 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCSI -- An improved measure of cluster separability based on separation and connectedness
Oct 19, 2023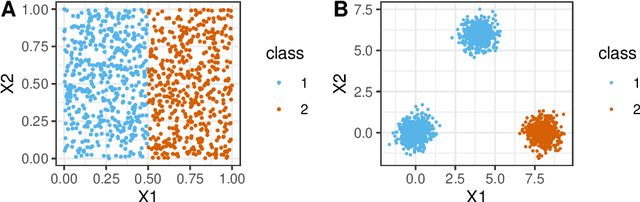
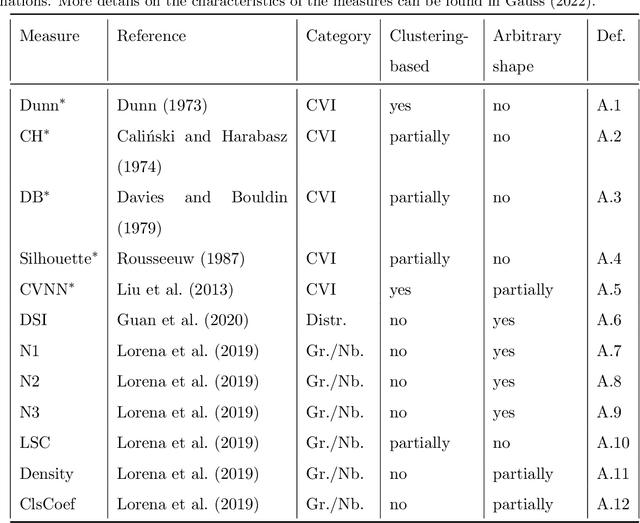
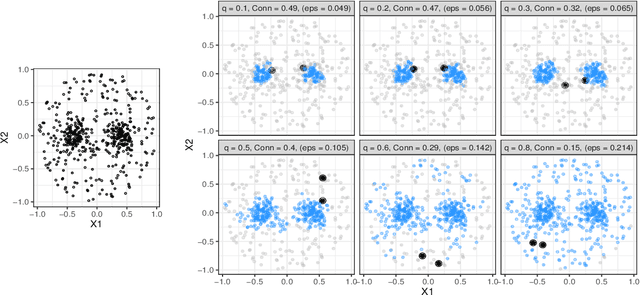
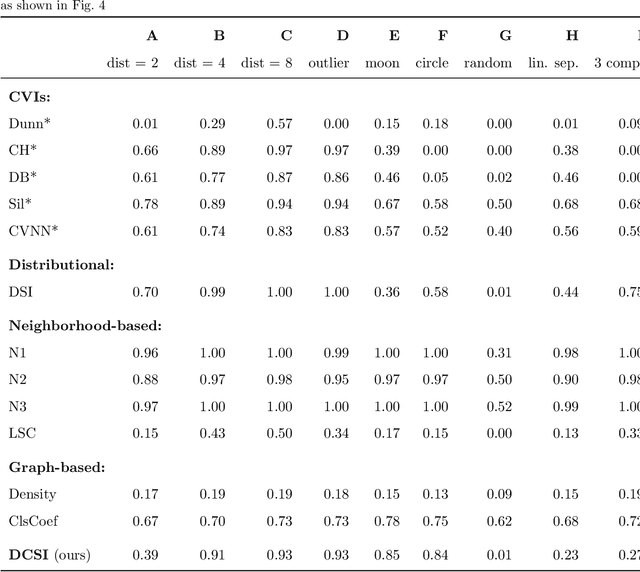
Whether class labels in a given data set correspond to meaningful clusters is crucial for the evaluation of clustering algorithms using real-world data sets. This property can be quantified by separability measures. A review of the existing literature shows that neither classification-based complexity measures nor cluster validity indices (CVIs) adequately incorporate the central aspects of separability for density-based clustering: between-class separation and within-class connectedness. A newly developed measure (density cluster separability index, DCSI) aims to quantify these two characteristics and can also be used as a CVI. Extensive experiments on synthetic data indicate that DCSI correlates strongly with the performance of DBSCAN measured via the adjusted rand index (ARI) but lacks robustness when it comes to multi-class data sets with overlapping classes that are ill-suited for density-based hard clustering. Detailed evaluation on frequently used real-world data sets shows that DCSI can correctly identify touching or overlapping classes that do not form meaningful clusters.
