 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Large Language Models in Medicine: Progress, Application, and Challenge
Nov 09, 2023

Large language models (LLMs), such as ChatGPT, have achieved substantial attention due to their impressive human language understanding and generation capabilities. Therefore, the application of LLMs in medicine to assist physicians and patient care emerges as a promising research direction in both artificial intelligence and clinical medicine. To this end, this survey provides a comprehensive overview of the current progress, applications, and challenges faced by LLMs in medicine. Specifically, we aim to address the following questions: 1) What are LLMs and how can medical LLMs be built? 2) What are the downstream performances of medical LLMs? 3) How can medical LLMs be utilized in real-world clinical practice? 4) What challenges arise from the use of medical LLMs? 5) How can we better construct and utilize medical LLMs? As a result, this survey aims to provide insights into the opportunities and challenges of LLMs in medicine and serve as a valuable resource for constructing practical and effective medical LLMs. A regularly updated list of practical guide resources of medical LLMs can be found at https://github.com/AI-in-Health/MedLLMsPracticalGuide.
Factorized Multimodal Transformer for Multimodal Sequential Learning
Nov 22, 2019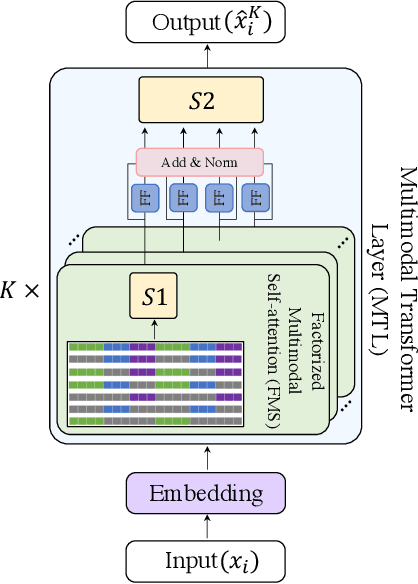
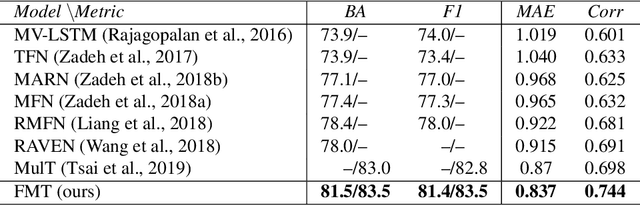
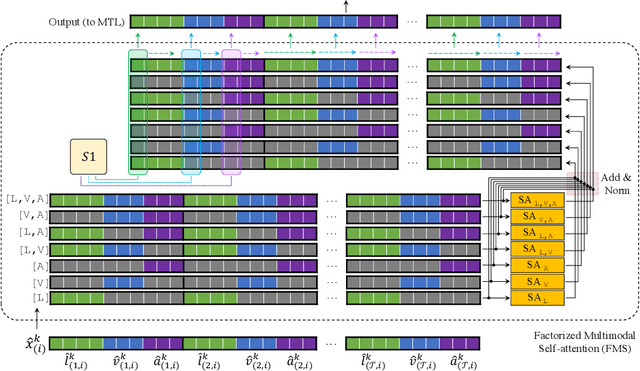
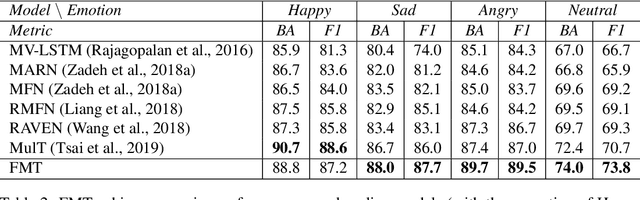
The complex world around us is inherently multimodal and sequential (continuous). Information is scattered across different modalities and requires multiple continuous sensors to be captured. As machine learning leaps towards better generalization to real world, multimodal sequential learning becomes a fundamental research area. Arguably, modeling arbitrarily distributed spatio-temporal dynamics within and across modalities is the biggest challenge in this research area. In this paper, we present a new transformer model, called the Factorized Multimodal Transformer (FMT) for multimodal sequential learning. FMT inherently models the intramodal and intermodal (involving two or more modalities) dynamics within its multimodal input in a factorized manner. The proposed factorization allows for increasing the number of self-attentions to better model the multimodal phenomena at hand; without encountering difficulties during training (e.g. overfitting) even on relatively low-resource setups. All the attention mechanisms within FMT have a full time-domain receptive field which allows them to asynchronously capture long-range multimodal dynamics. In our experiments we focus on datasets that contain the three commonly studied modalities of language, vision and acoustic. We perform a wide range of experiments, spanning across 3 well-studied datasets and 21 distinct labels. FMT shows superior performance over previously proposed models, setting new state of the art in the studied datasets.