 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Large-Scale Photonics-Empowered AI Systems: From Physical Design Automation to System-Algorithm Co-Exploration
Dec 31, 2025In this work, we identify three considerations that are essential for realizing practical photonic AI systems at scale: (1) dynamic tensor operation support for modern models rather than only weight-static kernels, especially for attention/Transformer-style workloads; (2) systematic management of conversion, control, and data-movement overheads, where multiplexing and dataflow must amortize electronic costs instead of letting ADC/DAC and I/O dominate; and (3) robustness under hardware non-idealities that become more severe as integration density grows. To study these coupled tradeoffs quantitatively, and to ensure they remain meaningful under real implementation constraints, we build a cross-layer toolchain that supports photonic AI design from early exploration to physical realization. SimPhony provides implementation-aware modeling and rapid cross-layer evaluation, translating physical costs into system-level metrics so architectural decisions are grounded in realistic assumptions. ADEPT and ADEPT-Z enable end-to-end circuit and topology exploration, connecting system objectives to feasible photonic fabrics under practical device and circuit constraints. Finally, Apollo and LiDAR provide scalable photonic physical design automation, turning candidate circuits into manufacturable layouts while accounting for routing, thermal, and crosstalk constraints.
Democratizing Electronic-Photonic AI Systems: An Open-Source AI-Infused Cross-Layer Co-Design and Design Automation Toolflow
Dec 31, 2025Photonics is becoming a cornerstone technology for high-performance AI systems and scientific computing, offering unparalleled speed, parallelism, and energy efficiency. Despite this promise, the design and deployment of electronic-photonic AI systems remain highly challenging due to a steep learning curve across multiple layers, spanning device physics, circuit design, system architecture, and AI algorithms. The absence of a mature electronic-photonic design automation (EPDA) toolchain leads to long, inefficient design cycles and limits cross-disciplinary innovation and co-evolution. In this work, we present a cross-layer co-design and automation framework aimed at democratizing photonic AI system development. We begin by introducing our architecture designs for scalable photonic edge AI and Transformer inference, followed by SimPhony, an open-source modeling tool for rapid EPIC AI system evaluation and design-space exploration. We then highlight advances in AI-enabled photonic design automation, including physical AI-based Maxwell solvers, a fabrication-aware inverse design framework, and a scalable inverse training algorithm for meta-optical neural networks, enabling a scalable EPDA stack for next-generation electronic-photonic AI systems.
Toward Lifelong-Sustainable Electronic-Photonic AI Systems via Extreme Efficiency, Reconfigurability, and Robustness
Sep 09, 2025The relentless growth of large-scale artificial intelligence (AI) has created unprecedented demand for computational power, straining the energy, bandwidth, and scaling limits of conventional electronic platforms. Electronic-photonic integrated circuits (EPICs) have emerged as a compelling platform for next-generation AI systems, offering inherent advantages in ultra-high bandwidth, low latency, and energy efficiency for computing and interconnection. Beyond performance, EPICs also hold unique promises for sustainability. Fabricated in relaxed process nodes with fewer metal layers and lower defect densities, photonic devices naturally reduce embodied carbon footprint (CFP) compared to advanced digital electronic integrated circuits, while delivering orders-of-magnitude higher computing performance and interconnect bandwidth. To further advance the sustainability of photonic AI systems, we explore how electronic-photonic design automation (EPDA) and cross-layer co-design methodologies can amplify these inherent benefits. We present how advanced EPDA tools enable more compact layout generation, reducing both chip area and metal layer usage. We will also demonstrate how cross-layer device-circuit-architecture co-design unlocks new sustainability gains for photonic hardware: ultra-compact photonic circuit designs that minimize chip area cost, reconfigurable hardware topology that adapts to evolving AI workloads, and intelligent resilience mechanisms that prolong lifetime by tolerating variations and faults. By uniting intrinsic photonic efficiency with EPDA- and co-design-driven gains in area efficiency, reconfigurability, and robustness, we outline a vision for lifelong-sustainable electronic-photonic AI systems. This perspective highlights how EPIC AI systems can simultaneously meet the performance demands of modern AI and the urgent imperative for sustainable computing.
