 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of Consensus-Based Particle Methods for Nonconvex Bi-Level Optimization
May 19, 2026In this paper, we study a consensus-based optimization method for nonconvex bi-level optimization, where the objective is to minimize an upper-level function over the set of global minimizers of a lower-level problem. The proposed approach is derivative-free, and constructs its consensus point via smooth quantile selection combined with a Gibbs-type Laplace approximation. We establish convergence guarantees for both the associated \textit{mean-field} dynamics and its \textit{finite-particle} approximation. In particular, under suitable assumptions on smooth quantile localization, error bounds, and stability, we show that the mean-field law reaches any arbitrary prescribed Wasserstein neighborhood of the target bi-level solution with an explicit exponential rate up to the hitting time. Numerical experiments on a two-dimensional constrained problem and neural network training further support the theoretical results.
Consensus-based optimization (CBO): Towards Global Optimality in Robotics
Feb 06, 2026Zero-order optimization has recently received significant attention for designing optimal trajectories and policies for robotic systems. However, most existing methods (e.g., MPPI, CEM, and CMA-ES) are local in nature, as they rely on gradient estimation. In this paper, we introduce consensus-based optimization (CBO) to robotics, which is guaranteed to converge to a global optimum under mild assumptions. We provide theoretical analysis and illustrative examples that give intuition into the fundamental differences between CBO and existing methods. To demonstrate the scalability of CBO for robotics problems, we consider three challenging trajectory optimization scenarios: (1) a long-horizon problem for a simple system, (2) a dynamic balance problem for a highly underactuated system, and (3) a high-dimensional problem with only a terminal cost. Our results show that CBO is able to achieve lower costs with respect to existing methods on all three challenging settings. This opens a new framework to study global trajectory optimization in robotics.
SURE: Safe Uncertainty-Aware Robot-Environment Interaction using Trajectory Optimization
Feb 06, 2026Robotic tasks involving contact interactions pose significant challenges for trajectory optimization due to discontinuous dynamics. Conventional formulations typically assume deterministic contact events, which limit robustness and adaptability in real-world settings. In this work, we propose SURE, a robust trajectory optimization framework that explicitly accounts for contact timing uncertainty. By allowing multiple trajectories to branch from possible pre-impact states and later rejoin a shared trajectory, SURE achieves both robustness and computational efficiency within a unified optimization framework. We evaluate SURE on two representative tasks with unknown impact times. In a cart-pole balancing task involving uncertain wall location, SURE achieves an average improvement of 21.6% in success rate when branch switching is enabled during control. In an egg-catching experiment using a robotic manipulator, SURE improves the success rate by 40%. These results demonstrate that SURE substantially enhances robustness compared to conventional nominal formulations.
Addressing pitfalls in implicit unobserved confounding synthesis using explicit block hierarchical ancestral sampling
Mar 12, 2025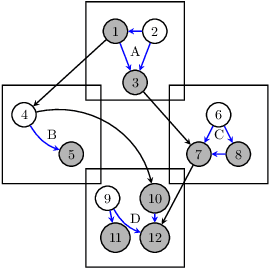
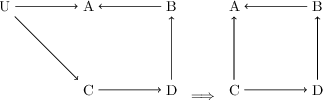
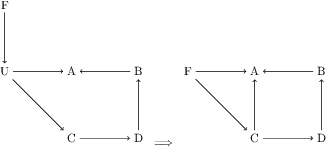
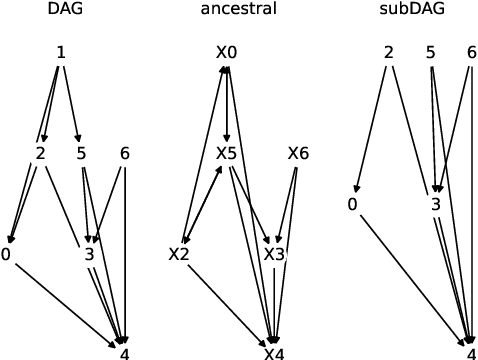
Unbiased data synthesis is crucial for evaluating causal discovery algorithms in the presence of unobserved confounding, given the scarcity of real-world datasets. A common approach, implicit parameterization, encodes unobserved confounding by modifying the off-diagonal entries of the idiosyncratic covariance matrix while preserving positive definiteness. Within this approach, state-of-the-art protocols have two distinct issues that hinder unbiased sampling from the complete space of causal models: first, the use of diagonally dominant constructions, which restrict the spectrum of partial correlation matrices; and second, the restriction of possible graphical structures when sampling bidirected edges, unnecessarily ruling out valid causal models. To address these limitations, we propose an improved explicit modeling approach for unobserved confounding, leveraging block-hierarchical ancestral generation of ground truth causal graphs. Algorithms for converting the ground truth DAG into ancestral graph is provided so that the output of causal discovery algorithms could be compared with. We prove that our approach fully covers the space of causal models, including those generated by the implicit parameterization, thus enabling more robust evaluation of methods for causal discovery and inference.
