 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvBench: A Standardised Preprocessing Pipeline for Multi-Modal Electronic Health Record Survival Analysis
Nov 14, 2025Electronic health record (EHR) data present tremendous opportunities for advancing survival analysis through deep learning, yet reproducibility remains severely constrained by inconsistent preprocessing methodologies. We present SurvBench, a comprehensive, open-source preprocessing pipeline that transforms raw PhysioNet datasets into standardised, model-ready tensors for multi-modal survival analysis. SurvBench provides data loaders for three major critical care databases, MIMIC-IV, eICU, and MC-MED, supporting diverse modalities including time-series vitals, static demographics, ICD diagnosis codes, and radiology reports. The pipeline implements rigorous data quality controls, patient-level splitting to prevent data leakage, explicit missingness tracking, and standardised temporal aggregation. SurvBench handles both single-risk (e.g., in-hospital mortality) and competing-risks scenarios (e.g., multiple discharge outcomes). The outputs are compatible with pycox library packages and implementations of standard statistical and deep learning models. By providing reproducible, configuration-driven preprocessing with comprehensive documentation, SurvBench addresses the "preprocessing gap" that has hindered fair comparison of deep learning survival models, enabling researchers to focus on methodological innovation rather than data engineering.
DynaGraph: Interpretable Multi-Label Prediction from EHRs via Dynamic Graph Learning and Contrastive Augmentation
Mar 28, 2025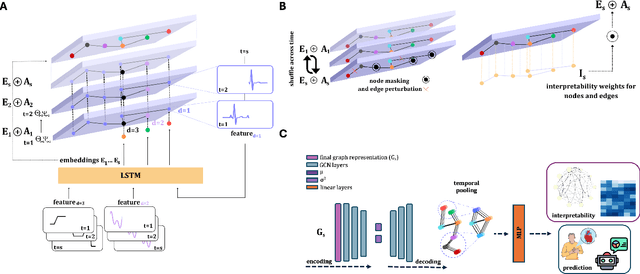
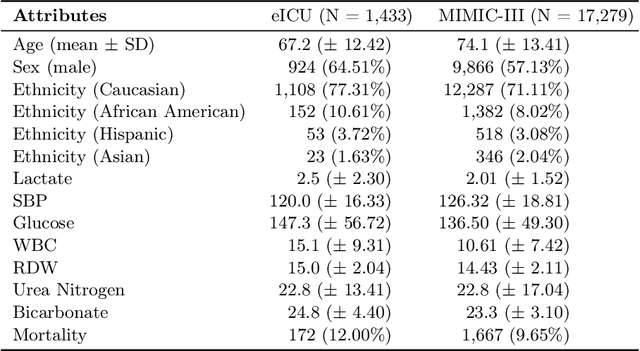
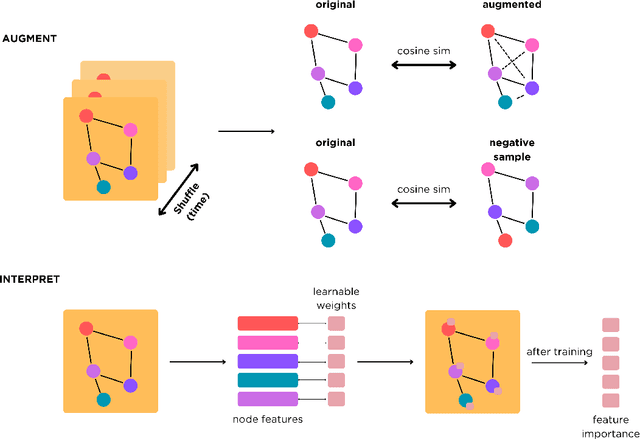
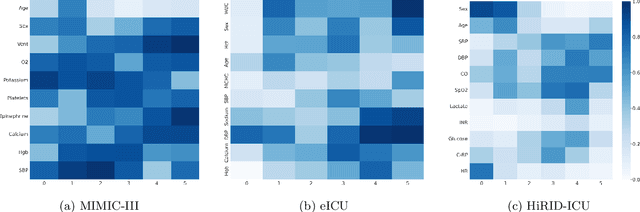
Learning from longitudinal electronic health records is limited if it does not capture the temporal trajectories of the patient's state in a clinical setting. Graph models allow us to capture the hidden dependencies of the multivariate time-series when the graphs are constructed in a similar dynamic manner. Previous dynamic graph models require a pre-defined and/or static graph structure, which is unknown in most cases, or they only capture the spatial relations between the features. Furthermore in healthcare, the interpretability of the model is an essential requirement to build trust with clinicians. In addition to previously proposed attention mechanisms, there has not been an interpretable dynamic graph framework for data from multivariate electronic health records (EHRs). Here, we propose DynaGraph, an end-to-end interpretable contrastive graph model that learns the dynamics of multivariate time-series EHRs as part of optimisation. We validate our model in four real-world clinical datasets, ranging from primary care to secondary care settings with broad demographics, in challenging settings where tasks are imbalanced and multi-labelled. Compared to state-of-the-art models, DynaGraph achieves significant improvements in balanced accuracy and sensitivity over the nearest complex competitors in time-series or dynamic graph modelling across three ICU and one primary care datasets. Through a pseudo-attention approach to graph construction, our model also indicates the importance of clinical covariates over time, providing means for clinical validation.
