 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI for Climate Finance: Agentic Retrieval and Multi-Step Reasoning for Early Warning System Investments
Apr 07, 2025

Tracking financial investments in climate adaptation is a complex and expertise-intensive task, particularly for Early Warning Systems (EWS), which lack standardized financial reporting across multilateral development banks (MDBs) and funds. To address this challenge, we introduce an LLM-based agentic AI system that integrates contextual retrieval, fine-tuning, and multi-step reasoning to extract relevant financial data, classify investments, and ensure compliance with funding guidelines. Our study focuses on a real-world application: tracking EWS investments in the Climate Risk and Early Warning Systems (CREWS) Fund. We analyze 25 MDB project documents and evaluate multiple AI-driven classification methods, including zero-shot and few-shot learning, fine-tuned transformer-based classifiers, chain-of-thought (CoT) prompting, and an agent-based retrieval-augmented generation (RAG) approach. Our results show that the agent-based RAG approach significantly outperforms other methods, achieving 87\% accuracy, 89\% precision, and 83\% recall. Additionally, we contribute a benchmark dataset and expert-annotated corpus, providing a valuable resource for future research in AI-driven financial tracking and climate finance transparency.
ttta: Tools for Temporal Text Analysis
Mar 04, 2025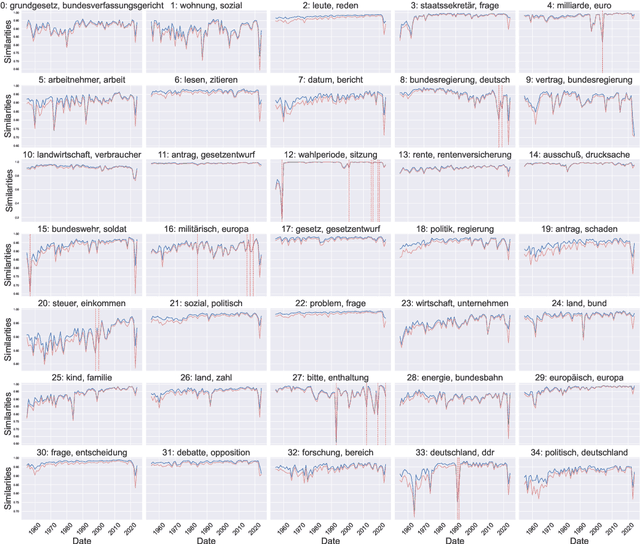
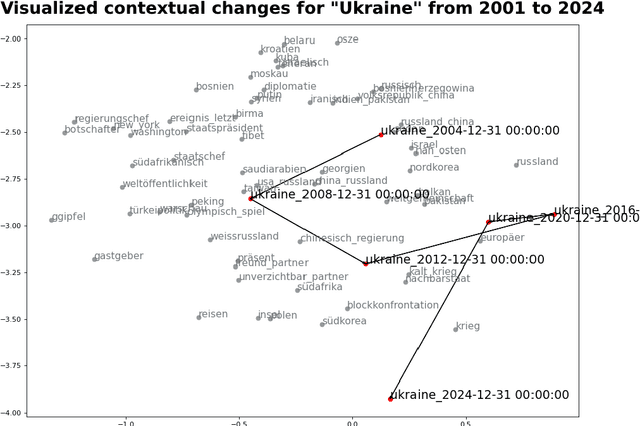
Text data is inherently temporal. The meaning of words and phrases changes over time, and the context in which they are used is constantly evolving. This is not just true for social media data, where the language used is rapidly influenced by current events, memes and trends, but also for journalistic, economic or political text data. Most NLP techniques however consider the corpus at hand to be homogenous in regard to time. This is a simplification that can lead to biased results, as the meaning of words and phrases can change over time. For instance, running a classic Latent Dirichlet Allocation on a corpus that spans several years is not enough to capture changes in the topics over time, but only portraits an "average" topic distribution over the whole time span. Researchers have developed a number of tools for analyzing text data over time. However, these tools are often scattered across different packages and libraries, making it difficult for researchers to use them in a consistent and reproducible way. The ttta package is supposed to serve as a collection of tools for analyzing text data over time.