 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Word Sense Disambiguation Approach Using WordNet Knowledge Graph
Paper and Code
Jan 08, 2021

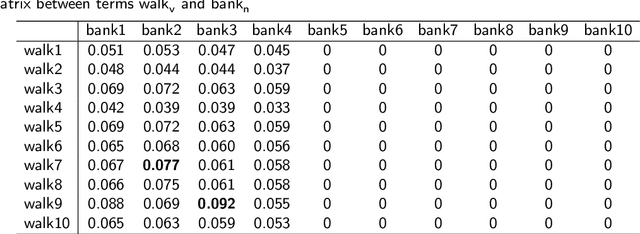
Various applications in computational linguistics and artificial intelligence rely on high-performing word sense disambiguation techniques to solve challenging tasks such as information retrieval, machine translation, question answering, and document clustering. While text comprehension is intuitive for humans, machines face tremendous challenges in processing and interpreting a human's natural language. This paper presents a novel knowledge-based word sense disambiguation algorithm, namely Sequential Contextual Similarity Matrix Multiplication (SCSMM). The SCSMM algorithm combines semantic similarity, heuristic knowledge, and document context to respectively exploit the merits of local context between consecutive terms, human knowledge about terms, and a document's main topic in disambiguating terms. Unlike other algorithms, the SCSMM algorithm guarantees the capture of the maximum sentence context while maintaining the terms' order within the sentence. The proposed algorithm outperformed all other algorithms when disambiguating nouns on the combined gold standard datasets, while demonstrating comparable results to current state-of-the-art word sense disambiguation systems when dealing with each dataset separately. Furthermore, the paper discusses the impact of granularity level, ambiguity rate, sentence size, and part of speech distribution on the performance of the proposed algorithm.