 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratising Clinical AI through Dataset Condensation for Classical Clinical Models
Mar 10, 2026Dataset condensation (DC) learns a compact synthetic dataset that enables models to match the performance of full-data training, prioritising utility over distributional fidelity. While typically explored for computational efficiency, DC also holds promise for healthcare data democratisation, especially when paired with differential privacy, allowing synthetic data to serve as a safe alternative to real records. However, existing DC methods rely on differentiable neural networks, limiting their compatibility with widely used clinical models such as decision trees and Cox regression. We address this gap using a differentially private, zero-order optimisation framework that extends DC to non-differentiable models using only function evaluations. Empirical results across six datasets, including both classification and survival tasks, show that the proposed method produces condensed datasets that preserve model utility while providing effective differential privacy guarantees - enabling model-agnostic data sharing for clinical prediction tasks without exposing sensitive patient information.
Bridging the Generalisation Gap: Synthetic Data Generation for Multi-Site Clinical Model Validation
Apr 29, 2025



Ensuring the generalisability of clinical machine learning (ML) models across diverse healthcare settings remains a significant challenge due to variability in patient demographics, disease prevalence, and institutional practices. Existing model evaluation approaches often rely on real-world datasets, which are limited in availability, embed confounding biases, and lack the flexibility needed for systematic experimentation. Furthermore, while generative models aim for statistical realism, they often lack transparency and explicit control over factors driving distributional shifts. In this work, we propose a novel structured synthetic data framework designed for the controlled benchmarking of model robustness, fairness, and generalisability. Unlike approaches focused solely on mimicking observed data, our framework provides explicit control over the data generating process, including site-specific prevalence variations, hierarchical subgroup effects, and structured feature interactions. This enables targeted investigation into how models respond to specific distributional shifts and potential biases. Through controlled experiments, we demonstrate the framework's ability to isolate the impact of site variations, support fairness-aware audits, and reveal generalisation failures, particularly highlighting how model complexity interacts with site-specific effects. This work contributes a reproducible, interpretable, and configurable tool designed to advance the reliable deployment of ML in clinical settings.
RiskAgent: Autonomous Medical AI Copilot for Generalist Risk Prediction
Mar 05, 2025The application of Large Language Models (LLMs) to various clinical applications has attracted growing research attention. However, real-world clinical decision-making differs significantly from the standardized, exam-style scenarios commonly used in current efforts. In this paper, we present the RiskAgent system to perform a broad range of medical risk predictions, covering over 387 risk scenarios across diverse complex diseases, e.g., cardiovascular disease and cancer. RiskAgent is designed to collaborate with hundreds of clinical decision tools, i.e., risk calculators and scoring systems that are supported by evidence-based medicine. To evaluate our method, we have built the first benchmark MedRisk specialized for risk prediction, including 12,352 questions spanning 154 diseases, 86 symptoms, 50 specialties, and 24 organ systems. The results show that our RiskAgent, with 8 billion model parameters, achieves 76.33% accuracy, outperforming the most recent commercial LLMs, o1, o3-mini, and GPT-4.5, and doubling the 38.39% accuracy of GPT-4o. On rare diseases, e.g., Idiopathic Pulmonary Fibrosis (IPF), RiskAgent outperforms o1 and GPT-4.5 by 27.27% and 45.46% accuracy, respectively. Finally, we further conduct a generalization evaluation on an external evidence-based diagnosis benchmark and show that our RiskAgent achieves the best results. These encouraging results demonstrate the great potential of our solution for diverse diagnosis domains. To improve the adaptability of our model in different scenarios, we have built and open-sourced a family of models ranging from 1 billion to 70 billion parameters. Our code, data, and models are all available at https://github.com/AI-in-Health/RiskAgent.
Individualised Treatment Effects Estimation with Composite Treatments and Composite Outcomes
Feb 12, 2025



Estimating individualised treatment effect (ITE) -- that is the causal effect of a set of variables (also called exposures, treatments, actions, policies, or interventions), referred to as \textit{composite treatments}, on a set of outcome variables of interest, referred to as \textit{composite outcomes}, for a unit from observational data -- remains a fundamental problem in causal inference with applications across disciplines, such as healthcare, economics, education, social science, marketing, and computer science. Previous work in causal machine learning for ITE estimation is limited to simple settings, like single treatments and single outcomes. This hinders their use in complex real-world scenarios; for example, consider studying the effect of different ICU interventions, such as beta-blockers and statins for a patient admitted for heart surgery, on different outcomes of interest such as atrial fibrillation and in-hospital mortality. The limited research into composite treatments and outcomes is primarily due to data scarcity for all treatments and outcomes. To address the above challenges, we propose a novel and innovative hypernetwork-based approach, called \emph{H-Learner}, to solve ITE estimation under composite treatments and composite outcomes, which tackles the data scarcity issue by dynamically sharing information across treatments and outcomes. Our empirical analysis with binary and arbitrary composite treatments and outcomes demonstrates the effectiveness of the proposed approach compared to existing methods.
