 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupposedly Equivalent Facts That Aren't? Entity Frequency in Pre-training Induces Asymmetry in LLMs
Mar 28, 2025Understanding and mitigating hallucinations in Large Language Models (LLMs) is crucial for ensuring reliable content generation. While previous research has primarily focused on "when" LLMs hallucinate, our work explains "why" and directly links model behaviour to the pre-training data that forms their prior knowledge. Specifically, we demonstrate that an asymmetry exists in the recognition of logically equivalent facts, which can be attributed to frequency discrepancies of entities appearing as subjects versus objects. Given that most pre-training datasets are inaccessible, we leverage the fully open-source OLMo series by indexing its Dolma dataset to estimate entity frequencies. Using relational facts (represented as triples) from Wikidata5M, we construct probing datasets to isolate this effect. Our experiments reveal that facts with a high-frequency subject and a low-frequency object are better recognised than their inverse, despite their logical equivalence. The pattern reverses in low-to-high frequency settings, and no statistically significant asymmetry emerges when both entities are high-frequency. These findings highlight the influential role of pre-training data in shaping model predictions and provide insights for inferring the characteristics of pre-training data in closed or partially closed LLMs.
Relational Graph Convolutional Networks Do Not Learn Sound Rules
Aug 14, 2024



Graph neural networks (GNNs) are frequently used to predict missing facts in knowledge graphs (KGs). Motivated by the lack of explainability for the outputs of these models, recent work has aimed to explain their predictions using Datalog, a widely used logic-based formalism. However, such work has been restricted to certain subclasses of GNNs. In this paper, we consider one of the most popular GNN architectures for KGs, R-GCN, and we provide two methods to extract rules that explain its predictions and are sound, in the sense that each fact derived by the rules is also predicted by the GNN, for any input dataset. Furthermore, we provide a method that can verify that certain classes of Datalog rules are not sound for the R-GCN. In our experiments, we train R-GCNs on KG completion benchmarks, and we are able to verify that no Datalog rule is sound for these models, even though the models often obtain high to near-perfect accuracy. This raises some concerns about the ability of R-GCN models to generalise and about the explainability of their predictions. We further provide two variations to the training paradigm of R-GCN that encourage it to learn sound rules and find a trade-off between model accuracy and the number of learned sound rules.
Ontology Embedding: A Survey of Methods, Applications and Resources
Jun 16, 2024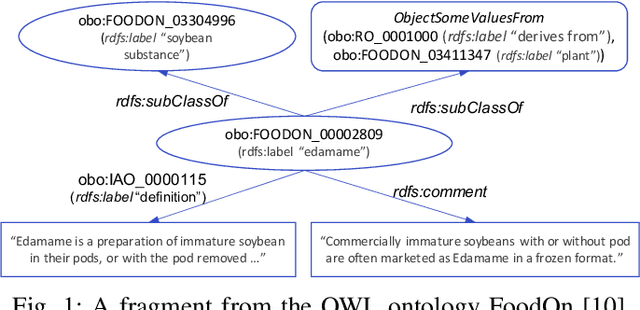
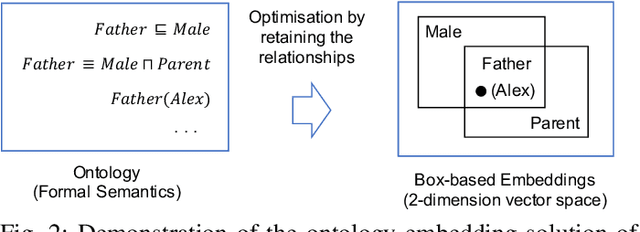
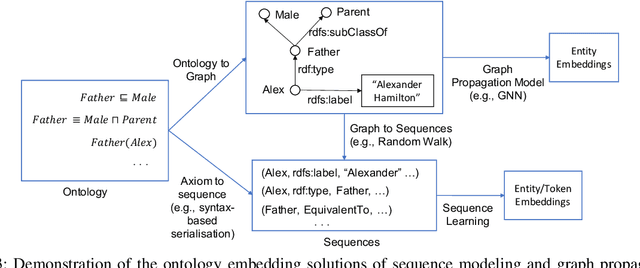
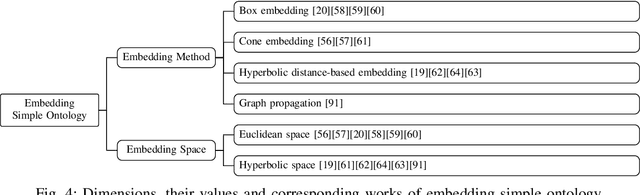
