 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-Centered Semantic Graphs for Interpretable Diachronic Sense Tracking
Jan 29, 2026We propose an interpretable, graph-based framework for analyzing semantic shift in diachronic corpora. For each target word and time slice, we induce a word-centered semantic network that integrates distributional similarity from diachronic Skip-gram embeddings with lexical substitutability from time-specific masked language models. We identify sense-related structure by clustering the peripheral graph, align clusters across time via node overlap, and track change through cluster composition and normalized cluster mass. In an application study on a corpus of New York Times Magazine articles (1980 - 2017), we show that graph connectivity reflects polysemy dynamics and that the induced communities capture contrasting trajectories: event-driven sense replacement (trump), semantic stability with cluster over-segmentation effects (god), and gradual association shifts tied to digital communication (post). Overall, word-centered semantic graphs offer a compact and transparent representation for exploring sense evolution without relying on predefined sense inventories.
Identifying economic narratives in large text corpora -- An integrated approach using Large Language Models
Jun 18, 2025As interest in economic narratives has grown in recent years, so has the number of pipelines dedicated to extracting such narratives from texts. Pipelines often employ a mix of state-of-the-art natural language processing techniques, such as BERT, to tackle this task. While effective on foundational linguistic operations essential for narrative extraction, such models lack the deeper semantic understanding required to distinguish extracting economic narratives from merely conducting classic tasks like Semantic Role Labeling. Instead of relying on complex model pipelines, we evaluate the benefits of Large Language Models (LLMs) by analyzing a corpus of Wall Street Journal and New York Times newspaper articles about inflation. We apply a rigorous narrative definition and compare GPT-4o outputs to gold-standard narratives produced by expert annotators. Our results suggests that GPT-4o is capable of extracting valid economic narratives in a structured format, but still falls short of expert-level performance when handling complex documents and narratives. Given the novelty of LLMs in economic research, we also provide guidance for future work in economics and the social sciences that employs LLMs to pursue similar objectives.
ttta: Tools for Temporal Text Analysis
Mar 04, 2025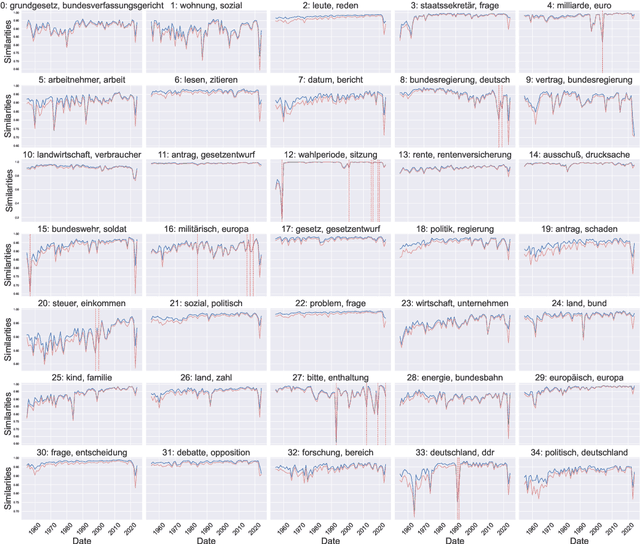
Text data is inherently temporal. The meaning of words and phrases changes over time, and the context in which they are used is constantly evolving. This is not just true for social media data, where the language used is rapidly influenced by current events, memes and trends, but also for journalistic, economic or political text data. Most NLP techniques however consider the corpus at hand to be homogenous in regard to time. This is a simplification that can lead to biased results, as the meaning of words and phrases can change over time. For instance, running a classic Latent Dirichlet Allocation on a corpus that spans several years is not enough to capture changes in the topics over time, but only portraits an "average" topic distribution over the whole time span. Researchers have developed a number of tools for analyzing text data over time. However, these tools are often scattered across different packages and libraries, making it difficult for researchers to use them in a consistent and reproducible way. The ttta package is supposed to serve as a collection of tools for analyzing text data over time.
