 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Enabled Semantic Communication Systems
Jul 19, 2024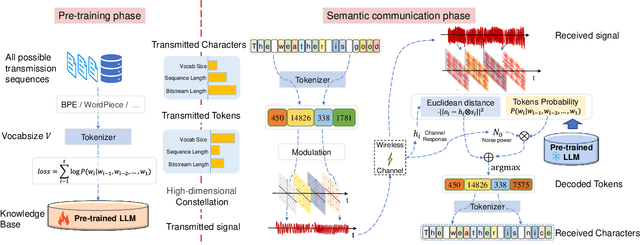
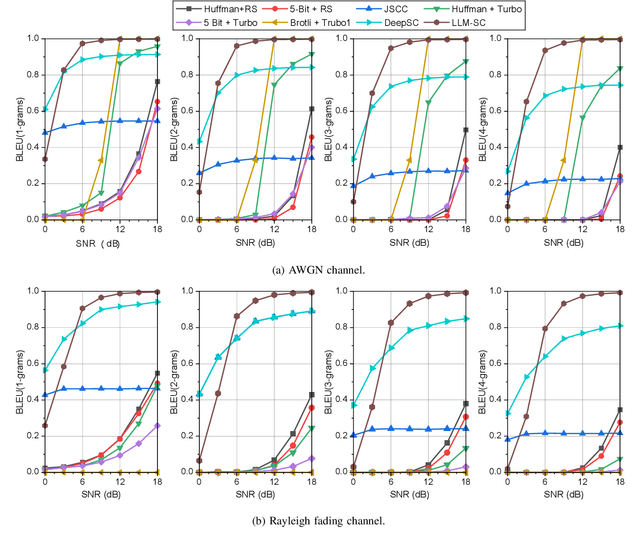
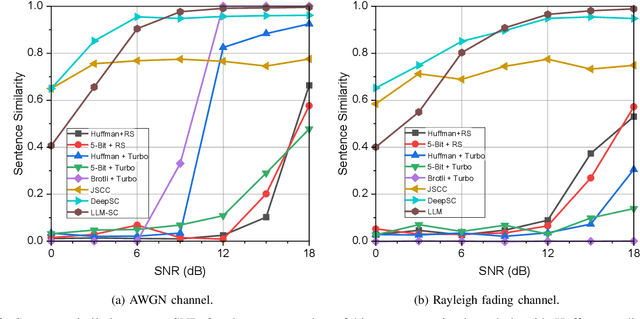
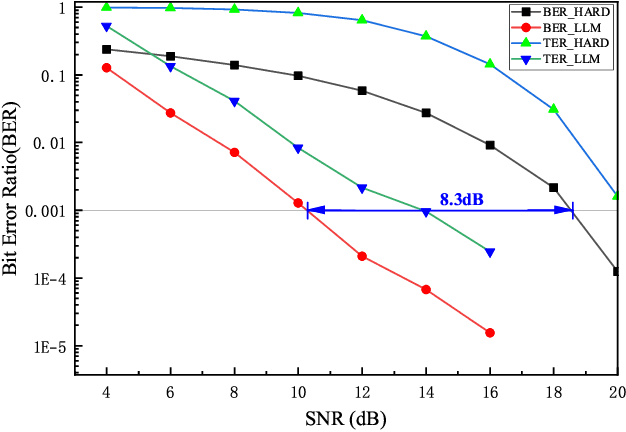
Large language models (LLMs) have recently demonstrated state-of-the-art performance across various natural language processing (NLP) tasks, achieving near-human levels in multiple language understanding challenges and aligning closely with the core principles of semantic communication. Inspired by LLMs' advancements in semantic processing, we propose an innovative LLM-enabled semantic communication system framework, named LLM-SC, that applies LLMs directly to the physical layer coding and decoding for the first time. By analyzing the relationship between the training process of LLMs and the optimization objectives of semantic communication, we propose training a semantic encoder through LLMs' tokenizer training and establishing a semantic knowledge base via the LLMs' unsupervised pre-training process. This knowledge base aids in constructing the optimal decoder by providing the prior probability of the transmitted language sequence. Based on this foundation, we derive the optimal decoding criterion for the receiver and introduce the beam search algorithm to further reduce the complexity. Furthermore, we assert that existing LLMs can be employed directly for LLM-SC without additional re-training or fine-tuning. Simulation results demonstrate that LLM-SC outperforms classical DeepSC at signal-to-noise ratios (SNR) exceeding 3 dB, enabling error-free transmission of semantic information under high SNR, which is unattainable by DeepSC. In addition to semantic-level performance, LLM-SC demonstrates compatibility with technical-level performance, achieving approximately 8 dB coding gain for a bit error ratio (BER) of $10^{-3}$ without any channel coding while maintaining the same joint source-channel coding rate as traditional communication systems.