Enhancing cluster analysis via topological manifold learning
Jul 01, 2022
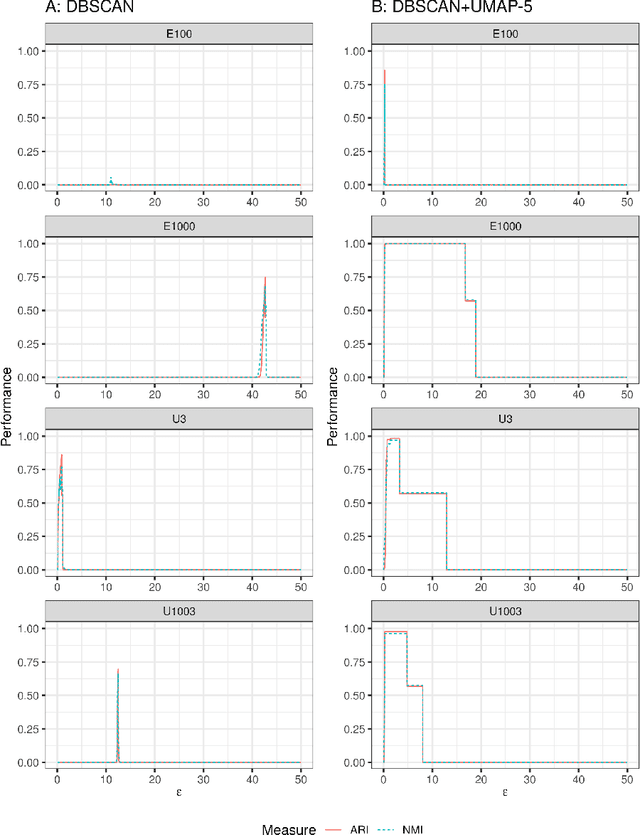
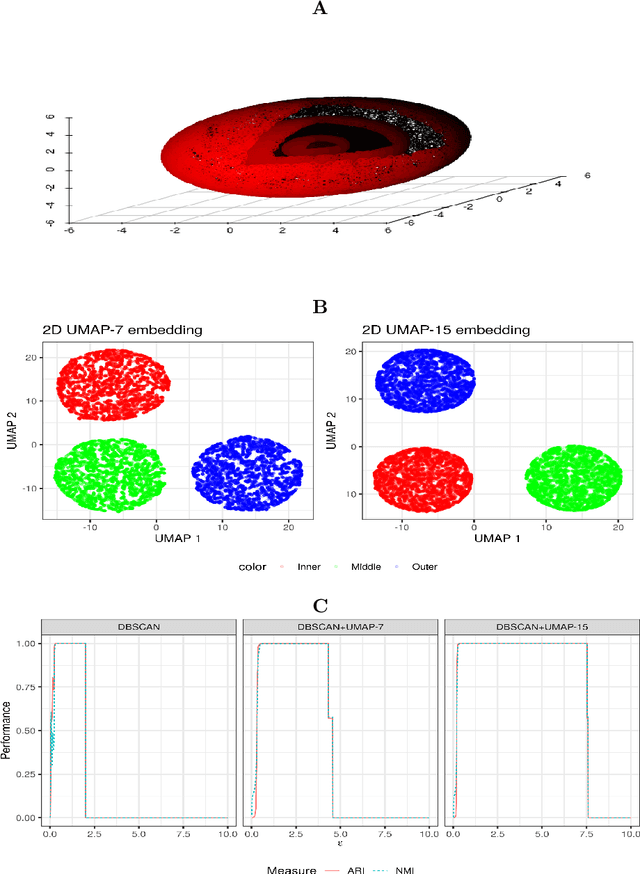

We discuss topological aspects of cluster analysis and show that inferring the topological structure of a dataset before clustering it can considerably enhance cluster detection: theoretical arguments and empirical evidence show that clustering embedding vectors, representing the structure of a data manifold instead of the observed feature vectors themselves, is highly beneficial. To demonstrate, we combine manifold learning method UMAP for inferring the topological structure with density-based clustering method DBSCAN. Synthetic and real data results show that this both simplifies and improves clustering in a diverse set of low- and high-dimensional problems including clusters of varying density and/or entangled shapes. Our approach simplifies clustering because topological pre-processing consistently reduces parameter sensitivity of DBSCAN. Clustering the resulting embeddings with DBSCAN can then even outperform complex methods such as SPECTACL and ClusterGAN. Finally, our investigation suggests that the crucial issue in clustering does not appear to be the nominal dimension of the data or how many irrelevant features it contains, but rather how \textit{separable} the clusters are in the ambient observation space they are embedded in, which is usually the (high-dimensional) Euclidean space defined by the features of the data. Our approach is successful because we perform the cluster analysis after projecting the data into a more suitable space that is optimized for separability, in some sense.
