 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGADFormer: An Attention-based Model for Group Anomaly Detection on Trajectories
Mar 17, 2023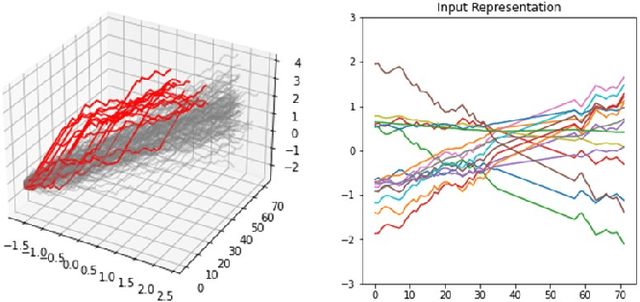
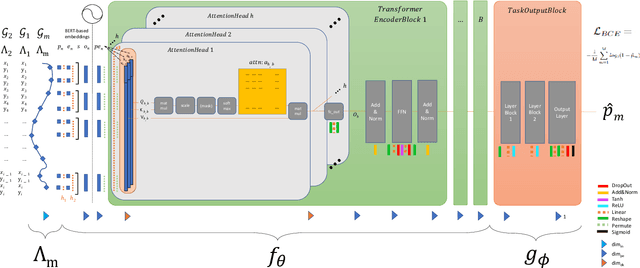

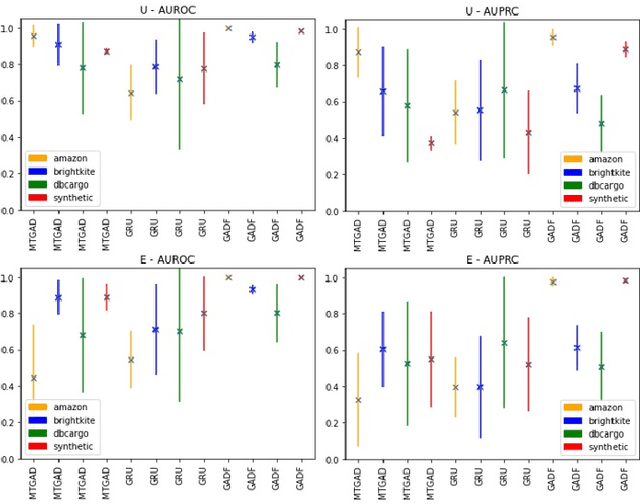
Group Anomaly Detection (GAD) reveals anomalous behavior among groups consisting of multiple member instances, which are, individually considered, not necessarily anomalous. This task is of major importance across multiple disciplines, in which also sequences like trajectories can be considered as a group. However, with increasing amount and heterogenity of group members, actual abnormal groups get harder to detect, especially in an unsupervised or semi-supervised setting. Recurrent Neural Networks are well established deep sequence models, but recent works have shown that their performance can decrease with increasing sequence lengths. Hence, we introduce with this paper GADFormer, a GAD specific BERT architecture, capable to perform attention-based Group Anomaly Detection on trajectories in an unsupervised and semi-supervised setting. We show formally and experimentally how trajectory outlier detection can be realized as an attention-based Group Anomaly Detection problem. Furthermore, we introduce a Block Attention-anomaly Score (BAS) to improve the interpretability of transformer encoder blocks for GAD. In addition to that, synthetic trajectory generation allows us to optimize the training for domain-specific GAD. In extensive experiments we investigate our approach versus GRU in their robustness for trajectory noise and novelties on synthetic and real world datasets.