Computation-Efficient Semi-Supervised Learning for ECG-based Cardiovascular Diseases Detection
Jun 20, 2024Label scarcity problem is the main challenge that hinders the wide application of deep learning systems in automatic cardiovascular diseases (CVDs) detection using electrocardiography (ECG). Tuning pre-trained models alleviates this problem by transferring knowledge learned from large datasets to downstream small datasets. However, bottlenecks in computational efficiency and CVDs detection performance limit its clinical applications. It is difficult to improve the detection performance without significantly sacrificing model computational efficiency. Here, we propose a computation-efficient semi-supervised learning paradigm (FastECG) for robust and computation-efficient CVDs detection using ECG. It enables a robust adaptation of pre-trained models on downstream datasets with limited supervision and high computational efficiency. First, a random-deactivation technique is developed to achieve robust and fast low-rank adaptation of pre-trained weights. Subsequently, we propose a one-shot rank allocation module to determine the optimal ranks for the update matrices of the pre-trained weights. Finally, a lightweight semi-supervised learning pipeline is introduced to enhance model performance by leveraging labeled and unlabeled data with high computational efficiency. Extensive experiments on four downstream ECG datasets demonstrate that FastECG not only outperforms the state-of-the-art methods in multi-label CVDs detection but also consumes fewer GPU footprints, training time, and parameter storage space. As such, this paradigm provides an effective solution for achieving high computational efficiency and robust detection performance in the clinical applications of pre-trained models under limited supervision.
Sample Selection Bias in Machine Learning for Healthcare
May 13, 2024



While machine learning algorithms hold promise for personalised medicine, their clinical adoption remains limited. One critical factor contributing to this restraint is sample selection bias (SSB) which refers to the study population being less representative of the target population, leading to biased and potentially harmful decisions. Despite being well-known in the literature, SSB remains scarcely studied in machine learning for healthcare. Moreover, the existing techniques try to correct the bias by balancing distributions between the study and the target populations, which may result in a loss of predictive performance. To address these problems, our study illustrates the potential risks associated with SSB by examining SSB's impact on the performance of machine learning algorithms. Most importantly, we propose a new research direction for addressing SSB, based on the target population identification rather than the bias correction. Specifically, we propose two independent networks (T-Net) and a multitasking network (MT-Net) for addressing SSB, where one network/task identifies the target subpopulation which is representative of the study population and the second makes predictions for the identified subpopulation. Our empirical results with synthetic and semi-synthetic datasets highlight that SSB can lead to a large drop in the performance of an algorithm for the target population as compared with the study population, as well as a substantial difference in the performance for the target subpopulations that are representative of the selected and the non-selected patients from the study population. Furthermore, our proposed techniques demonstrate robustness across various settings, including different dataset sizes, event rates, and selection rates, outperforming the existing bias correction techniques.
Large Language Models in Healthcare: A Comprehensive Benchmark
Apr 25, 2024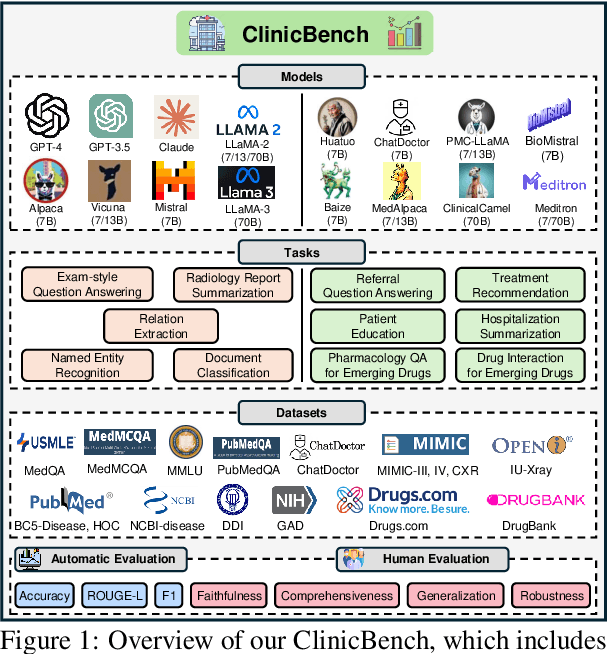



The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering task with answer options for evaluation. However, in real clinical settings, many clinical decisions, such as treatment recommendations, involve answering open-ended questions without pre-set options. Meanwhile, existing studies mainly use accuracy to assess model performance. In this paper, we comprehensively benchmark diverse LLMs in healthcare, to clearly understand their strengths and weaknesses. Our benchmark contains seven tasks and thirteen datasets across medical language generation, understanding, and reasoning. We conduct a detailed evaluation of the existing sixteen LLMs in healthcare under both zero-shot and few-shot (i.e., 1,3,5-shot) learning settings. We report the results on five metrics (i.e. matching, faithfulness, comprehensiveness, generalizability, and robustness) that are critical in achieving trust from clinical users. We further invite medical experts to conduct human evaluation.