RiskAgent: Autonomous Medical AI Copilot for Generalist Risk Prediction
Mar 05, 2025The application of Large Language Models (LLMs) to various clinical applications has attracted growing research attention. However, real-world clinical decision-making differs significantly from the standardized, exam-style scenarios commonly used in current efforts. In this paper, we present the RiskAgent system to perform a broad range of medical risk predictions, covering over 387 risk scenarios across diverse complex diseases, e.g., cardiovascular disease and cancer. RiskAgent is designed to collaborate with hundreds of clinical decision tools, i.e., risk calculators and scoring systems that are supported by evidence-based medicine. To evaluate our method, we have built the first benchmark MedRisk specialized for risk prediction, including 12,352 questions spanning 154 diseases, 86 symptoms, 50 specialties, and 24 organ systems. The results show that our RiskAgent, with 8 billion model parameters, achieves 76.33% accuracy, outperforming the most recent commercial LLMs, o1, o3-mini, and GPT-4.5, and doubling the 38.39% accuracy of GPT-4o. On rare diseases, e.g., Idiopathic Pulmonary Fibrosis (IPF), RiskAgent outperforms o1 and GPT-4.5 by 27.27% and 45.46% accuracy, respectively. Finally, we further conduct a generalization evaluation on an external evidence-based diagnosis benchmark and show that our RiskAgent achieves the best results. These encouraging results demonstrate the great potential of our solution for diverse diagnosis domains. To improve the adaptability of our model in different scenarios, we have built and open-sourced a family of models ranging from 1 billion to 70 billion parameters. Our code, data, and models are all available at https://github.com/AI-in-Health/RiskAgent.
Large Language Models in Healthcare: A Comprehensive Benchmark
Apr 25, 2024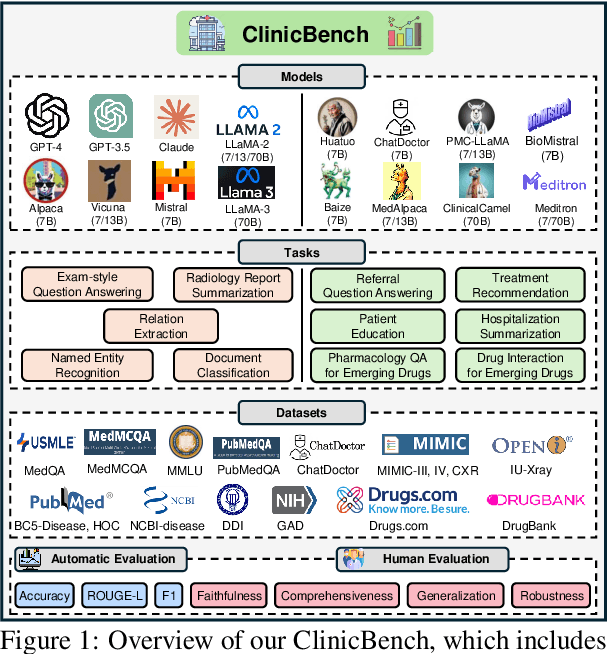



The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering task with answer options for evaluation. However, in real clinical settings, many clinical decisions, such as treatment recommendations, involve answering open-ended questions without pre-set options. Meanwhile, existing studies mainly use accuracy to assess model performance. In this paper, we comprehensively benchmark diverse LLMs in healthcare, to clearly understand their strengths and weaknesses. Our benchmark contains seven tasks and thirteen datasets across medical language generation, understanding, and reasoning. We conduct a detailed evaluation of the existing sixteen LLMs in healthcare under both zero-shot and few-shot (i.e., 1,3,5-shot) learning settings. We report the results on five metrics (i.e. matching, faithfulness, comprehensiveness, generalizability, and robustness) that are critical in achieving trust from clinical users. We further invite medical experts to conduct human evaluation.