Fact or Artifact? Revise Layer-wise Relevance Propagation on various ANN Architectures
Feb 23, 2023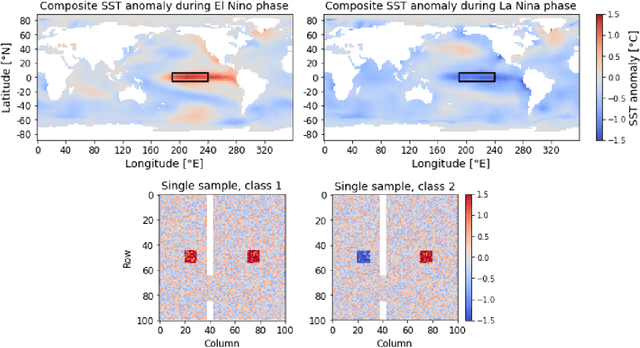
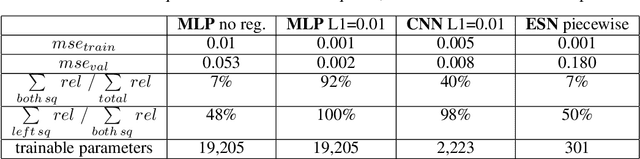
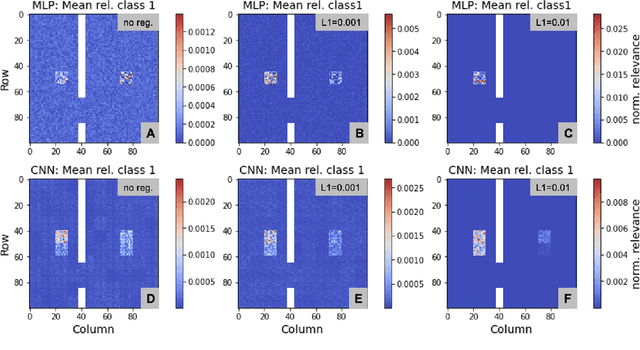

Layer-wise relevance propagation (LRP) is a widely used and powerful technique to reveal insights into various artificial neural network (ANN) architectures. LRP is often used in the context of image classification. The aim is to understand, which parts of the input sample have highest relevance and hence most influence on the model prediction. Relevance can be traced back through the network to attribute a certain score to each input pixel. Relevance scores are then combined and displayed as heat maps and give humans an intuitive visual understanding of classification models. Opening the black box to understand the classification engine in great detail is essential for domain experts to gain trust in ANN models. However, there are pitfalls in terms of model-inherent artifacts included in the obtained relevance maps, that can easily be missed. But for a valid interpretation, these artifacts must not be ignored. Here, we apply and revise LRP on various ANN architectures trained as classifiers on geospatial and synthetic data. Depending on the network architecture, we show techniques to control model focus and give guidance to improve the quality of obtained relevance maps to separate facts from artifacts.
CoMadOut -- A Robust Outlier Detection Algorithm based on CoMAD
Nov 23, 2022Unsupervised learning methods are well established in the area of anomaly detection and achieve state of the art performances on outlier data sets. Outliers play a significant role, since they bear the potential to distort the predictions of a machine learning algorithm on a given data set. Especially among PCA-based methods, outliers have an additional destructive potential regarding the result: they may not only distort the orientation and translation of the principal components, they also make it more complicated to detect outliers. To address this problem, we propose the robust outlier detection algorithm CoMadOut, which satisfies two required properties: (1) being robust towards outliers and (2) detecting them. Our outlier detection method using coMAD-PCA defines dependent on its variant an inlier region with a robust noise margin by measures of in-distribution (ID) and out-of-distribution (OOD). These measures allow distribution based outlier scoring for each principal component, and thus, for an appropriate alignment of the decision boundary between normal and abnormal instances. Experiments comparing CoMadOut with traditional, deep and other comparable robust outlier detection methods showed that the performance of the introduced CoMadOut approach is competitive to well established methods related to average precision (AP), recall and area under the receiver operating characteristic (AUROC) curve. In summary our approach can be seen as a robust alternative for outlier detection tasks.