Ontologies are widely used for representing domain knowledge and meta data, playing an increasingly important role in Information Systems, the Semantic Web, Bioinformatics and many other domains. However, logical reasoning that ontologies can directly support are quite limited in learning, approximation and prediction. One straightforward solution is to integrate statistical analysis and machine learning. To this end, automatically learning vector representation for knowledge of an ontology i.e., ontology embedding has been widely investigated in recent years. Numerous papers have been published on ontology embedding, but a lack of systematic reviews hinders researchers from gaining a comprehensive understanding of this field. To bridge this gap, we write this survey paper, which first introduces different kinds of semantics of ontologies, and formally defines ontology embedding from the perspectives of both mathematics and machine learning, as well as its property of faithfulness. Based on this, it systematically categorises and analyses a relatively complete set of over 80 papers, according to the ontologies and semantics that they aim at, and their technical solutions including geometric modeling, sequence modeling and graph propagation. This survey also introduces the applications of ontology embedding in ontology engineering, machine learning augmentation and life sciences, presents a new library mOWL, and discusses the challenges and future directions.
A Language Model based Framework for New Concept Placement in Ontologies
Mar 04, 2024We investigate the task of inserting new concepts extracted from texts into an ontology using language models. We explore an approach with three steps: edge search which is to find a set of candidate locations to insert (i.e., subsumptions between concepts), edge formation and enrichment which leverages the ontological structure to produce and enhance the edge candidates, and edge selection which eventually locates the edge to be placed into. In all steps, we propose to leverage neural methods, where we apply embedding-based methods and contrastive learning with Pre-trained Language Models (PLMs) such as BERT for edge search, and adapt a BERT fine-tuning-based multi-label Edge-Cross-encoder, and Large Language Models (LLMs) such as GPT series, FLAN-T5, and Llama 2, for edge selection. We evaluate the methods on recent datasets created using the SNOMED CT ontology and the MedMentions entity linking benchmark. The best settings in our framework use fine-tuned PLM for search and a multi-label Cross-encoder for selection. Zero-shot prompting of LLMs is still not adequate for the task, and we propose explainable instruction tuning of LLMs for improved performance. Our study shows the advantages of PLMs and highlights the encouraging performance of LLMs that motivates future studies.
Language Models as Hierarchy Encoders
Jan 21, 2024Interpreting hierarchical structures latent in language is a key limitation of current language models (LMs). While previous research has implicitly leveraged these hierarchies to enhance LMs, approaches for their explicit encoding are yet to be explored. To address this, we introduce a novel approach to re-train transformer encoder-based LMs as Hierarchy Transformer encoders (HiTs), harnessing the expansive nature of hyperbolic space. Our method situates the output embedding space of pre-trained LMs within a Poincar\'e ball with a curvature that adapts to the embedding dimension, followed by re-training on hyperbolic cluster and centripetal losses. These losses are designed to effectively cluster related entities (input as texts) and organise them hierarchically. We evaluate HiTs against pre-trained and fine-tuned LMs, focusing on their capabilities in simulating transitive inference, predicting subsumptions, and transferring knowledge across hierarchies. The results demonstrate that HiTs consistently outperform both pre-trained and fine-tuned LMs in these tasks, underscoring the effectiveness and transferability of our re-trained hierarchy encoders.