DomainLab: A modular Python package for domain generalization in deep learning
Mar 21, 2024
Poor generalization performance caused by distribution shifts in unseen domains often hinders the trustworthy deployment of deep neural networks. Many domain generalization techniques address this problem by adding a domain invariant regularization loss terms during training. However, there is a lack of modular software that allows users to combine the advantages of different methods with minimal effort for reproducibility. DomainLab is a modular Python package for training user specified neural networks with composable regularization loss terms. Its decoupled design allows the separation of neural networks from regularization loss construction. Hierarchical combinations of neural networks, different domain generalization methods, and associated hyperparameters, can all be specified together with other experimental setup in a single configuration file. Hierarchical combinations of neural networks, different domain generalization methods, and associated hyperparameters, can all be specified together with other experimental setup in a single configuration file. In addition, DomainLab offers powerful benchmarking functionality to evaluate the generalization performance of neural networks in out-of-distribution data. The package supports running the specified benchmark on an HPC cluster or on a standalone machine. The package is well tested with over 95 percent coverage and well documented. From the user perspective, it is closed to modification but open to extension. The package is under the MIT license, and its source code, tutorial and documentation can be found at https://github.com/marrlab/DomainLab.
M-HOF-Opt: Multi-Objective Hierarchical Output Feedback Optimization via Multiplier Induced Loss Landscape Scheduling
Mar 20, 2024



When a neural network parameterized loss function consists of many terms, the combinatorial choice of weight multipliers during the optimization process forms a challenging problem. To address this, we proposed a probabilistic graphical model (PGM) for the joint model parameter and multiplier evolution process, with a hypervolume based likelihood that promotes multi-objective descent of each loss term. The corresponding parameter and multiplier estimation as a sequential decision process is then cast into an optimal control problem, where the multi-objective descent goal is dispatched hierarchically into a series of constraint optimization sub-problems. The sub-problem constraint automatically adapts itself according to Pareto dominance and serves as the setpoint for the low level multiplier controller to schedule loss landscapes via output feedback of each loss term. Our method is multiplier-free and operates at the timescale of epochs, thus saves tremendous computational resources compared to full training cycle multiplier tuning. We applied it to domain invariant variational auto-encoding with 6 loss terms on the PACS domain generalization task, and observed robust performance across a range of controller hyperparameters, as well as different multiplier initial conditions, outperforming other multiplier scheduling methods. We offered modular implementation of our method, admitting custom definition of many loss terms for applying our multi-objective hierarchical output feedback training scheme to other deep learning fields.