FedH2L: Federated Learning with Model and Statistical Heterogeneity
Jan 27, 2021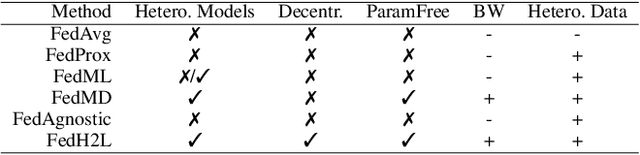
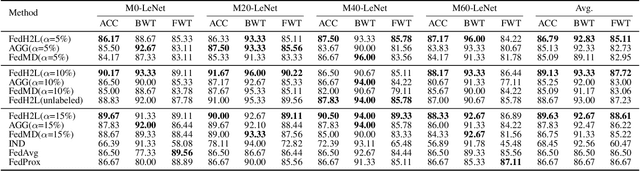
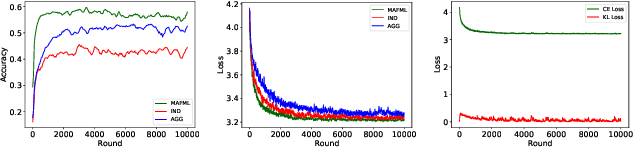
Federated learning (FL) enables distributed participants to collectively learn a strong global model without sacrificing their individual data privacy. Mainstream FL approaches require each participant to share a common network architecture and further assume that data are are sampled IID across participants. However, in real-world deployments participants may require heterogeneous network architectures; and the data distribution is almost certainly non-uniform across participants. To address these issues we introduce FedH2L, which is agnostic to both the model architecture and robust to different data distributions across participants. In contrast to approaches sharing parameters or gradients, FedH2L relies on mutual distillation, exchanging only posteriors on a shared seed set between participants in a decentralized manner. This makes it extremely bandwidth efficient, model agnostic, and crucially produces models capable of performing well on the whole data distribution when learning from heterogeneous silos.
General audio tagging with ensembling convolutional neural network and statistical features
Oct 30, 2018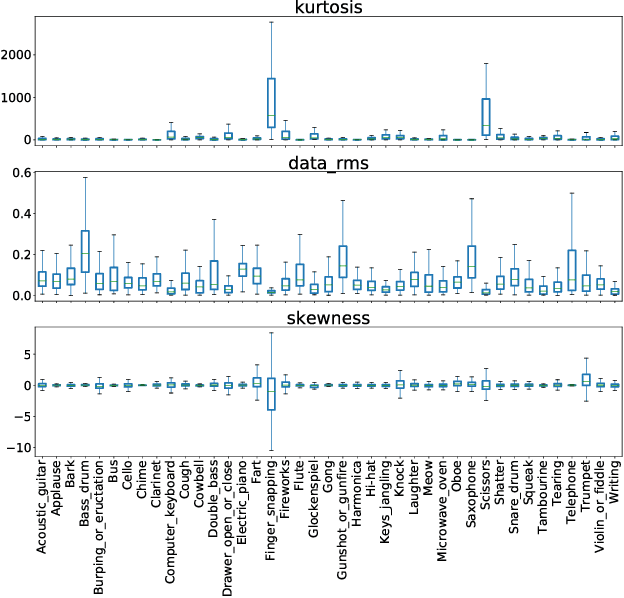
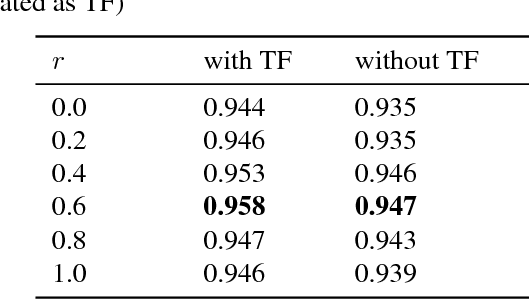