Optimised Storage for Datalog Reasoning
Dec 19, 2023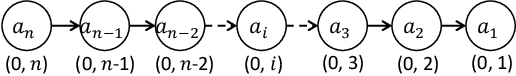
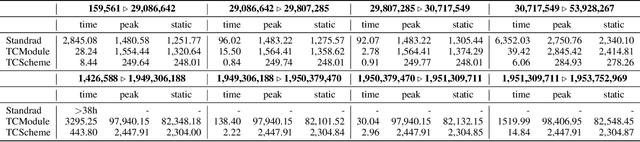

Materialisation facilitates Datalog reasoning by precomputing all consequences of the facts and the rules so that queries can be directly answered over the materialised facts. However, storing all materialised facts may be infeasible in practice, especially when the rules are complex and the given set of facts is large. We observe that for certain combinations of rules, there exist data structures that compactly represent the reasoning result and can be efficiently queried when necessary. In this paper, we present a general framework that allows for the integration of such optimised storage schemes with standard materialisation algorithms. Moreover, we devise optimised storage schemes targeting at transitive rules and union rules, two types of (combination of) rules that commonly occur in practice. Our experimental evaluation shows that our approach significantly improves memory consumption, sometimes by orders of magnitude, while remaining competitive in terms of query answering time.
Exploring Large Language Models for Ontology Alignment
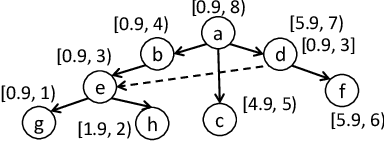
Sep 12, 2023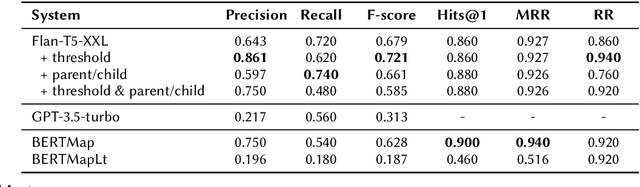
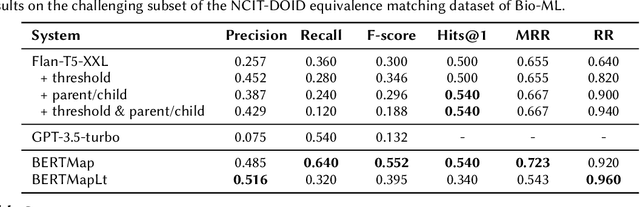
This work investigates the applicability of recent generative Large Language Models (LLMs), such as the GPT series and Flan-T5, to ontology alignment for identifying concept equivalence mappings across ontologies. To test the zero-shot performance of Flan-T5-XXL and GPT-3.5-turbo, we leverage challenging subsets from two equivalence matching datasets of the OAEI Bio-ML track, taking into account concept labels and structural contexts. Preliminary findings suggest that LLMs have the potential to outperform existing ontology alignment systems like BERTMap, given careful framework and prompt design.
DeepOnto: A Python Package for Ontology Engineering with Deep Learning
Jul 06, 2023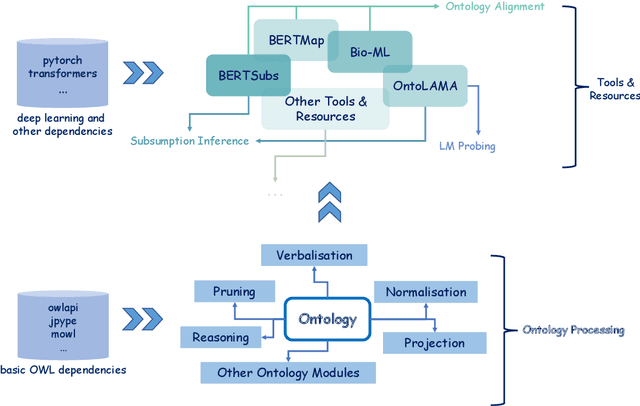
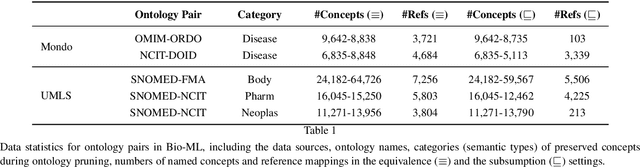
Applying deep learning techniques, particularly language models (LMs), in ontology engineering has raised widespread attention. However, deep learning frameworks like PyTorch and Tensorflow are predominantly developed for Python programming, while widely-used ontology APIs, such as the OWL API and Jena, are primarily Java-based. To facilitate seamless integration of these frameworks and APIs, we present Deeponto, a Python package designed for ontology engineering. The package encompasses a core ontology processing module founded on the widely-recognised and reliable OWL API, encapsulating its fundamental features in a more "Pythonic" manner and extending its capabilities to include other essential components including reasoning, verbalisation, normalisation, projection, and more. Building on this module, Deeponto offers a suite of tools, resources, and algorithms that support various ontology engineering tasks, such as ontology alignment and completion, by harnessing deep learning methodologies, primarily pre-trained LMs. In this paper, we also demonstrate the practical utility of Deeponto through two use-cases: the Digital Health Coaching in Samsung Research UK and the Bio-ML track of the Ontology Alignment Evaluation Initiative (OAEI).
