Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying French Document Complexity
Aug 27, 2022
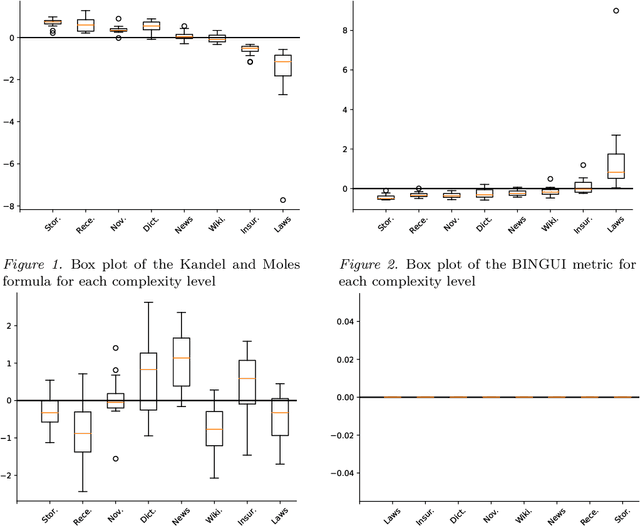
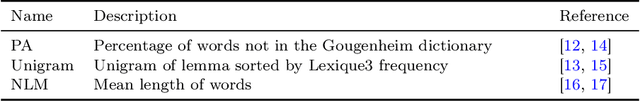
Measuring a document's complexity level is an open challenge, particularly when one is working on a diverse corpus of documents rather than comparing several documents on a similar topic or working on a language other than English. In this paper, we define a methodology to measure the complexity of French documents, using a new general and diversified corpus of texts, the "French Canadian complexity level corpus", and a wide range of metrics. We compare different learning algorithms to this task and contrast their performances and their observations on which characteristics of the texts are more significant to their complexity. Our results show that our methodology gives a general-purpose measurement of text complexity in French.
* Accepted in CAIA 2022
Via