 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Channel Estimation and Signal Detection for ODDM-based ISAC Systems
Jun 01, 2024Inspired by providing reliable communications for high-mobility scenarios, in this letter, we investigate the channel estimation and signal detection in integrated sensing and communication~(ISAC) systems based on the orthogonal delay-Doppler multiplexing~(ODDM) modulation, which consists of a pulse-train that can achieve the orthogonality with respect to the resolution of the delay-Doppler~(DD) plane. To enhance the communication performance in the ODDM-based ISAC systems, we first propose a low-complexity approximation algorithm for channel estimation, which addresses the challenge of the high complexity from high resolution in the ODDM modulation, and achieves performance close to that of the maximum likelihood estimator scheme. Then, we employ the orthogonal approximate message-passing scheme to detect the symbols in the communication process based on the estimated channel information. Finally, simulation results show that the detection performance of ODDM is better than other multi-carrier modulation schemes. Specifically, the ODDM outperforms the orthogonal time frequency space scheme by 2.3 dB when the bit error ratio is $10^{-6}$.
Mean Field Game-based Waveform Precoding Design for Mobile Crowd Integrated Sensing, Communication, and Computation Systems
Sep 06, 2023



Data collection and processing timely is crucial for mobile crowd integrated sensing, communication, and computation~(ISCC) systems with various applications such as smart home and connected cars, which requires numerous integrated sensing and communication~(ISAC) devices to sense the targets and offload the data to the base station~(BS) for further processing. However, as the number of ISAC devices growing, there exists intensive interactions among ISAC devices in the processes of data collection and processing since they share the common network resources. In this paper, we consider the environment sensing problem in the large-scale mobile crowd ISCC systems and propose an efficient waveform precoding design algorithm based on the mean field game~(MFG). Specifically, to handle the complex interactions among large-scale ISAC devices, we first utilize the MFG method to transform the influence from other ISAC devices into the mean field term and derive the Fokker-Planck-Kolmogorov equation, which model the evolution of the system state. Then, we derive the cost function based on the mean field term and reformulate the waveform precoding design problem. Next, we utilize the G-prox primal-dual hybrid gradient algorithm to solve the reformulated problem and analyze the computational complexity of the proposed algorithm. Finally, simulation results demonstrate that the proposed algorithm can solve the interactions among large-scale ISAC devices effectively in the ISCC process. In addition, compared with other baselines, the proposed waveform precoding design algorithm has advantages in improving communication performance and reducing cost function.
* 13 pages,9 figures
General audio tagging with ensembling convolutional neural network and statistical features
Oct 30, 2018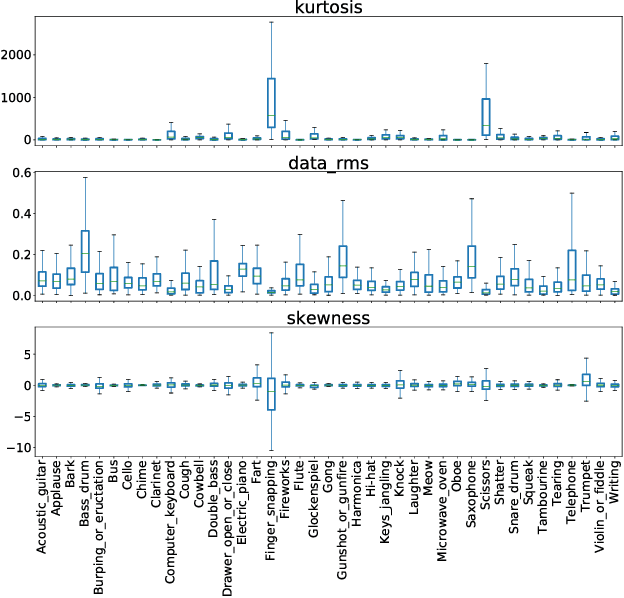
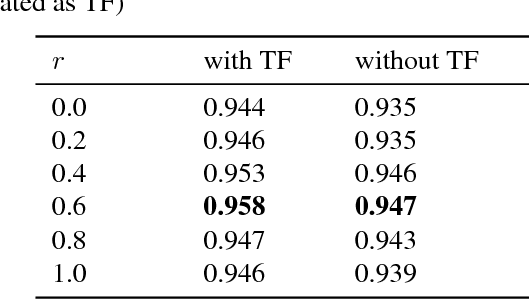
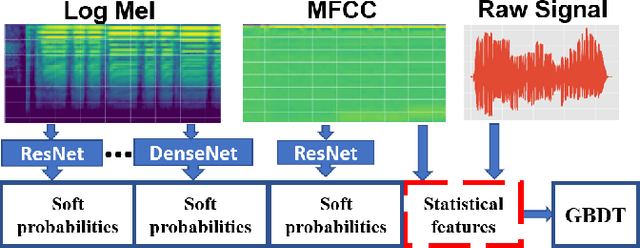
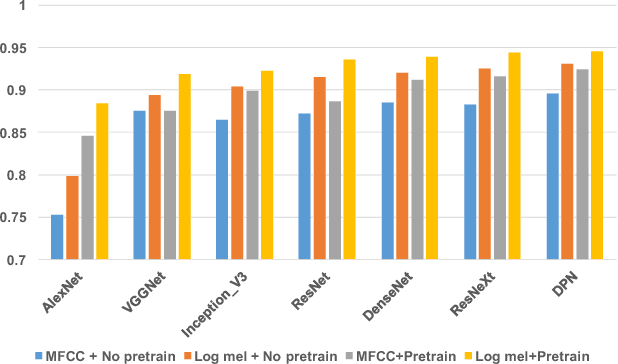
Audio tagging aims to infer descriptive labels from audio clips. Audio tagging is challenging due to the limited size of data and noisy labels. In this paper, we describe our solution for the DCASE 2018 Task 2 general audio tagging challenge. The contributions of our solution include: We investigated a variety of convolutional neural network architectures to solve the audio tagging task. Statistical features are applied to capture statistical patterns of audio features to improve the classification performance. Ensemble learning is applied to ensemble the outputs from the deep classifiers to utilize complementary information. a sample re-weight strategy is employed for ensemble training to address the noisy label problem. Our system achieves a mean average precision (mAP@3) of 0.958, outperforming the baseline system of 0.704. Our system ranked the 1st and 4th out of 558 submissions in the public and private leaderboard of DCASE 2018 Task 2 challenge. Our codes are available at https://github.com/Cocoxili/DCASE2018Task2/.