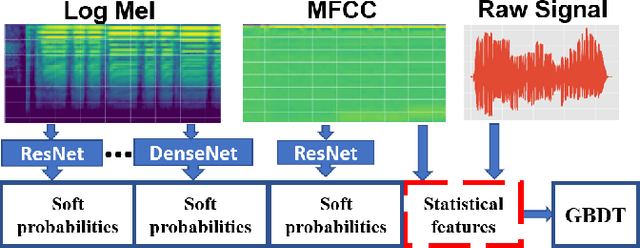
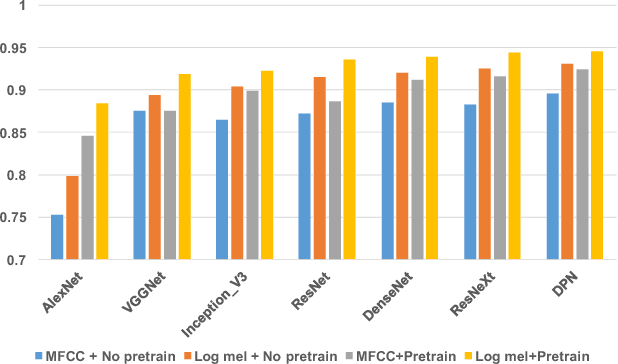
Audio tagging aims to infer descriptive labels from audio clips. Audio tagging is challenging due to the limited size of data and noisy labels. In this paper, we describe our solution for the DCASE 2018 Task 2 general audio tagging challenge. The contributions of our solution include: We investigated a variety of convolutional neural network architectures to solve the audio tagging task. Statistical features are applied to capture statistical patterns of audio features to improve the classification performance. Ensemble learning is applied to ensemble the outputs from the deep classifiers to utilize complementary information. a sample re-weight strategy is employed for ensemble training to address the noisy label problem. Our system achieves a mean average precision (mAP@3) of 0.958, outperforming the baseline system of 0.704. Our system ranked the 1st and 4th out of 558 submissions in the public and private leaderboard of DCASE 2018 Task 2 challenge. Our codes are available at https://github.com/Cocoxili/DCASE2018Task2/.
Collaborative Deep Learning Across Multiple Data Centers
Oct 16, 2018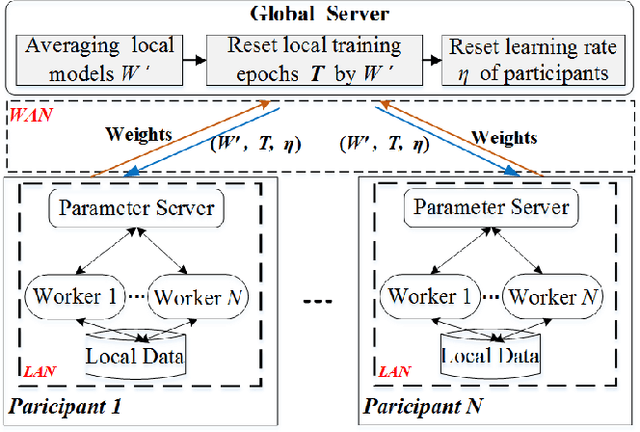
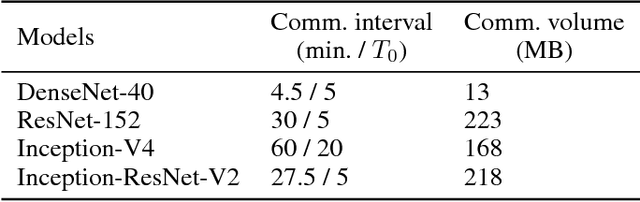
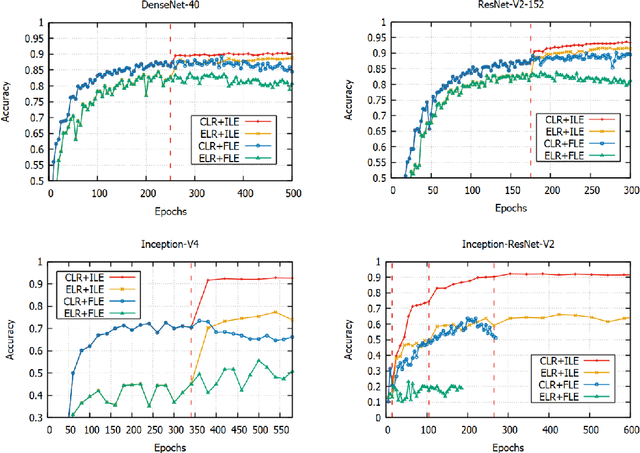
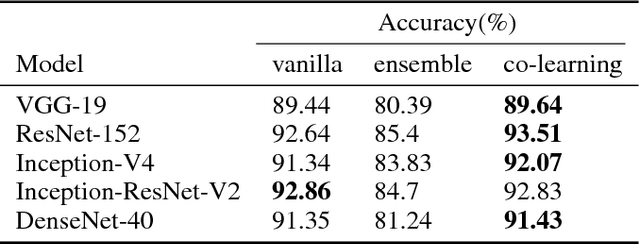
