 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeta-VAE Reproducibility: Challenges and Extensions
Dec 30, 2021



$\beta$-VAE is a follow-up technique to variational autoencoders that proposes special weighting of the KL divergence term in the VAE loss to obtain disentangled representations. Unsupervised learning is known to be brittle even on toy datasets and a meaningful, mathematically precise definition of disentanglement remains difficult to find. Here we investigate the original $\beta$-VAE paper and add evidence to the results previously obtained indicating its lack of reproducibility. We also further expand the experimentation of the models and include further more complex datasets in the analysis. We also implement an FID scoring metric for the $\beta$-VAE model and conclude a qualitative analysis of the results obtained. We end with a brief discussion on possible future investigations that can be conducted to add more robustness to the claims.
DARTS without a Validation Set: Optimizing the Marginal Likelihood
Dec 24, 2021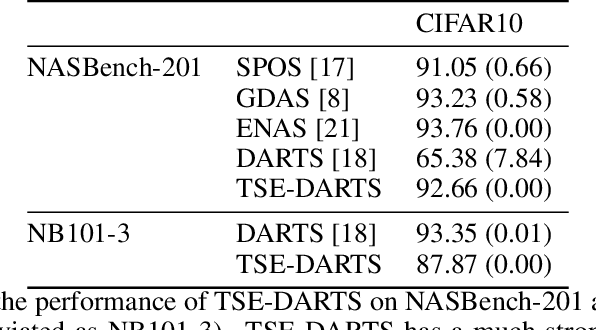
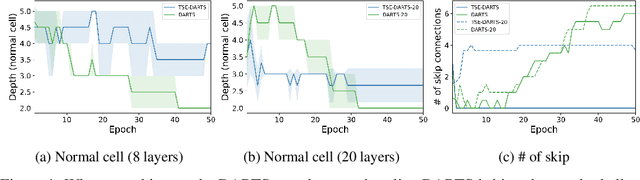
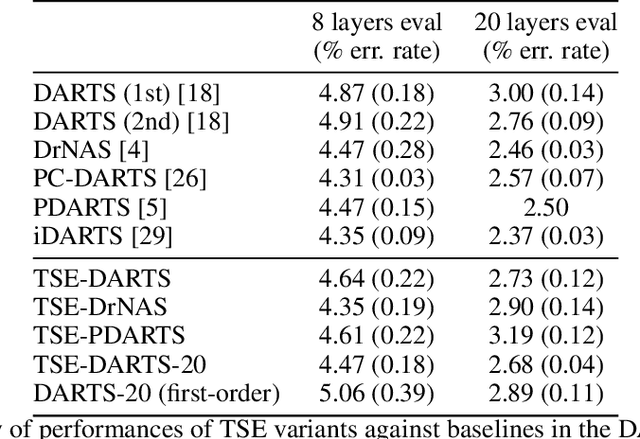
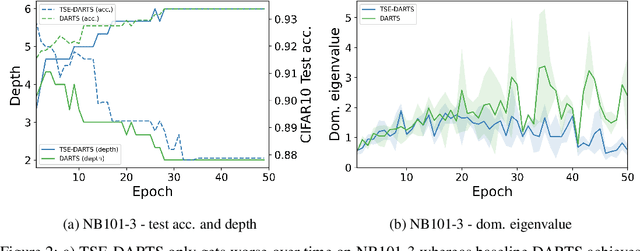
The success of neural architecture search (NAS) has historically been limited by excessive compute requirements. While modern weight-sharing NAS methods such as DARTS are able to finish the search in single-digit GPU days, extracting the final best architecture from the shared weights is notoriously unreliable. Training-Speed-Estimate (TSE), a recently developed generalization estimator with a Bayesian marginal likelihood interpretation, has previously been used in place of the validation loss for gradient-based optimization in DARTS. This prevents the DARTS skip connection collapse, which significantly improves performance on NASBench-201 and the original DARTS search space. We extend those results by applying various DARTS diagnostics and show several unusual behaviors arising from not using a validation set. Furthermore, our experiments yield concrete examples of the depth gap and topology selection in DARTS having a strongly negative impact on the search performance despite generally receiving limited attention in the literature compared to the operations selection.