Mixup-Based Acoustic Scene Classification Using Multi-Channel Convolutional Neural Network
May 18, 2018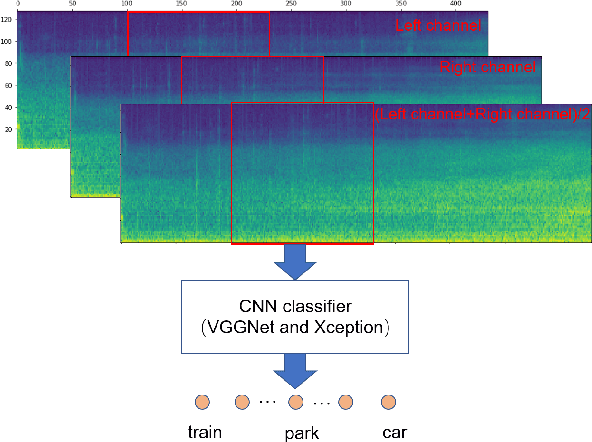
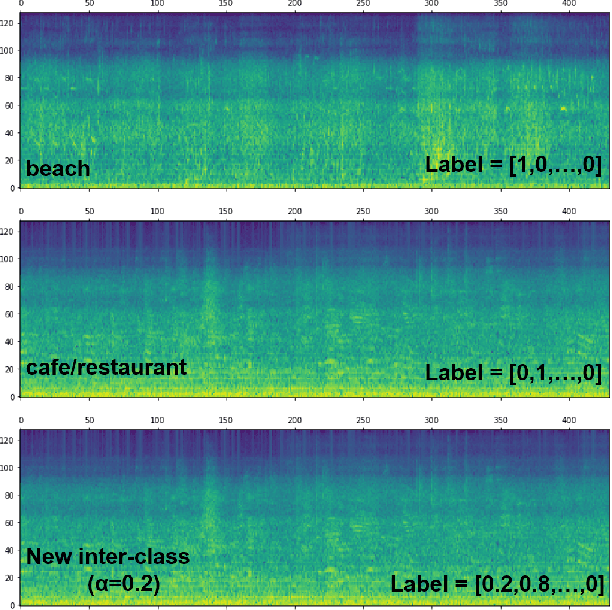
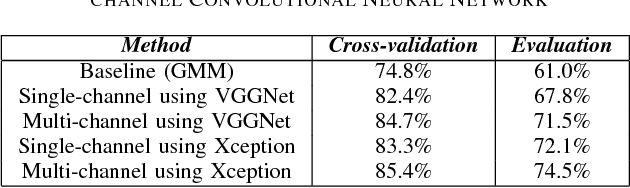
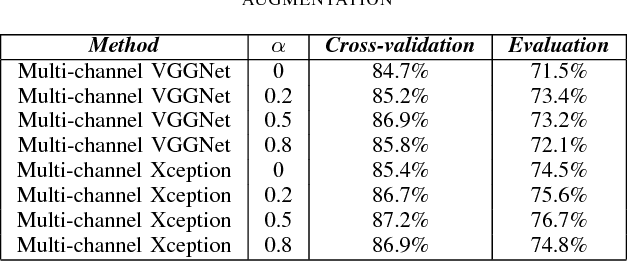
Audio scene classification, the problem of predicting class labels of audio scenes, has drawn lots of attention during the last several years. However, it remains challenging and falls short of accuracy and efficiency. Recently, Convolutional Neural Network (CNN)-based methods have achieved better performance with comparison to the traditional methods. Nevertheless, conventional single channel CNN may fail to consider the fact that additional cues may be embedded in the multi-channel recordings. In this paper, we explore the use of Multi-channel CNN for the classification task, which aims to extract features from different channels in an end-to-end manner. We conduct the evaluation compared with the conventional CNN and traditional Gaussian Mixture Model-based methods. Moreover, to improve the classification accuracy further, this paper explores the using of mixup method. In brief, mixup trains the neural network on linear combinations of pairs of the representation of audio scene examples and their labels. By employing the mixup approach for data argumentation, the novel model can provide higher prediction accuracy and robustness in contrast with previous models, while the generalization error can also be reduced on the evaluation data.