Joint Learning of Network Topology and Opinion Dynamics Based on Bandit Algorithms
Jun 25, 2023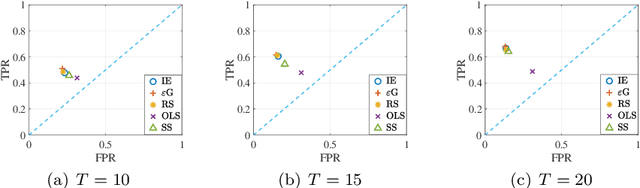
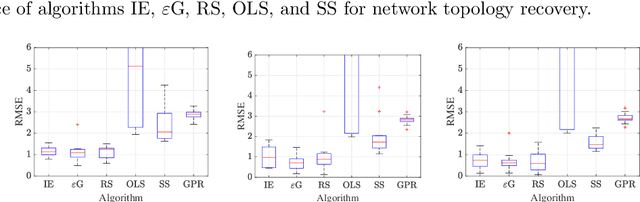
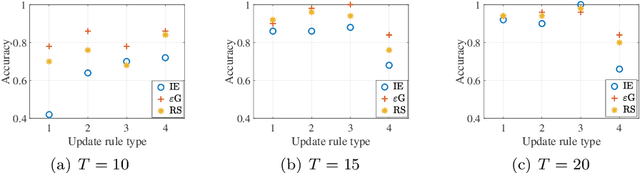
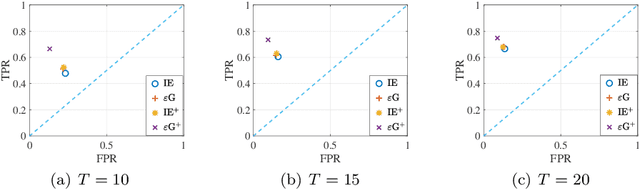
We study joint learning of network topology and a mixed opinion dynamics, in which agents may have different update rules. Such a model captures the diversity of real individual interactions. We propose a learning algorithm based on multi-armed bandit algorithms to address the problem. The goal of the algorithm is to find each agent's update rule from several candidate rules and to learn the underlying network. At each iteration, the algorithm assumes that each agent has one of the updated rules and then modifies network estimates to reduce validation error. Numerical experiments show that the proposed algorithm improves initial estimates of the network and update rules, decreases prediction error, and performs better than other methods such as sparse linear regression and Gaussian process regression.
Learning-based Design of Luenberger Observers for Autonomous Nonlinear Systems
Oct 04, 2022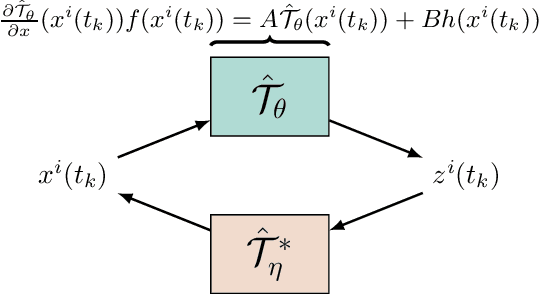
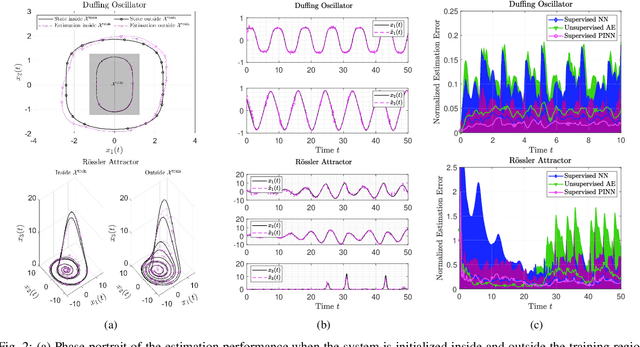
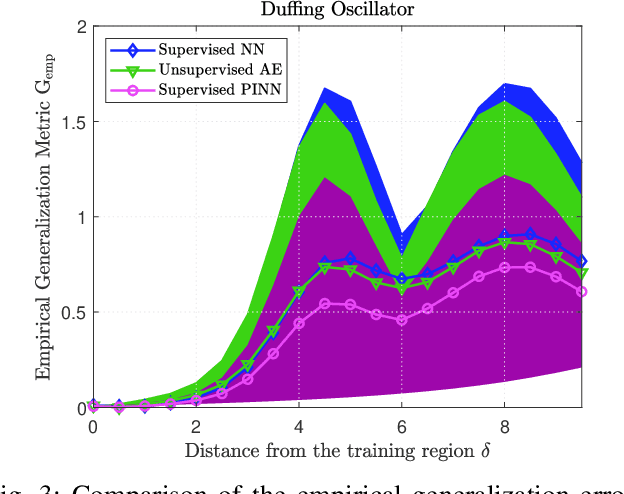
The design of Luenberger observers for nonlinear systems involves state transformation to another coordinate system where the dynamics are asymptotically stable and linear up to output injection. The observer then provides a state estimate in the original coordinates by inverting the transformation map. For general nonlinear systems, however, the main challenge is to find such a transformation and to ensure that it is injective. This paper addresses this challenge by proposing a learning method that employs supervised physics-informed neural networks to approximate both the transformation and its inverse. It is shown that the proposed method exhibits better generalization capabilities than other contemporary methods. Moreover, the observer is shown to be robust under the neural network's approximation error and the system uncertainties.