DySurv: Dynamic Deep Learning Model for Survival Prediction in the ICU
Oct 28, 2023



Survival analysis helps approximate underlying distributions of time-to-events which in the case of critical care like in the ICU can be a powerful tool for dynamic mortality risk prediction. Extending beyond the classical Cox model, deep learning techniques have been leveraged over the last years relaxing the many constraints of their counterparts from statistical methods. In this work, we propose a novel conditional variational autoencoder-based method called DySurv which uses a combination of static and time-series measurements from patient electronic health records in estimating risk of death dynamically in the ICU. DySurv has been tested on standard benchmarks where it outperforms most existing methods including other deep learning methods and we evaluate it on a real-world patient database from MIMIC-IV. The predictive capacity of DySurv is consistent and the survival estimates remain disentangled across different datasets supporting the idea that dynamic deep learning models based on conditional variational inference in multi-task cases can be robust models for survival analysis.
Explainable AI for clinical risk prediction: a survey of concepts, methods, and modalities
Aug 16, 2023Recent advancements in AI applications to healthcare have shown incredible promise in surpassing human performance in diagnosis and disease prognosis. With the increasing complexity of AI models, however, concerns regarding their opacity, potential biases, and the need for interpretability. To ensure trust and reliability in AI systems, especially in clinical risk prediction models, explainability becomes crucial. Explainability is usually referred to as an AI system's ability to provide a robust interpretation of its decision-making logic or the decisions themselves to human stakeholders. In clinical risk prediction, other aspects of explainability like fairness, bias, trust, and transparency also represent important concepts beyond just interpretability. In this review, we address the relationship between these concepts as they are often used together or interchangeably. This review also discusses recent progress in developing explainable models for clinical risk prediction, highlighting the importance of quantitative and clinical evaluation and validation across multiple common modalities in clinical practice. It emphasizes the need for external validation and the combination of diverse interpretability methods to enhance trust and fairness. Adopting rigorous testing, such as using synthetic datasets with known generative factors, can further improve the reliability of explainability methods. Open access and code-sharing resources are essential for transparency and reproducibility, enabling the growth and trustworthiness of explainable research. While challenges exist, an end-to-end approach to explainability in clinical risk prediction, incorporating stakeholders from clinicians to developers, is essential for success.
At-Admission Prediction of Mortality and Pulmonary Embolism in COVID-19 Patients Using Statistical and Machine Learning Methods: An International Cohort Study
May 18, 2023By September, 2022, more than 600 million cases of SARS-CoV-2 infection have been reported globally, resulting in over 6.5 million deaths. COVID-19 mortality risk estimators are often, however, developed with small unrepresentative samples and with methodological limitations. It is highly important to develop predictive tools for pulmonary embolism (PE) in COVID-19 patients as one of the most severe preventable complications of COVID-19. Using a dataset of more than 800,000 COVID-19 patients from an international cohort, we propose a cost-sensitive gradient-boosted machine learning model that predicts occurrence of PE and death at admission. Logistic regression, Cox proportional hazards models, and Shapley values were used to identify key predictors for PE and death. Our prediction model had a test AUROC of 75.9% and 74.2%, and sensitivities of 67.5% and 72.7% for PE and all-cause mortality respectively on a highly diverse and held-out test set. The PE prediction model was also evaluated on patients in UK and Spain separately with test results of 74.5% AUROC, 63.5% sensitivity and 78.9% AUROC, 95.7% sensitivity. Age, sex, region of admission, comorbidities (chronic cardiac and pulmonary disease, dementia, diabetes, hypertension, cancer, obesity, smoking), and symptoms (any, confusion, chest pain, fatigue, headache, fever, muscle or joint pain, shortness of breath) were the most important clinical predictors at admission. Our machine learning model developed from an international cohort can serve to better regulate hospital risk prioritisation of at-risk patients.
XMI-ICU: Explainable Machine Learning Model for Pseudo-Dynamic Prediction of Mortality in the ICU for Heart Attack Patients
May 10, 2023Heart attack remain one of the greatest contributors to mortality in the United States and globally. Patients admitted to the intensive care unit (ICU) with diagnosed heart attack (myocardial infarction or MI) are at higher risk of death. In this study, we use two retrospective cohorts extracted from the eICU and MIMIC-IV databases, to develop a novel pseudo-dynamic machine learning framework for mortality prediction in the ICU with interpretability and clinical risk analysis. The method provides accurate prediction for ICU patients up to 24 hours before the event and provide time-resolved interpretability results. The performance of the framework relying on extreme gradient boosting was evaluated on a held-out test set from eICU, and externally validated on the MIMIC-IV cohort using the most important features identified by time-resolved Shapley values achieving AUCs of 91.0 (balanced accuracy of 82.3) for 6-hour prediction of mortality respectively. We show that our framework successfully leverages time-series physiological measurements by translating them into stacked static prediction problems to be robustly predictive through time in the ICU stay and can offer clinical insight from time-resolved interpretability
Beta-VAE Reproducibility: Challenges and Extensions
Dec 30, 2021



$\beta$-VAE is a follow-up technique to variational autoencoders that proposes special weighting of the KL divergence term in the VAE loss to obtain disentangled representations. Unsupervised learning is known to be brittle even on toy datasets and a meaningful, mathematically precise definition of disentanglement remains difficult to find. Here we investigate the original $\beta$-VAE paper and add evidence to the results previously obtained indicating its lack of reproducibility. We also further expand the experimentation of the models and include further more complex datasets in the analysis. We also implement an FID scoring metric for the $\beta$-VAE model and conclude a qualitative analysis of the results obtained. We end with a brief discussion on possible future investigations that can be conducted to add more robustness to the claims.