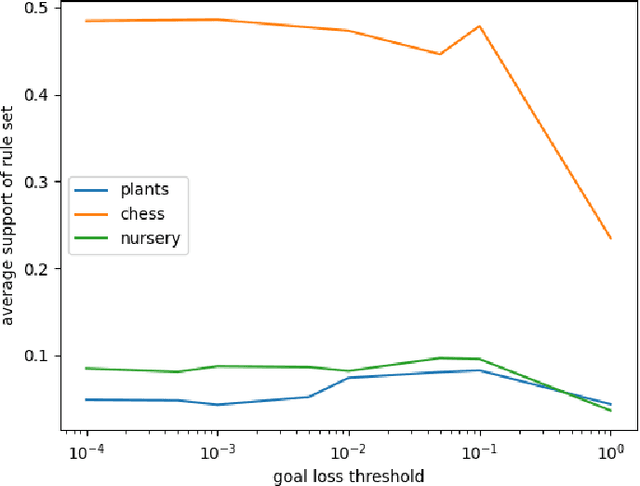


Association rule mining is one of the most studied research fields of data mining, with applications ranging from grocery basket problems to explainable classification systems. Classical association rule mining algorithms have several limitations, especially with regards to their high execution times and number of rules produced. Over the past decade, neural network solutions have been used to solve various optimization problems, such as classification, regression or clustering. However there are still no efficient way association rules using neural networks. In this paper, we present an auto-encoder solution to mine association rule called ARM-AE. We compare our algorithm to FP-Growth and NSGAII on three categorical datasets, and show that our algorithm discovers high support and confidence rule set and has a better execution time than classical methods while preserving the quality of the rule set produced.
RISC: Generating Realistic Synthetic Bilingual Insurance Contract
Apr 09, 2023This paper presents RISC, an open-source Python package data generator (https://github.com/GRAAL-Research/risc). RISC generates look-alike automobile insurance contracts based on the Quebec regulatory insurance form in French and English. Insurance contracts are 90 to 100 pages long and use complex legal and insurance-specific vocabulary for a layperson. Hence, they are a much more complex class of documents than those in traditional NLP corpora. Therefore, we introduce RISCBAC, a Realistic Insurance Synthetic Bilingual Automobile Contract dataset based on the mandatory Quebec car insurance contract. The dataset comprises 10,000 French and English unannotated insurance contracts. RISCBAC enables NLP research for unsupervised automatic summarisation, question answering, text simplification, machine translation and more. Moreover, it can be further automatically annotated as a dataset for supervised tasks such as NER
Relationship Between Online Harmful Behaviors and Social Network Message Writing Style
Dec 14, 2022



In this paper, we explore the relationship between an individual's writing style and the risk that they will engage in online harmful behaviors (such as cyberbullying). In particular, we consider whether measurable differences in writing style relate to different personality types, as modeled by the Big-Five personality traits and the Dark Triad traits, and can differentiate between users who do or do not engage in harmful behaviors. We study messages from nearly 2,500 users from two online communities (Twitter and Reddit) and find that we can measure significant personality differences between regular and harmful users from the writing style of as few as 100 tweets or 40 Reddit posts, aggregate these values to distinguish between healthy and harmful communities, and also use style attributes to predict which users will engage in harmful behaviors.
Neural Bandits for Data Mining: Searching for Dangerous Polypharmacy
Dec 10, 2022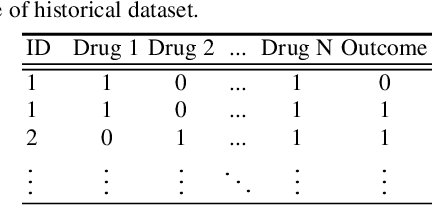
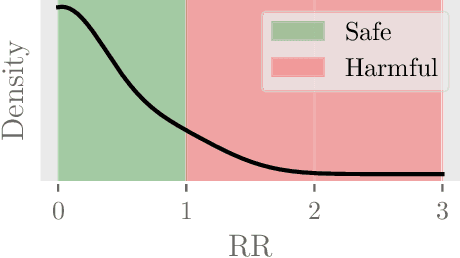
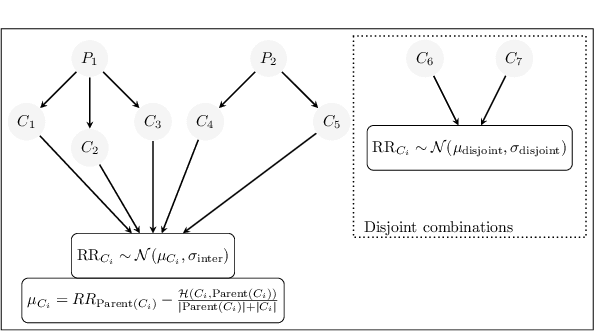
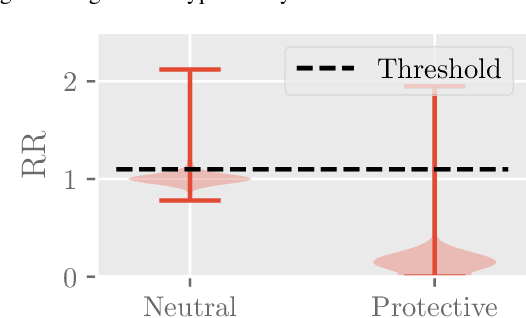
Polypharmacy, most often defined as the simultaneous consumption of five or more drugs at once, is a prevalent phenomenon in the older population. Some of these polypharmacies, deemed inappropriate, may be associated with adverse health outcomes such as death or hospitalization. Considering the combinatorial nature of the problem as well as the size of claims database and the cost to compute an exact association measure for a given drug combination, it is impossible to investigate every possible combination of drugs. Therefore, we propose to optimize the search for potentially inappropriate polypharmacies (PIPs). To this end, we propose the OptimNeuralTS strategy, based on Neural Thompson Sampling and differential evolution, to efficiently mine claims datasets and build a predictive model of the association between drug combinations and health outcomes. We benchmark our method using two datasets generated by an internally developed simulator of polypharmacy data containing 500 drugs and 100 000 distinct combinations. Empirically, our method can detect up to 33\% of PIPs while maintaining an average precision score of 99\% using 10 000 time steps.