 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealist and Pluralist Conceptions of Intelligence and Their Implications on AI Research
Nov 19, 2025In this paper, we argue that current AI research operates on a spectrum between two different underlying conceptions of intelligence: Intelligence Realism, which holds that intelligence represents a single, universal capacity measurable across all systems, and Intelligence Pluralism, which views intelligence as diverse, context-dependent capacities that cannot be reduced to a single universal measure. Through an analysis of current debates in AI research, we demonstrate how the conceptions remain largely implicit yet fundamentally shape how empirical evidence gets interpreted across a wide range of areas. These underlying views generate fundamentally different research approaches across three areas. Methodologically, they produce different approaches to model selection, benchmark design, and experimental validation. Interpretively, they lead to contradictory readings of the same empirical phenomena, from capability emergence to system limitations. Regarding AI risk, they generate categorically different assessments: realists view superintelligence as the primary risk and search for unified alignment solutions, while pluralists see diverse threats across different domains requiring context-specific solutions. We argue that making explicit these underlying assumptions can contribute to a clearer understanding of disagreements in AI research.
On the Measure of a Model: From Intelligence to Generality
Nov 14, 2025Benchmarks such as ARC, Raven-inspired tests, and the Blackbird Task are widely used to evaluate the intelligence of large language models (LLMs). Yet, the concept of intelligence remains elusive- lacking a stable definition and failing to predict performance on practical tasks such as question answering, summarization, or coding. Optimizing for such benchmarks risks misaligning evaluation with real-world utility. Our perspective is that evaluation should be grounded in generality rather than abstract notions of intelligence. We identify three assumptions that often underpin intelligence-focused evaluation: generality, stability, and realism. Through conceptual and formal analysis, we show that only generality withstands conceptual and empirical scrutiny. Intelligence is not what enables generality; generality is best understood as a multitask learning problem that directly links evaluation to measurable performance breadth and reliability. This perspective reframes how progress in AI should be assessed and proposes generality as a more stable foundation for evaluating capability across diverse and evolving tasks.
Mechanistic Interpretability Needs Philosophy
Jun 23, 2025
Mechanistic interpretability (MI) aims to explain how neural networks work by uncovering their underlying causal mechanisms. As the field grows in influence, it is increasingly important to examine not just models themselves, but the assumptions, concepts and explanatory strategies implicit in MI research. We argue that mechanistic interpretability needs philosophy: not as an afterthought, but as an ongoing partner in clarifying its concepts, refining its methods, and assessing the epistemic and ethical stakes of interpreting AI systems. Taking three open problems from the MI literature as examples, this position paper illustrates the value philosophy can add to MI research, and outlines a path toward deeper interdisciplinary dialogue.
Learning and Sustaining Shared Normative Systems via Bayesian Rule Induction in Markov Games
Feb 22, 2024



A universal feature of human societies is the adoption of systems of rules and norms in the service of cooperative ends. How can we build learning agents that do the same, so that they may flexibly cooperate with the human institutions they are embedded in? We hypothesize that agents can achieve this by assuming there exists a shared set of norms that most others comply with while pursuing their individual desires, even if they do not know the exact content of those norms. By assuming shared norms, a newly introduced agent can infer the norms of an existing population from observations of compliance and violation. Furthermore, groups of agents can converge to a shared set of norms, even if they initially diverge in their beliefs about what the norms are. This in turn enables the stability of the normative system: since agents can bootstrap common knowledge of the norms, this leads the norms to be widely adhered to, enabling new entrants to rapidly learn those norms. We formalize this framework in the context of Markov games and demonstrate its operation in a multi-agent environment via approximately Bayesian rule induction of obligative and prohibitive norms. Using our approach, agents are able to rapidly learn and sustain a variety of cooperative institutions, including resource management norms and compensation for pro-social labor, promoting collective welfare while still allowing agents to act in their own interests.
Profiling Irony & Stereotype: Exploring Sentiment, Topic, and Lexical Features
Nov 08, 2023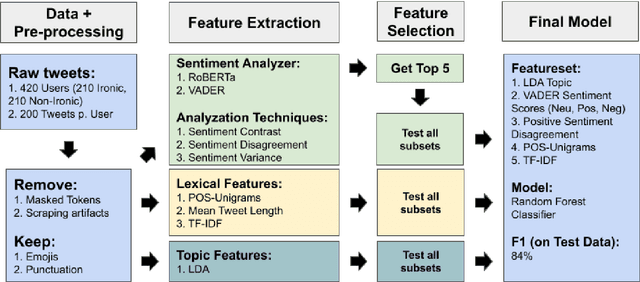
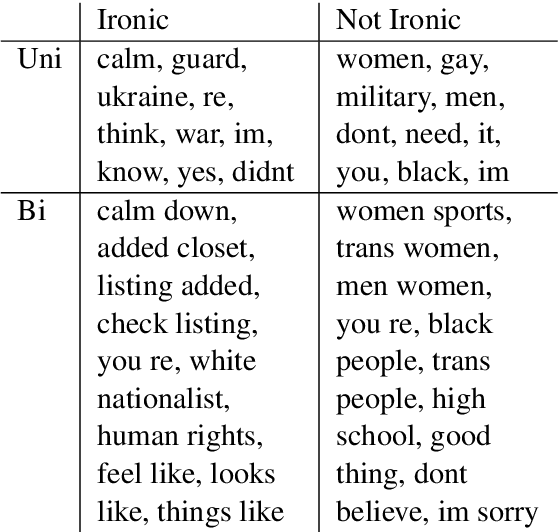


Social media has become a very popular source of information. With this popularity comes an interest in systems that can classify the information produced. This study tries to create such a system detecting irony in Twitter users. Recent work emphasize the importance of lexical features, sentiment features and the contrast herein along with TF-IDF and topic models. Based on a thorough feature selection process, the resulting model contains specific sub-features from these areas. Our model reaches an F1-score of 0.84, which is above the baseline. We find that lexical features, especially TF-IDF, contribute the most to our models while sentiment and topic modeling features contribute less to overall performance. Lastly, we highlight multiple interesting and important paths for further exploration.
Multi-Modality in Music: Predicting Emotion in Music from High-Level Audio Features and Lyrics
Feb 26, 2023This paper aims to test whether a multi-modal approach for music emotion recognition (MER) performs better than a uni-modal one on high-level song features and lyrics. We use 11 song features retrieved from the Spotify API, combined lyrics features including sentiment, TF-IDF, and Anew to predict valence and arousal (Russell, 1980) scores on the Deezer Mood Detection Dataset (DMDD) (Delbouys et al., 2018) with 4 different regression models. We find that out of the 11 high-level song features, mainly 5 contribute to the performance, multi-modal features do better than audio alone when predicting valence. We made our code publically available.