A geometric framework for outlier detection in high-dimensional data
Jul 01, 2022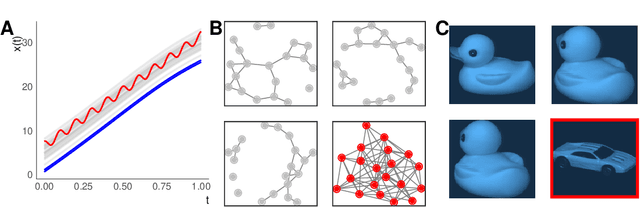

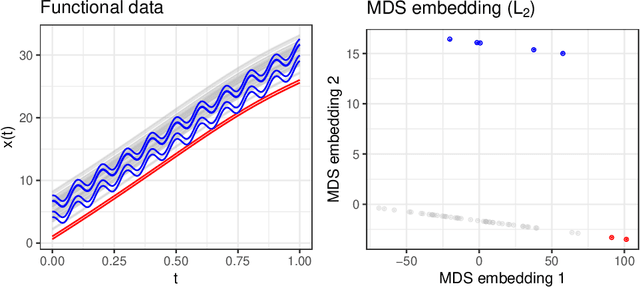
Outlier or anomaly detection is an important task in data analysis. We discuss the problem from a geometrical perspective and provide a framework that exploits the metric structure of a data set. Our approach rests on the manifold assumption, i.e., that the observed, nominally high-dimensional data lie on a much lower dimensional manifold and that this intrinsic structure can be inferred with manifold learning methods. We show that exploiting this structure significantly improves the detection of outlying observations in high-dimensional data. We also suggest a novel, mathematically precise, and widely applicable distinction between distributional and structural outliers based on the geometry and topology of the data manifold that clarifies conceptual ambiguities prevalent throughout the literature. Our experiments focus on functional data as one class of structured high-dimensional data, but the framework we propose is completely general and we include image and graph data applications. Our results show that the outlier structure of high-dimensional and non-tabular data can be detected and visualized using manifold learning methods and quantified using standard outlier scoring methods applied to the manifold embedding vectors.
A geometric perspective on functional outlier detection
Sep 14, 2021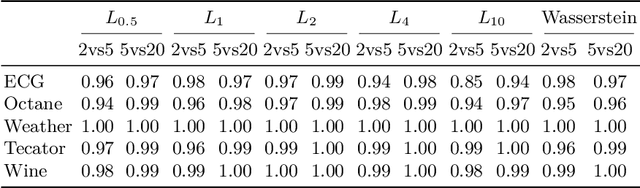
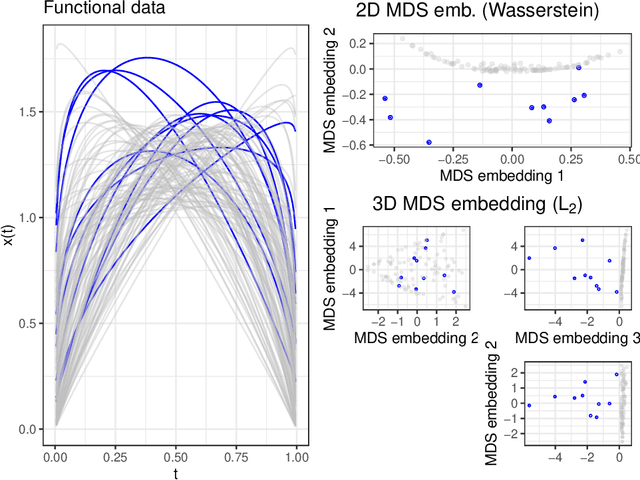
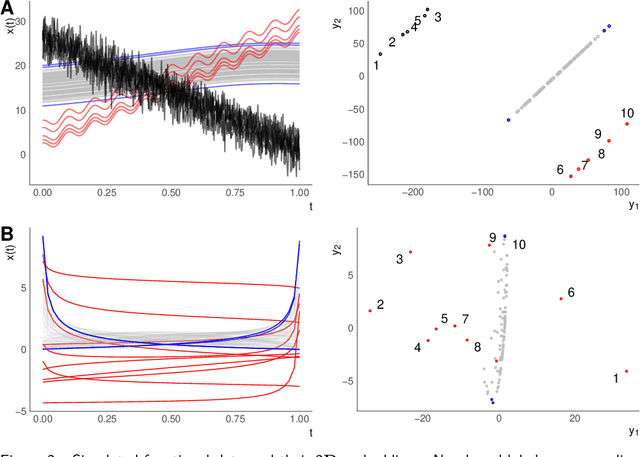
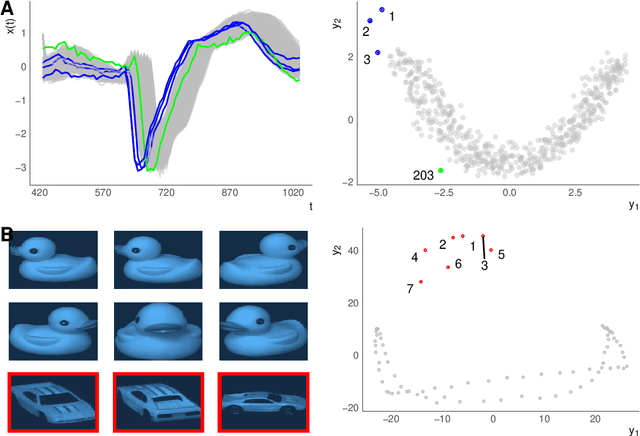
We consider functional outlier detection from a geometric perspective, specifically: for functional data sets drawn from a functional manifold which is defined by the data's modes of variation in amplitude and phase. Based on this manifold, we develop a conceptualization of functional outlier detection that is more widely applicable and realistic than previously proposed. Our theoretical and experimental analyses demonstrate several important