Hierarchical Variational Auto-Encoding for Unsupervised Domain Generalization
Feb 22, 2021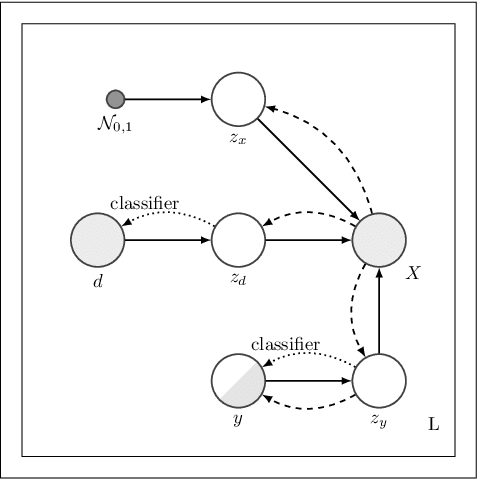

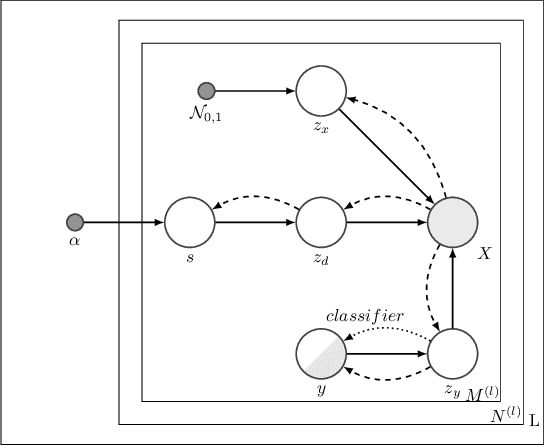

We address the task of domain generalization, where the goal is to train a predictive model based on a number of domains such that it is able to generalize to a new, previously unseen domain. We choose a generative approach within the framework of variational autoencoders and propose an unsupervised algorithm that is able to generalize to new domains without supervision. We show that our method is able to learn representations that disentangle domain-specific information from class-label specific information even in complex settings where an unobserved substructure is present in domains. Our interpretable method outperforms previously proposed generative algorithms for domain generalization and achieves competitive performance compared to state-of-the-art approaches, which are based on complex image-processing steps, on the standard domain generalization benchmark dataset PACS. Additionally, we proposed weak domain supervision which can further increase the performance of our algorithm in the PACS dataset.
More Industry-friendly: Federated Learning with High Efficient Design
Dec 16, 2020
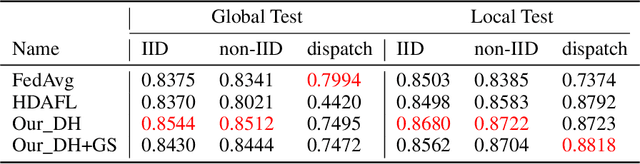


Although many achievements have been made since Google threw out the paradigm of federated learning (FL), there still exists much room for researchers to optimize its efficiency. In this paper, we propose a high efficient FL method equipped with the double head design aiming for personalization optimization over non-IID dataset, and the gradual model sharing design for communication saving. Experimental results show that, our method has more stable accuracy performance and better communication efficient across various data distributions than other state of art methods (SOTAs), makes it more industry-friendly.