Zeitenwenden: Detecting changes in the German political discourse
Oct 23, 2024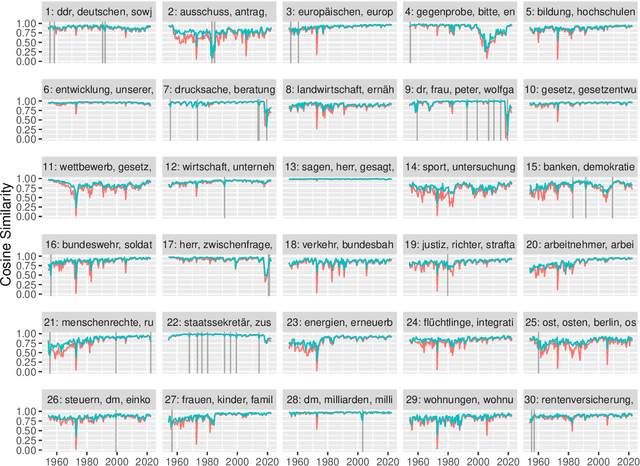
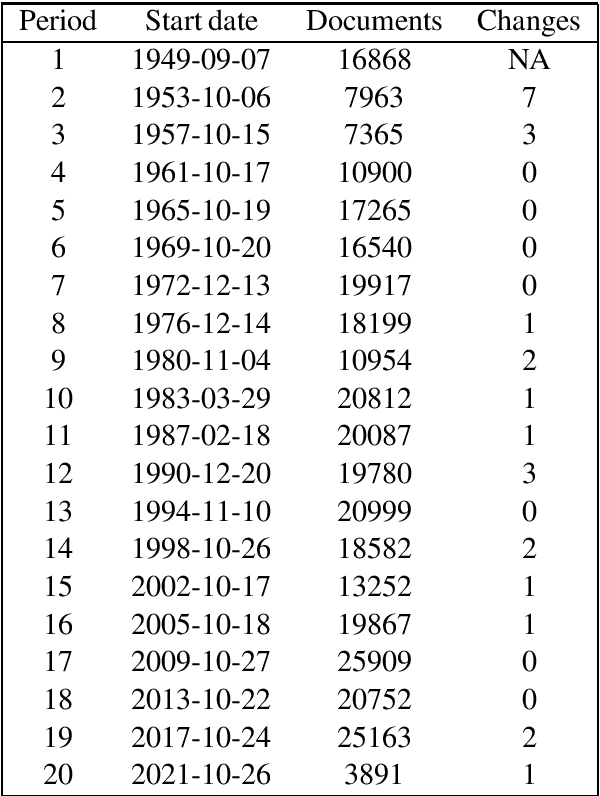
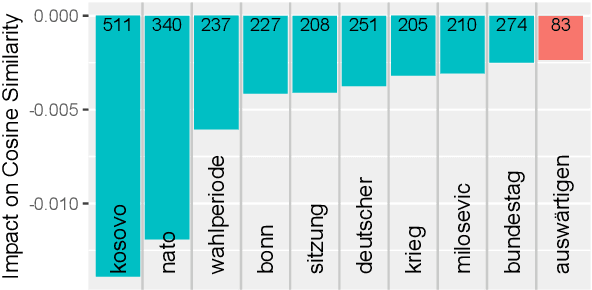
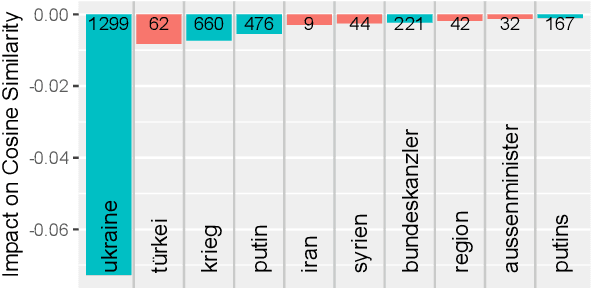
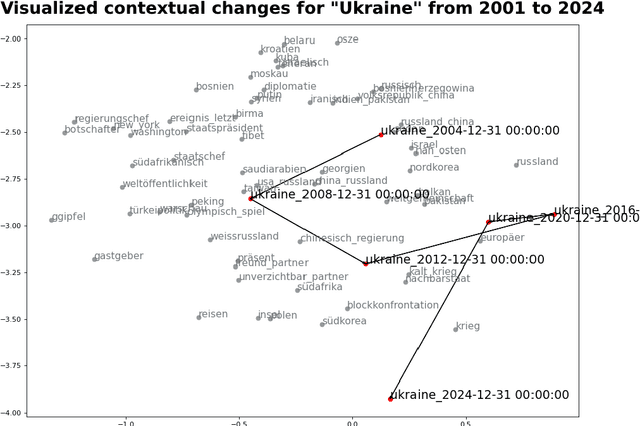
From a monarchy to a democracy, to a dictatorship and back to a democracy -- the German political landscape has been constantly changing ever since the first German national state was formed in 1871. After World War II, the Federal Republic of Germany was formed in 1949. Since then every plenary session of the German Bundestag was logged and even has been digitized over the course of the last few years. We analyze these texts using a time series variant of the topic model LDA to investigate which events had a lasting effect on the political discourse and how the political topics changed over time. This allows us to detect changes in word frequency (and thus key discussion points) in political discourse.