It's a long way! Layer-wise Relevance Propagation for Echo State Networks applied to Earth System Variability
Oct 18, 2022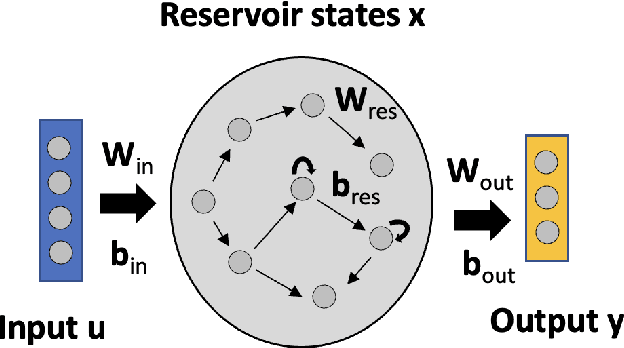
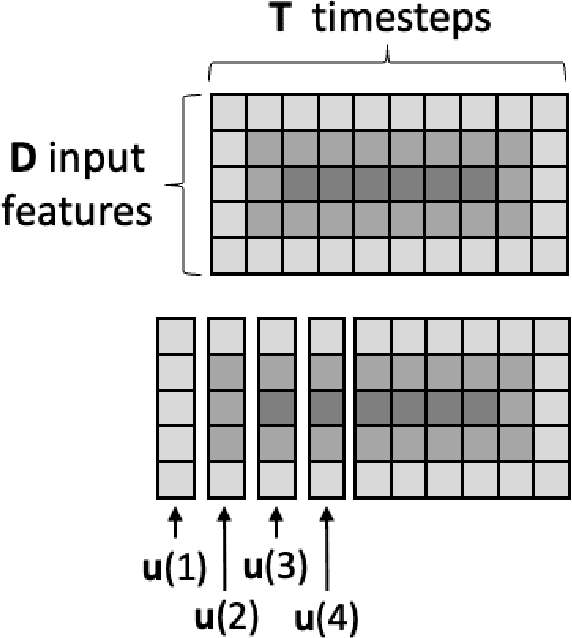
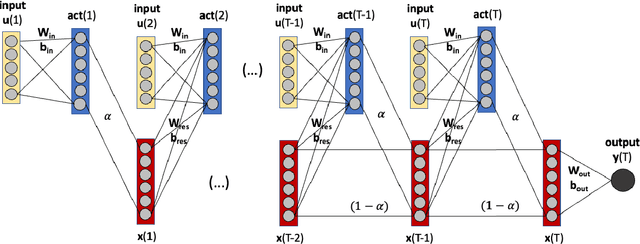
Artificial neural networks (ANNs) are known to be powerful methods for many hard problems (e.g. image classification, speech recognition or time series prediction). However, these models tend to produce black-box results and are often difficult to interpret. Layer-wise relevance propagation (LRP) is a widely used technique to understand how ANN models come to their conclusion and to understand what a model has learned. Here, we focus on Echo State Networks (ESNs) as a certain type of recurrent neural networks, also known as reservoir computing. ESNs are easy to train and only require a small number of trainable parameters, but are still black-box models. We show how LRP can be applied to ESNs in order to open the black-box. We also show how ESNs can be used not only for time series prediction but also for image classification: Our ESN model serves as a detector for El Nino Southern Oscillation (ENSO) from sea surface temperature anomalies. ENSO is actually a well-known problem and has been extensively discussed before. But here we use this simple problem to demonstrate how LRP can significantly enhance the explainablility of ESNs.
