 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Graph Convolutional Networks Do Not Learn Sound Rules
Aug 14, 2024



Graph neural networks (GNNs) are frequently used to predict missing facts in knowledge graphs (KGs). Motivated by the lack of explainability for the outputs of these models, recent work has aimed to explain their predictions using Datalog, a widely used logic-based formalism. However, such work has been restricted to certain subclasses of GNNs. In this paper, we consider one of the most popular GNN architectures for KGs, R-GCN, and we provide two methods to extract rules that explain its predictions and are sound, in the sense that each fact derived by the rules is also predicted by the GNN, for any input dataset. Furthermore, we provide a method that can verify that certain classes of Datalog rules are not sound for the R-GCN. In our experiments, we train R-GCNs on KG completion benchmarks, and we are able to verify that no Datalog rule is sound for these models, even though the models often obtain high to near-perfect accuracy. This raises some concerns about the ability of R-GCN models to generalise and about the explainability of their predictions. We further provide two variations to the training paradigm of R-GCN that encourage it to learn sound rules and find a trade-off between model accuracy and the number of learned sound rules.
Universally Expressive Communication in Multi-Agent Reinforcement Learning
Jun 14, 2022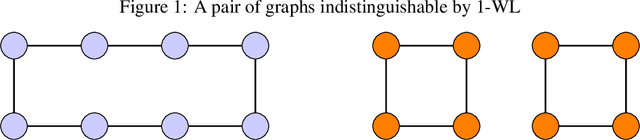
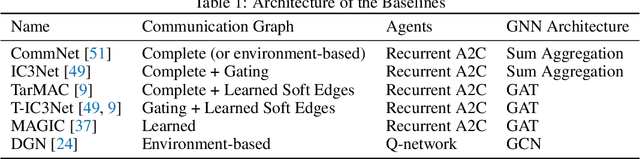

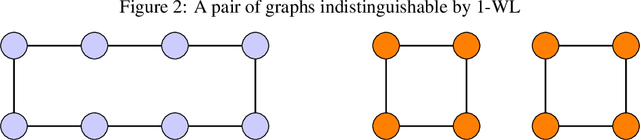
Allowing agents to share information through communication is crucial for solving complex tasks in multi-agent reinforcement learning. In this work, we consider the question of whether a given communication protocol can express an arbitrary policy. By observing that many existing protocols can be viewed as instances of graph neural networks (GNNs), we demonstrate the equivalence of joint action selection to node labelling. With standard GNN approaches provably limited in their expressive capacity, we draw from existing GNN literature and consider augmenting agent observations with: (1) unique agent IDs and (2) random noise. We provide a theoretical analysis as to how these approaches yield universally expressive communication, and also prove them capable of targeting arbitrary sets of actions for identical agents. Empirically, these augmentations are found to improve performance on tasks where expressive communication is required, whilst, in general, the optimal communication protocol is found to be task-dependent.
Beta-VAE Reproducibility: Challenges and Extensions
Dec 30, 2021



$\beta$-VAE is a follow-up technique to variational autoencoders that proposes special weighting of the KL divergence term in the VAE loss to obtain disentangled representations. Unsupervised learning is known to be brittle even on toy datasets and a meaningful, mathematically precise definition of disentanglement remains difficult to find. Here we investigate the original $\beta$-VAE paper and add evidence to the results previously obtained indicating its lack of reproducibility. We also further expand the experimentation of the models and include further more complex datasets in the analysis. We also implement an FID scoring metric for the $\beta$-VAE model and conclude a qualitative analysis of the results obtained. We end with a brief discussion on possible future investigations that can be conducted to add more robustness to the claims.