* 7 pages, 6 figures
SpeakGer: A meta-data enriched speech corpus of German state and federal parliaments
Oct 23, 2024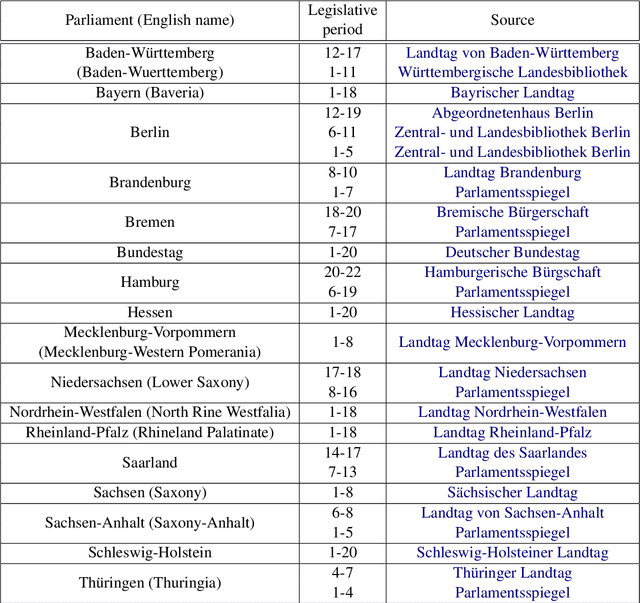
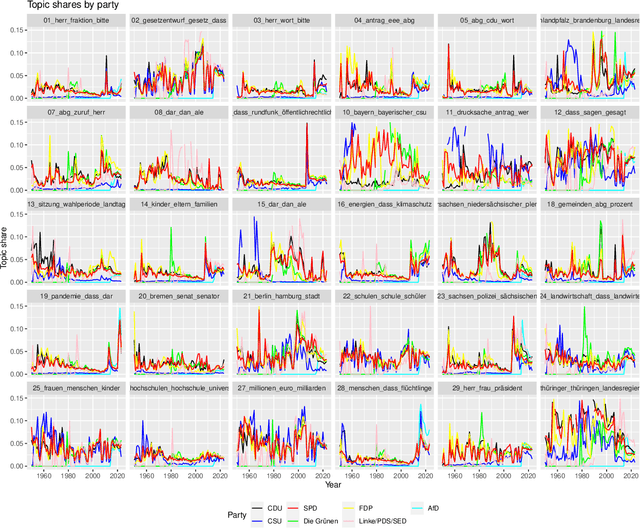
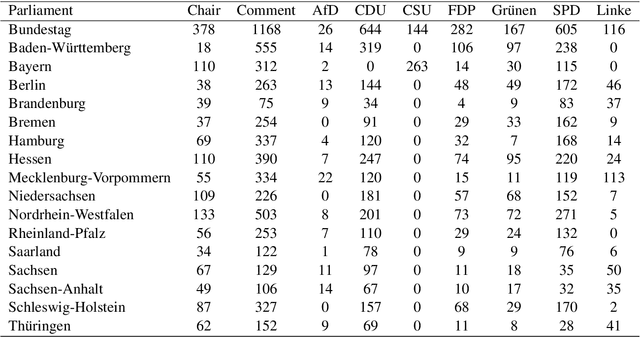
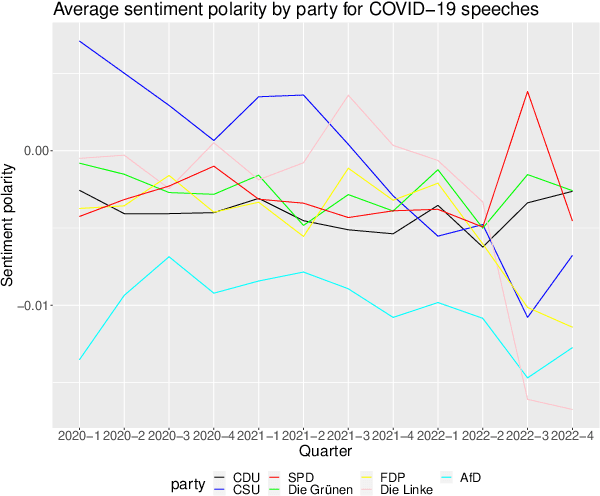
The application of natural language processing on political texts as well as speeches has become increasingly relevant in political sciences due to the ability to analyze large text corpora which cannot be read by a single person. But such text corpora often lack critical meta information, detailing for instance the party, age or constituency of the speaker, that can be used to provide an analysis tailored to more fine-grained research questions. To enable researchers to answer such questions with quantitative approaches such as natural language processing, we provide the SpeakGer data set, consisting of German parliament debates from all 16 federal states of Germany as well as the German Bundestag from 1947-2023, split into a total of 10,806,105 speeches. This data set includes rich meta data in form of information on both reactions from the audience towards the speech as well as information about the speaker's party, their age, their constituency and their party's political alignment, which enables a deeper analysis. We further provide three exploratory analyses, detailing topic shares of different parties throughout time, a descriptive analysis of the development of the age of an average speaker as well as a sentiment analysis of speeches of different parties with regards to the COVID-19 pandemic.