advantages of this perspective: It considerably improves theoretical understanding and allows to describe and analyse complex functional outlier scenarios consistently and in full generality, by differentiating between structurally anomalous outlier data that are off-manifold and distributionally outlying data that are on-manifold but at its margins. This improves practical feasibility of functional outlier detection: We show that simple manifold learning methods can be used to reliably infer and visualize the geometric structure of functional data sets. We also show that standard outlier detection methods requiring tabular data inputs can be applied to functional data very successfully by simply using their vector-valued representations learned from manifold learning methods as input features. Our experiments on synthetic and real data sets demonstrate that this approach leads to outlier detection performances at least on par with existing functional data-specific methods in a large variety of settings, without the highly specialized, complex methodology and narrow domain of application these methods often entail.
Developing Open Source Educational Resources for Machine Learning and Data Science
Aug 10, 2021Education should not be a privilege but a common good. It should be openly accessible to everyone, with as few barriers as possible; even more so for key technologies such as Machine Learning (ML) and Data Science (DS). Open Educational Resources (OER) are a crucial factor for greater educational equity. In this paper, we describe the specific requirements for OER in ML and DS and argue that it is especially important for these fields to make source files publicly available, leading to Open Source Educational Resources (OSER). We present our view on the collaborative development of OSER, the challenges this poses, and first steps towards their solutions. We outline how OSER can be used for blended learning scenarios and share our experiences in university education. Finally, we discuss additional challenges such as credit assignment or granting certificates.
