 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Non-Taxonomic Relations for Measuring Semantic Similarity and Relatedness in WordNet
Paper and Code
Jun 22, 2020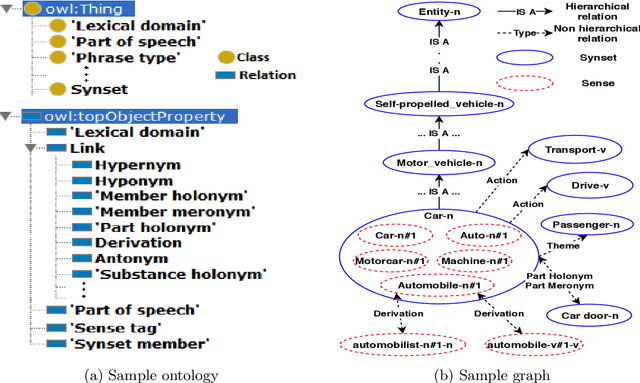

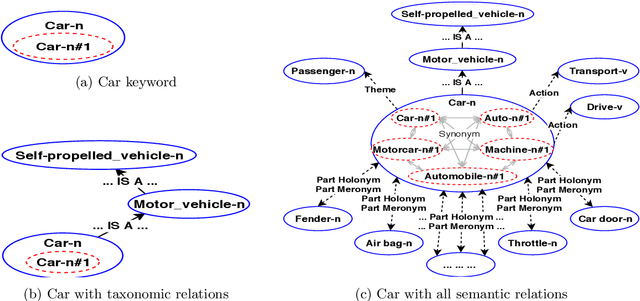

Various applications in the areas of computational linguistics and artificial intelligence employ semantic similarity to solve challenging tasks, such as word sense disambiguation, text classification, information retrieval, machine translation, and document clustering. Previous work on semantic similarity followed a mono-relational approach using mostly the taxonomic relation "ISA". This paper explores the benefits of using all types of non-taxonomic relations in large linked data, such as WordNet knowledge graph, to enhance existing semantic similarity and relatedness measures. We propose a holistic poly-relational approach based on a new relation-based information content and non-taxonomic-based weighted paths to devise a comprehensive semantic similarity and relatedness measure. To demonstrate the benefits of exploiting non-taxonomic relations in a knowledge graph, we used three strategies to deploy non-taxonomic relations at different granularity levels. We conducted experiments on four well-known gold standard datasets, and the results demonstrated the robustness and scalability of the proposed semantic similarity and relatedness measure, which significantly improves existing similarity measures.