At-Admission Prediction of Mortality and Pulmonary Embolism in COVID-19 Patients Using Statistical and Machine Learning Methods: An International Cohort Study
May 18, 2023By September, 2022, more than 600 million cases of SARS-CoV-2 infection have been reported globally, resulting in over 6.5 million deaths. COVID-19 mortality risk estimators are often, however, developed with small unrepresentative samples and with methodological limitations. It is highly important to develop predictive tools for pulmonary embolism (PE) in COVID-19 patients as one of the most severe preventable complications of COVID-19. Using a dataset of more than 800,000 COVID-19 patients from an international cohort, we propose a cost-sensitive gradient-boosted machine learning model that predicts occurrence of PE and death at admission. Logistic regression, Cox proportional hazards models, and Shapley values were used to identify key predictors for PE and death. Our prediction model had a test AUROC of 75.9% and 74.2%, and sensitivities of 67.5% and 72.7% for PE and all-cause mortality respectively on a highly diverse and held-out test set. The PE prediction model was also evaluated on patients in UK and Spain separately with test results of 74.5% AUROC, 63.5% sensitivity and 78.9% AUROC, 95.7% sensitivity. Age, sex, region of admission, comorbidities (chronic cardiac and pulmonary disease, dementia, diabetes, hypertension, cancer, obesity, smoking), and symptoms (any, confusion, chest pain, fatigue, headache, fever, muscle or joint pain, shortness of breath) were the most important clinical predictors at admission. Our machine learning model developed from an international cohort can serve to better regulate hospital risk prioritisation of at-risk patients.
Lightweight Transformers for Clinical Natural Language Processing
Feb 09, 2023
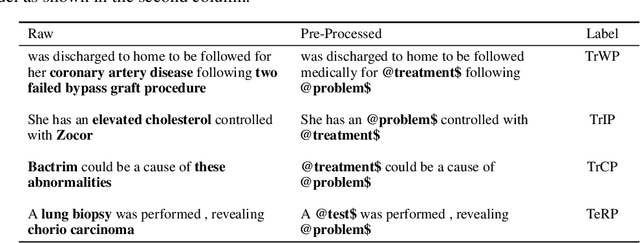
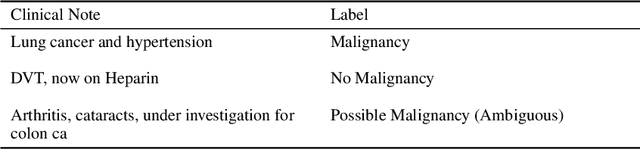
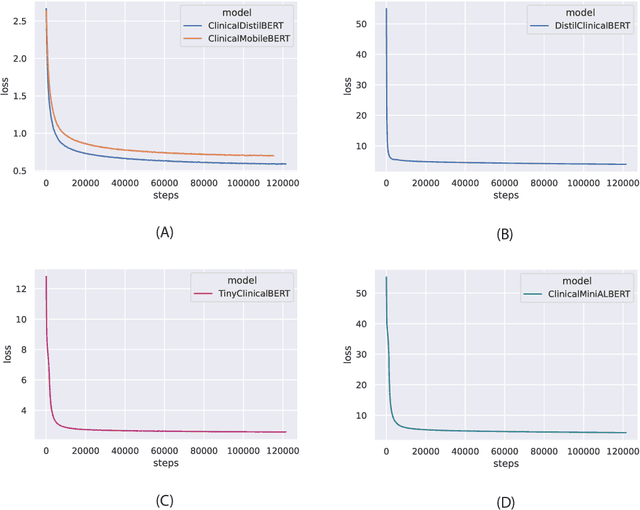
Specialised pre-trained language models are becoming more frequent in NLP since they can potentially outperform models trained on generic texts. BioBERT and BioClinicalBERT are two examples of such models that have shown promise in medical NLP tasks. Many of these models are overparametrised and resource-intensive, but thanks to techniques like Knowledge Distillation (KD), it is possible to create smaller versions that perform almost as well as their larger counterparts. In this work, we specifically focus on development of compact language models for processing clinical texts (i.e. progress notes, discharge summaries etc). We developed a number of efficient lightweight clinical transformers using knowledge distillation and continual learning, with the number of parameters ranging from 15 million to 65 million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including Natural Language Inference, Relation Extraction, Named Entity Recognition, and Sequence Classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.