Unsupervised Functional Data Analysis via Nonlinear Dimension Reduction
Dec 22, 2020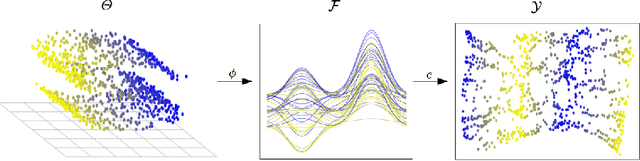

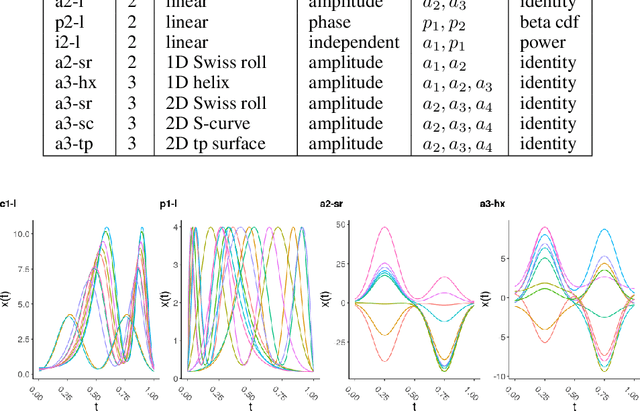
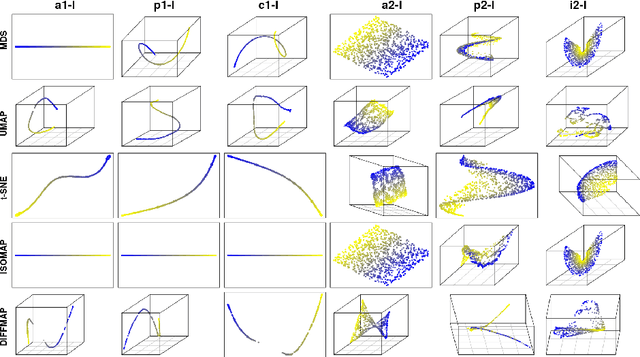
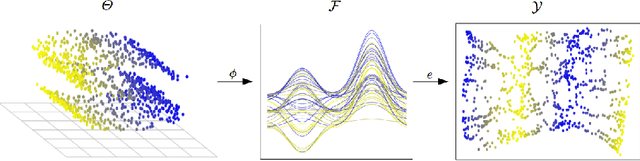
In recent years, manifold methods have moved into focus as tools for dimension reduction. Assuming that the high-dimensional data actually lie on or close to a low-dimensional nonlinear manifold, these methods have shown convincing results in several settings. This manifold assumption is often reasonable for functional data, i.e., data representing continuously observed functions, as well. However, the performance of manifold methods recently proposed for tabular or image data has not been systematically assessed in the case of functional data yet. Moreover, it is unclear how to evaluate the quality of learned embeddings that do not yield invertible mappings, since the reconstruction error cannot be used as a performance measure for such representations. In this work, we describe and investigate the specific challenges for nonlinear dimension reduction posed by the functional data setting. The contributions of the paper are three-fold: First of all, we define a theoretical framework which allows to systematically assess specific challenges that arise in the functional data context, transfer several nonlinear dimension reduction methods for tabular and image data to functional data, and show that manifold methods can be used successfully in this setting. Secondly, we subject performance assessment and tuning strategies to a thorough and systematic evaluation based on several different functional data settings and point out some previously undescribed weaknesses and pitfalls which can jeopardize reliable judgment of embedding quality. Thirdly, we propose a nuanced approach to make trustworthy decisions for or against competing nonconforming embeddings more objectively.
A General Machine Learning Framework for Survival Analysis
Jun 27, 2020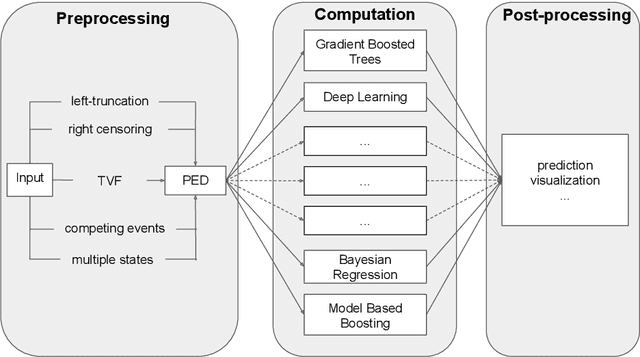

The modeling of time-to-event data, also known as survival analysis, requires specialized methods that can deal with censoring and truncation, time-varying features and effects, and that extend to settings with multiple competing events. However, many machine learning methods for survival analysis only consider the standard setting with right-censored data and proportional hazards assumption. The methods that do provide extensions usually address at most a subset of these challenges and often require specialized software that can not be integrated into standard machine learning workflows directly. In this work, we present a very general machine learning framework for time-to-event analysis that uses a data augmentation strategy to reduce complex survival tasks to standard Poisson regression tasks. This reformulation is based on well developed statistical theory. With the proposed approach, any algorithm that can optimize a Poisson (log-)likelihood, such as gradient boosted trees, deep neural networks, model-based boosting and many more can be used in the context of time-to-event analysis. The proposed technique does not require any assumptions with respect to the distribution of event times or the functional shapes of feature and interaction effects. Based on the proposed framework we develop new methods that are competitive with specialized state of the art approaches in terms of accuracy, and versatility, but with comparatively small investments of programming effort or requirements for specialized methodological know-how.
