 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Inferential Benchmarks for Knowledge Graph Completion
Jun 07, 2023
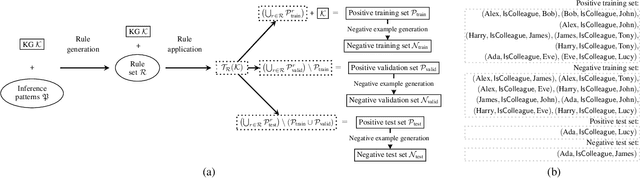
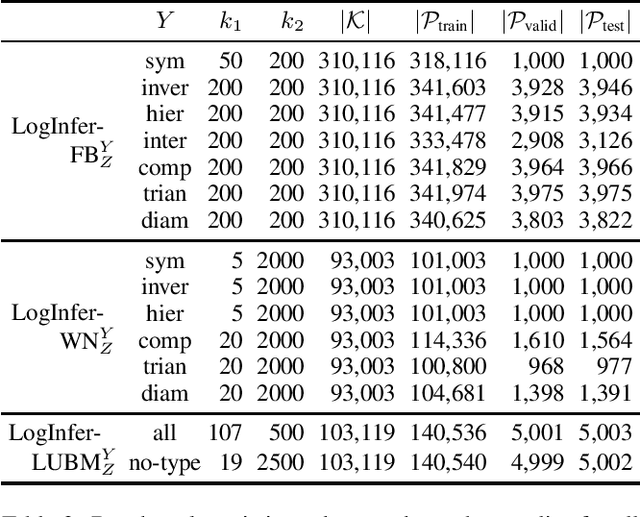
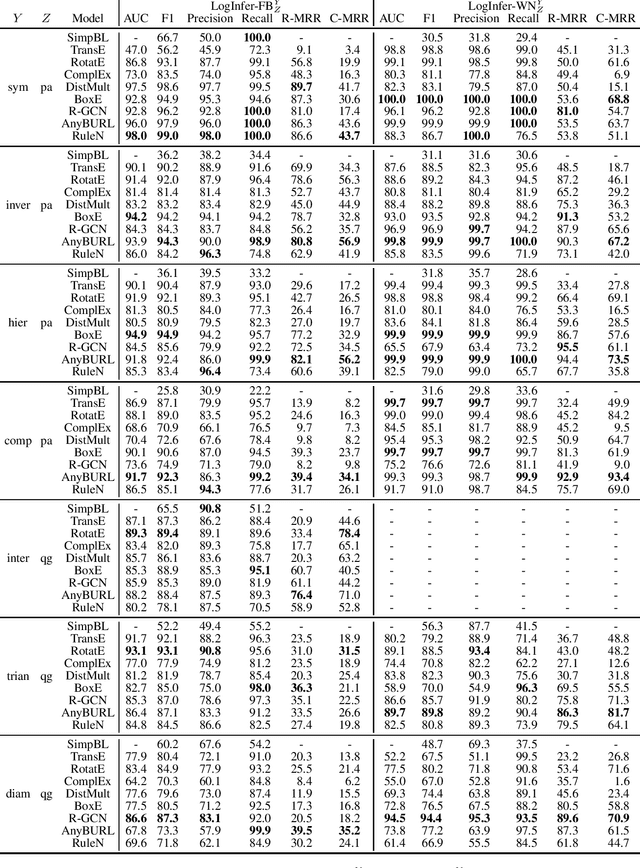
Knowledge Graph (KG) completion is the problem of extending an incomplete KG with missing facts. A key feature of Machine Learning approaches for KG completion is their ability to learn inference patterns, so that the predicted facts are the results of applying these patterns to the KG. Standard completion benchmarks, however, are not well-suited for evaluating models' abilities to learn patterns, because the training and test sets of these benchmarks are a random split of a given KG and hence do not capture the causality of inference patterns. We propose a novel approach for designing KG completion benchmarks based on the following principles: there is a set of logical rules so that the missing facts are the results of the rules' application; the training set includes both premises matching rule antecedents and the corresponding conclusions; the test set consists of the results of applying the rules to the training set; the negative examples are designed to discourage the models from learning rules not entailed by the rule set. We use our methodology to generate several benchmarks and evaluate a wide range of existing KG completion systems. Our results provide novel insights on the ability of existing models to induce inference patterns from incomplete KGs.
