 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixup-Based Acoustic Scene Classification Using Multi-Channel Convolutional Neural Network
May 18, 2018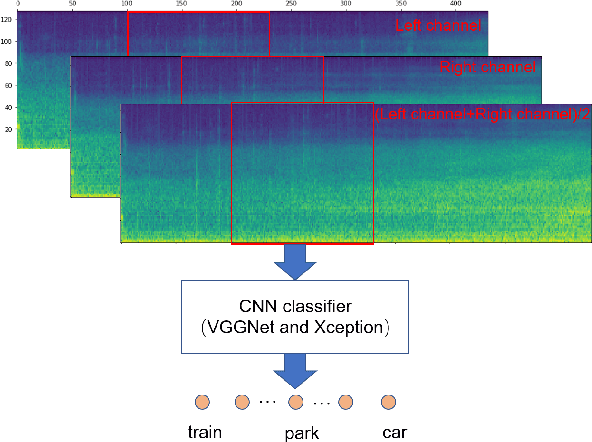
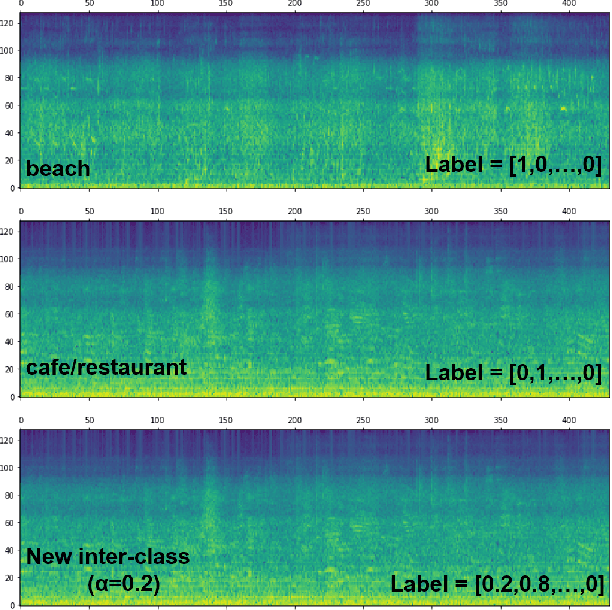
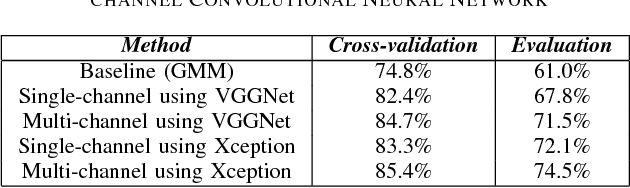
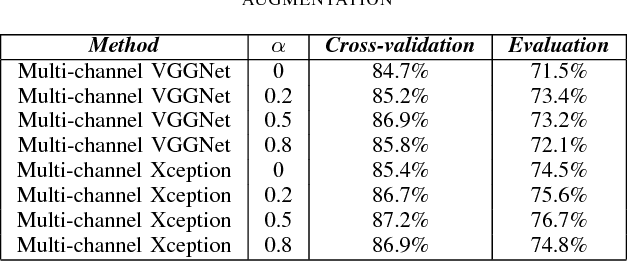
Audio scene classification, the problem of predicting class labels of audio scenes, has drawn lots of attention during the last several years. However, it remains challenging and falls short of accuracy and efficiency. Recently, Convolutional Neural Network (CNN)-based methods have achieved better performance with comparison to the traditional methods. Nevertheless, conventional single channel CNN may fail to consider the fact that additional cues may be embedded in the multi-channel recordings. In this paper, we explore the use of Multi-channel CNN for the classification task, which aims to extract features from different channels in an end-to-end manner. We conduct the evaluation compared with the conventional CNN and traditional Gaussian Mixture Model-based methods. Moreover, to improve the classification accuracy further, this paper explores the using of mixup method. In brief, mixup trains the neural network on linear combinations of pairs of the representation of audio scene examples and their labels. By employing the mixup approach for data argumentation, the novel model can provide higher prediction accuracy and robustness in contrast with previous models, while the generalization error can also be reduced on the evaluation data.