Enhancing cluster analysis via topological manifold learning
Jul 01, 2022
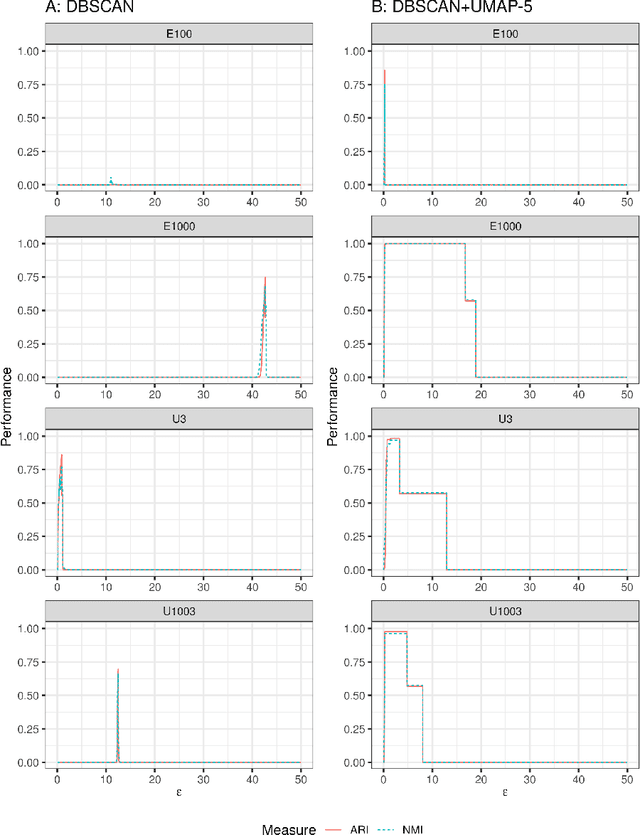
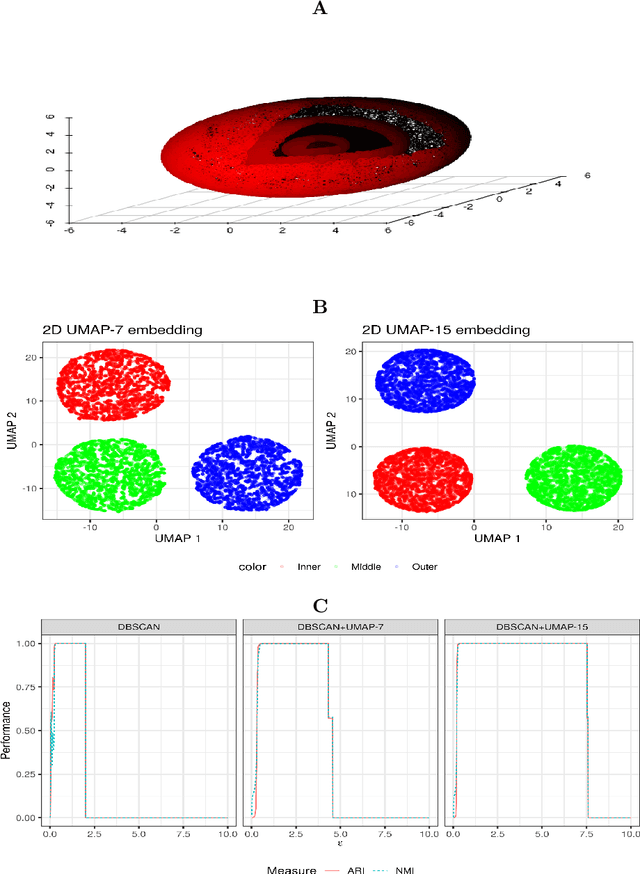

We discuss topological aspects of cluster analysis and show that inferring the topological structure of a dataset before clustering it can considerably enhance cluster detection: theoretical arguments and empirical evidence show that clustering embedding vectors, representing the structure of a data manifold instead of the observed feature vectors themselves, is highly beneficial. To demonstrate, we combine manifold learning method UMAP for inferring the topological structure with density-based clustering method DBSCAN. Synthetic and real data results show that this both simplifies and improves clustering in a diverse set of low- and high-dimensional problems including clusters of varying density and/or entangled shapes. Our approach simplifies clustering because topological pre-processing consistently reduces parameter sensitivity of DBSCAN. Clustering the resulting embeddings with DBSCAN can then even outperform complex methods such as SPECTACL and ClusterGAN. Finally, our investigation suggests that the crucial issue in clustering does not appear to be the nominal dimension of the data or how many irrelevant features it contains, but rather how \textit{separable} the clusters are in the ambient observation space they are embedded in, which is usually the (high-dimensional) Euclidean space defined by the features of the data. Our approach is successful because we perform the cluster analysis after projecting the data into a more suitable space that is optimized for separability, in some sense.