Mixup-Based Acoustic Scene Classification Using Multi-Channel Convolutional Neural Network
May 18, 2018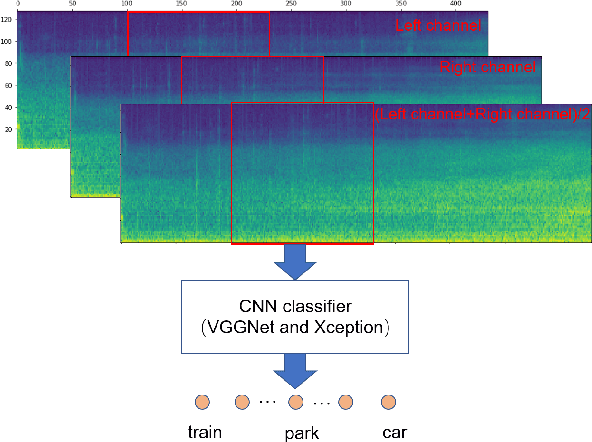
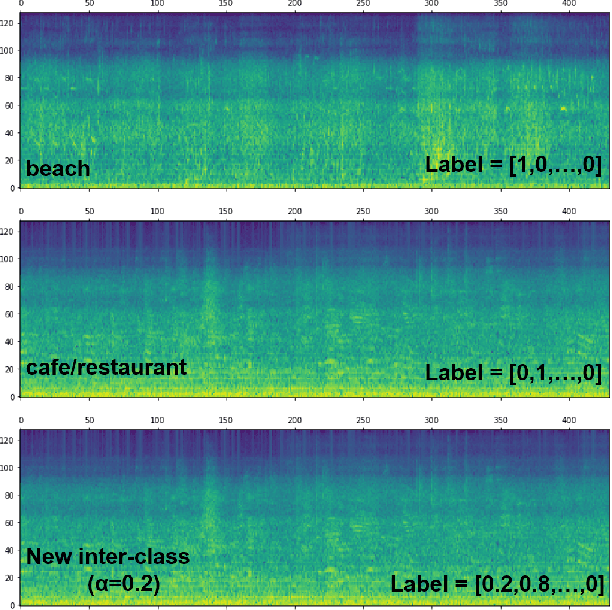
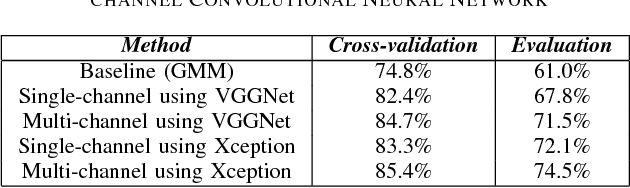
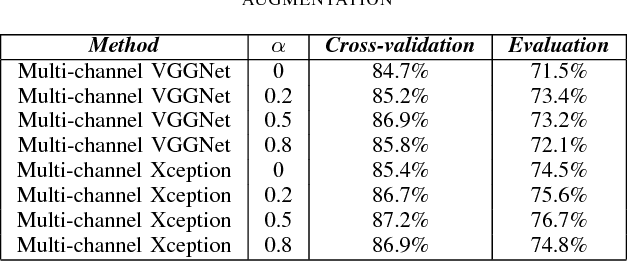
Audio scene classification, the problem of predicting class labels of audio scenes, has drawn lots of attention during the last several years. However, it remains challenging and falls short of accuracy and efficiency. Recently, Convolutional Neural Network (CNN)-based methods have achieved better performance with comparison to the traditional methods. Nevertheless, conventional single channel CNN may fail to consider the fact that additional cues may be embedded in the multi-channel recordings. In this paper, we explore the use of Multi-channel CNN for the classification task, which aims to extract features from different channels in an end-to-end manner. We conduct the evaluation compared with the conventional CNN and traditional Gaussian Mixture Model-based methods. Moreover, to improve the classification accuracy further, this paper explores the using of mixup method. In brief, mixup trains the neural network on linear combinations of pairs of the representation of audio scene examples and their labels. By employing the mixup approach for data argumentation, the novel model can provide higher prediction accuracy and robustness in contrast with previous models, while the generalization error can also be reduced on the evaluation data.