Benchmarking time series classification -- Functional data vs machine learning approaches
Nov 18, 2019
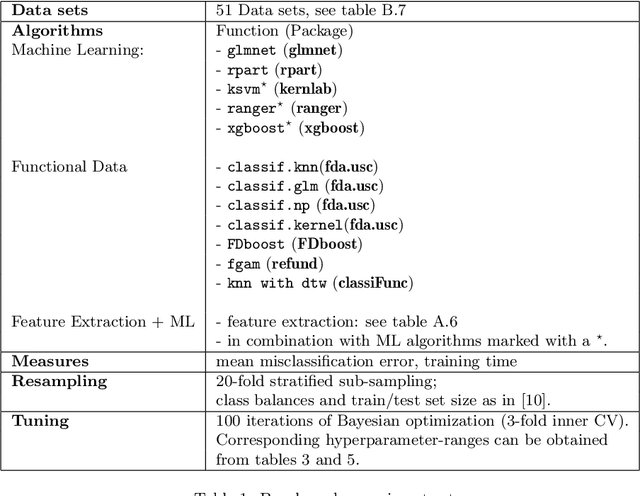
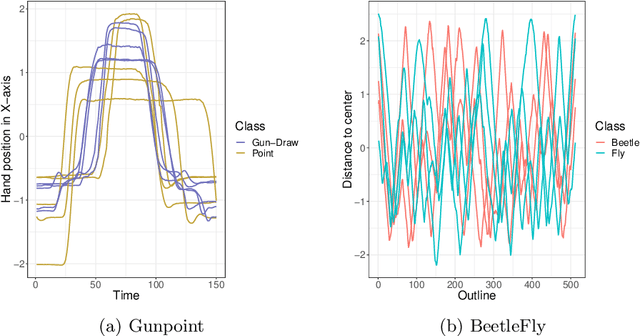
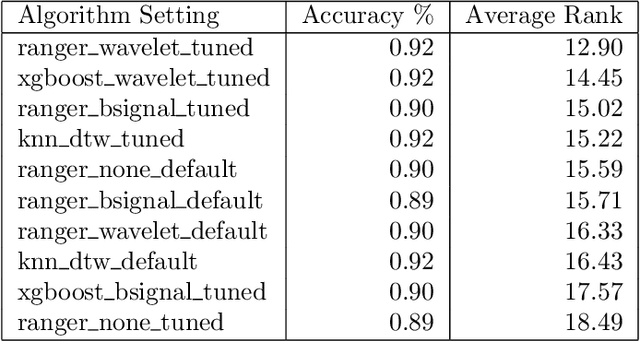
Time series classification problems have drawn increasing attention in the machine learning and statistical community. Closely related is the field of functional data analysis (FDA): it refers to the range of problems that deal with the analysis of data that is continuously indexed over some domain. While often employing different methods, both fields strive to answer similar questions, a common example being classification or regression problems with functional covariates. We study methods from functional data analysis, such as functional generalized additive models, as well as functionality to concatenate (functional-) feature extraction or basis representations with traditional machine learning algorithms like support vector machines or classification trees. In order to assess the methods and implementations, we run a benchmark on a wide variety of representative (time series) data sets, with in-depth analysis of empirical results, and strive to provide a reference ranking for which method(s) to use for non-expert practitioners. Additionally, we provide a software framework in R for functional data analysis for supervised learning, including machine learning and more linear approaches from statistics. This allows convenient access, and in connection with the machine-learning toolbox mlr, those methods can now also be tuned and benchmarked.