Ontology Enrichment from Texts: A Biomedical Dataset for Concept Discovery and Placement
Jun 26, 2023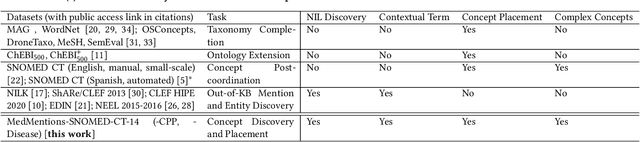
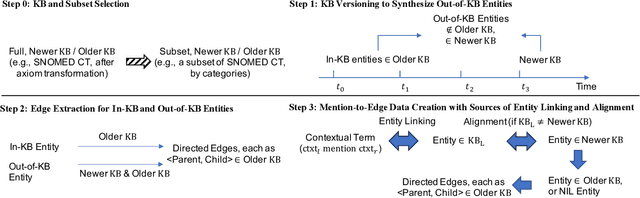

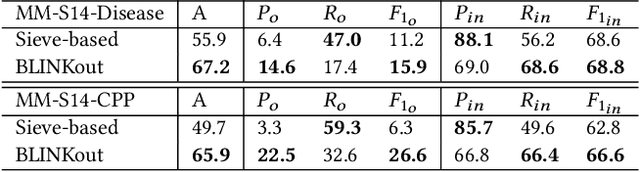
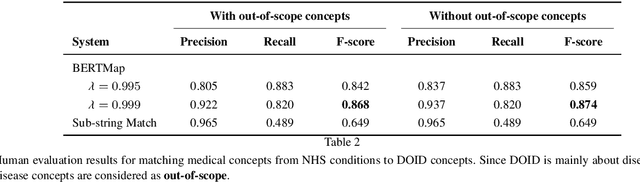
Mentions of new concepts appear regularly in texts and require automated approaches to harvest and place them into Knowledge Bases (KB), e.g., ontologies and taxonomies. Existing datasets suffer from three issues, (i) mostly assuming that a new concept is pre-discovered and cannot support out-of-KB mention discovery; (ii) only using the concept label as the input along with the KB and thus lacking the contexts of a concept label; and (iii) mostly focusing on concept placement w.r.t a taxonomy of atomic concepts, instead of complex concepts, i.e., with logical operators. To address these issues, we propose a new benchmark, adapting MedMentions dataset (PubMed abstracts) with SNOMED CT versions in 2014 and 2017 under the Diseases sub-category and the broader categories of Clinical finding, Procedure, and Pharmaceutical / biologic product. We provide usage on the evaluation with the dataset for out-of-KB mention discovery and concept placement, adapting recent Large Language Model based methods.