On Event-Driven Knowledge Graph Completion in Digital Factories
Sep 08, 2021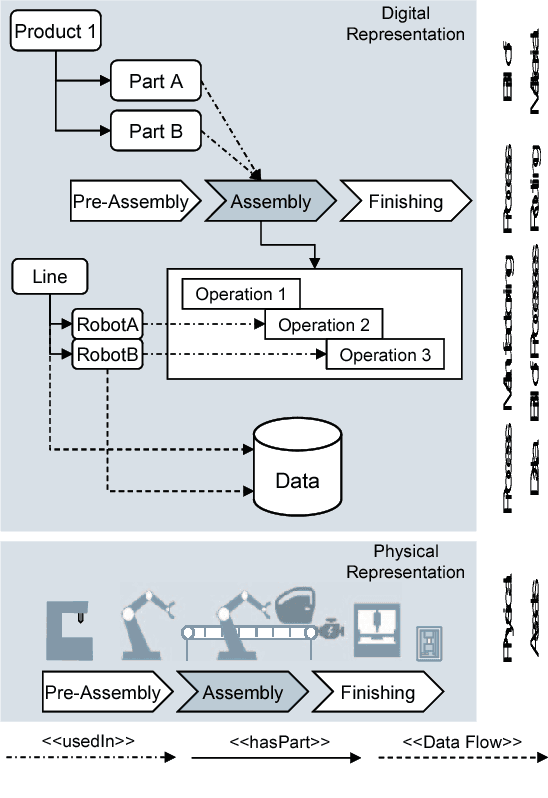
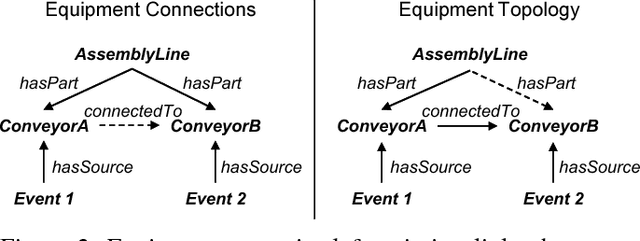


Smart factories are equipped with machines that can sense their manufacturing environments, interact with each other, and control production processes. Smooth operation of such factories requires that the machines and engineering personnel that conduct their monitoring and diagnostics share a detailed common industrial knowledge about the factory, e.g., in the form of knowledge graphs. Creation and maintenance of such knowledge is expensive and requires automation. In this work we show how machine learning that is specifically tailored towards industrial applications can help in knowledge graph completion. In particular, we show how knowledge completion can benefit from event logs that are common in smart factories. We evaluate this on the knowledge graph from a real world-inspired smart factory with encouraging results.
Minimizing the Number of Matching Queries for Object Retrieval
Aug 18, 2015

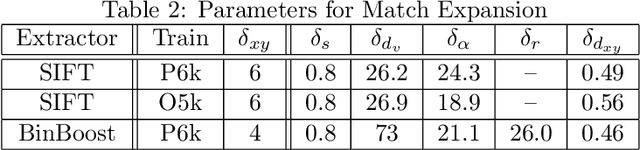

To increase the computational efficiency of interest-point based object retrieval, researchers have put remarkable research efforts into improving the efficiency of kNN-based feature matching, pursuing to match thousands of features against a database within fractions of a second. However, due to the high-dimensional nature of image features that reduces the effectivity of index structures (curse of dimensionality), due to the vast amount of features stored in image databases (images are often represented by up to several thousand features), this ultimate goal demanded to trade query runtimes for query precision. In this paper we address an approach complementary to indexing in order to improve the runtimes of retrieval by querying only the most promising keypoint descriptors, as this affects matching runtimes linearly and can therefore lead to increased efficiency. As this reduction of kNN queries reduces the number of tentative correspondences, a loss of query precision is minimized by an additional image-level correspondence generation stage with a computational performance independent of the underlying indexing structure. We evaluate such an adaption of the standard recognition pipeline on a variety of datasets using both SIFT and state-of-the-art binary descriptors. Our results suggest that decreasing the number of queried descriptors does not necessarily imply a reduction in the result quality as long as alternative ways of increasing query recall (by thoroughly selecting k) and MAP (using image-level correspondence generation) are considered.