A Survey of Large Language Models in Medicine: Progress, Application, and Challenge
Nov 09, 2023

Large language models (LLMs), such as ChatGPT, have achieved substantial attention due to their impressive human language understanding and generation capabilities. Therefore, the application of LLMs in medicine to assist physicians and patient care emerges as a promising research direction in both artificial intelligence and clinical medicine. To this end, this survey provides a comprehensive overview of the current progress, applications, and challenges faced by LLMs in medicine. Specifically, we aim to address the following questions: 1) What are LLMs and how can medical LLMs be built? 2) What are the downstream performances of medical LLMs? 3) How can medical LLMs be utilized in real-world clinical practice? 4) What challenges arise from the use of medical LLMs? 5) How can we better construct and utilize medical LLMs? As a result, this survey aims to provide insights into the opportunities and challenges of LLMs in medicine and serve as a valuable resource for constructing practical and effective medical LLMs. A regularly updated list of practical guide resources of medical LLMs can be found at https://github.com/AI-in-Health/MedLLMsPracticalGuide.
Reinforcement Learning Approach for Multi-Agent Flexible Scheduling Problems
Oct 07, 2022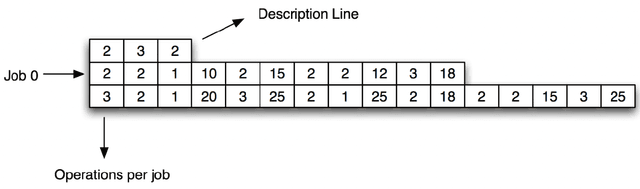

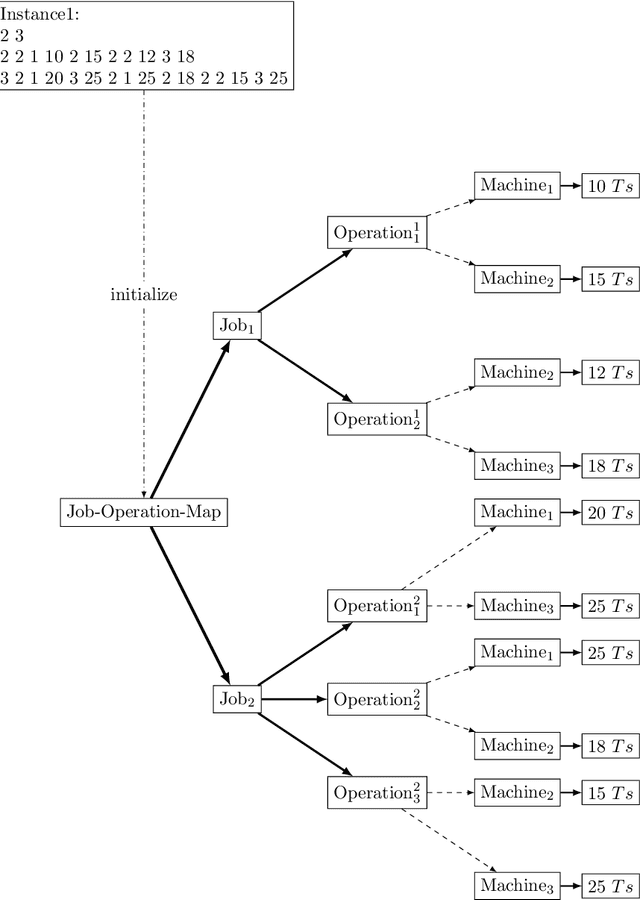
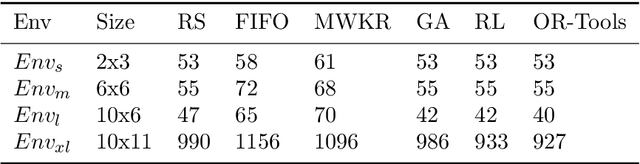
Scheduling plays an important role in automated production. Its impact can be found in various fields such as the manufacturing industry, the service industry and the technology industry. A scheduling problem (NP-hard) is a task of finding a sequence of job assignments on a given set of machines with the goal of optimizing the objective defined. Methods such as Operation Research, Dispatching Rules, and Combinatorial Optimization have been applied to scheduling problems but no solution guarantees to find the optimal solution. The recent development of Reinforcement Learning has shown success in sequential decision-making problems. This research presents a Reinforcement Learning approach for scheduling problems. In particular, this study delivers an OpenAI gym environment with search-space reduction for Job Shop Scheduling Problems and provides a heuristic-guided Q-Learning solution with state-of-the-art performance for Multi-agent Flexible Job Shop Problems.