Revisiting Inferential Benchmarks for Knowledge Graph Completion
Jun 07, 2023
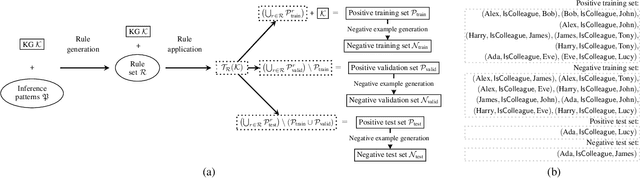
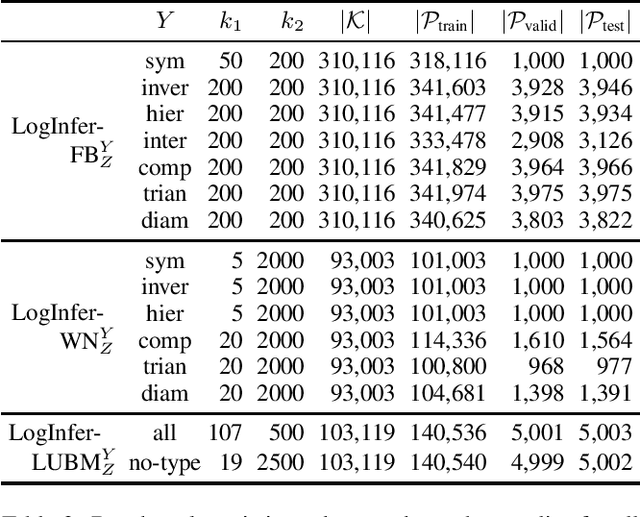
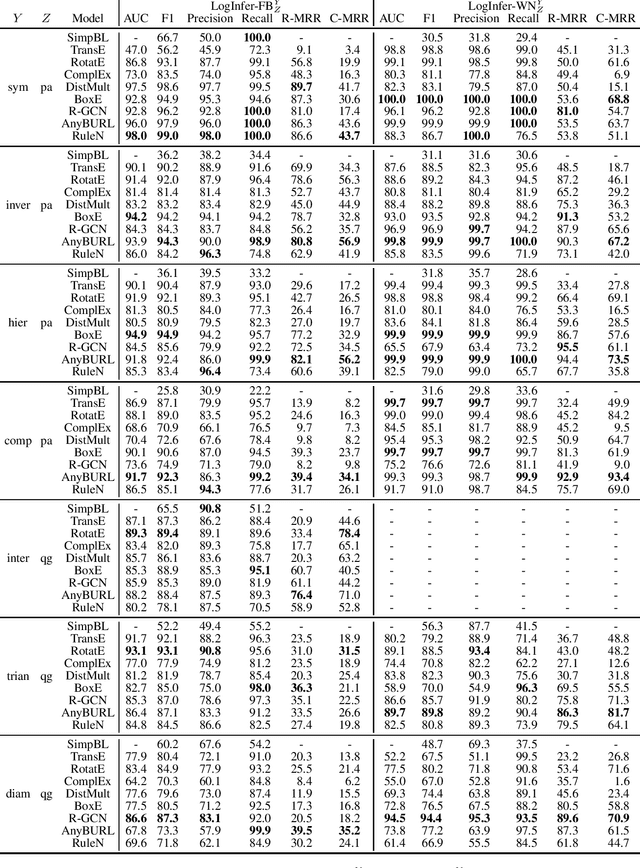
Knowledge Graph (KG) completion is the problem of extending an incomplete KG with missing facts. A key feature of Machine Learning approaches for KG completion is their ability to learn inference patterns, so that the predicted facts are the results of applying these patterns to the KG. Standard completion benchmarks, however, are not well-suited for evaluating models' abilities to learn patterns, because the training and test sets of these benchmarks are a random split of a given KG and hence do not capture the causality of inference patterns. We propose a novel approach for designing KG completion benchmarks based on the following principles: there is a set of logical rules so that the missing facts are the results of the rules' application; the training set includes both premises matching rule antecedents and the corresponding conclusions; the test set consists of the results of applying the rules to the training set; the negative examples are designed to discourage the models from learning rules not entailed by the rule set. We use our methodology to generate several benchmarks and evaluate a wide range of existing KG completion systems. Our results provide novel insights on the ability of existing models to induce inference patterns from incomplete KGs.