* 10 pages, 3 figures
Lex2Sent: A bagging approach to unsupervised sentiment analysis
Sep 26, 2022
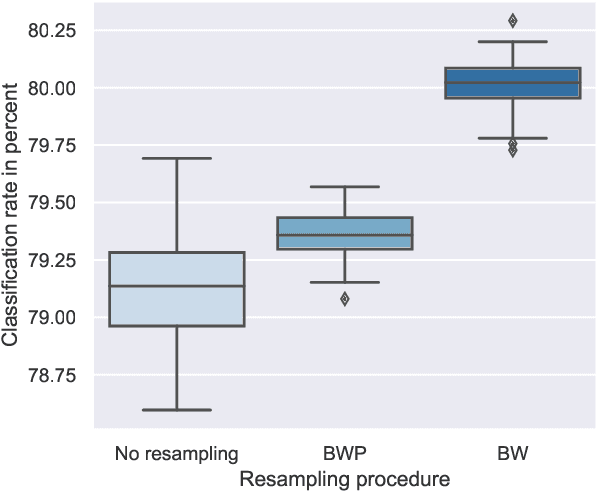
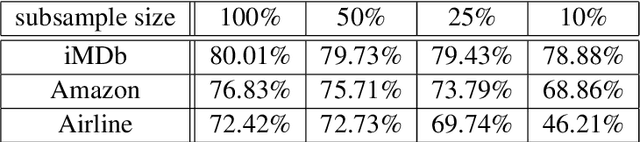
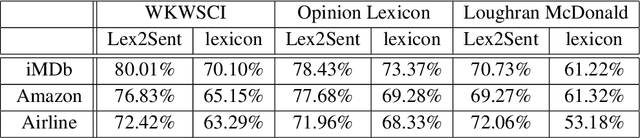
Unsupervised sentiment analysis is traditionally performed by counting those words in a text that are stored in a sentiment lexicon and then assigning a label depending on the proportion of positive and negative words registered. While these "counting" methods are considered to be beneficial as they rate a text deterministically, their classification rates decrease when the analyzed texts are short or the vocabulary differs from what the lexicon considers default. The model proposed in this paper, called Lex2Sent, is an unsupervised sentiment analysis method to improve the classification of sentiment lexicon methods. For this purpose, a Doc2Vec-model is trained to determine the distances between document embeddings and the embeddings of the positive and negative part of a sentiment lexicon. These distances are then evaluated for multiple executions of Doc2Vec on resampled documents and are averaged to perform the classification task. For three benchmark datasets considered in this paper, the proposed Lex2Sent outperforms every evaluated lexicon, including state-of-the-art lexica like VADER or the Opinion Lexicon in terms of classification rate.