Valuable training data is often owned by independent organizations and located in multiple data centers. Most deep learning approaches require to centralize the multi-datacenter data for performance purpose. In practice, however, it is often infeasible to transfer all data to a centralized data center due to not only bandwidth limitation but also the constraints of privacy regulations. Model averaging is a conventional choice for data parallelized training, but its ineffectiveness is claimed by previous studies as deep neural networks are often non-convex. In this paper, we argue that model averaging can be effective in the decentralized environment by using two strategies, namely, the cyclical learning rate and the increased number of epochs for local model training. With the two strategies, we show that model averaging can provide competitive performance in the decentralized mode compared to the data-centralized one. In a practical environment with multiple data centers, we conduct extensive experiments using state-of-the-art deep network architectures on different types of data. Results demonstrate the effectiveness and robustness of the proposed method.
Sample Dropout for Audio Scene Classification Using Multi-Scale Dense Connected Convolutional Neural Network
Jun 12, 2018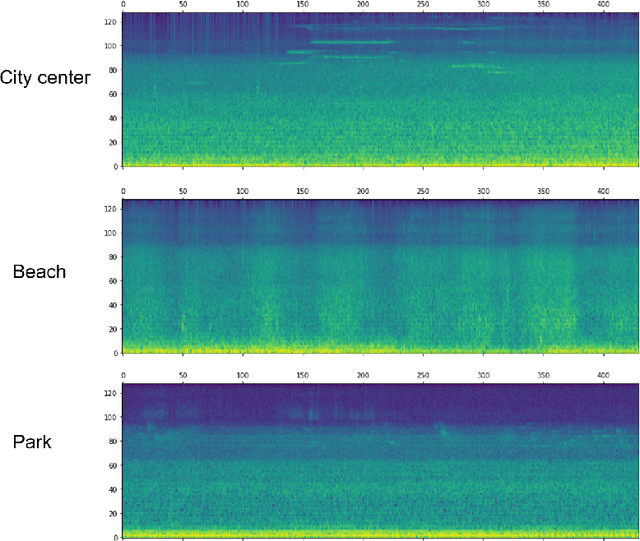
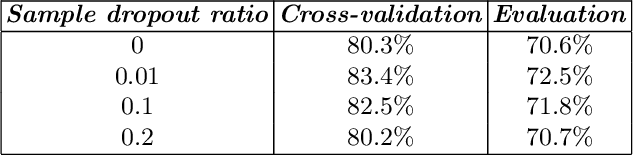
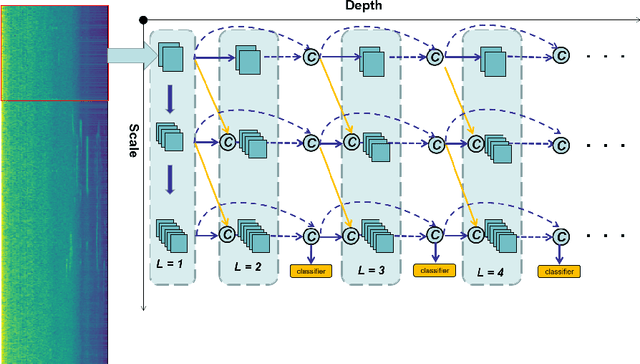

Acoustic scene classification is an intricate problem for a machine. As an emerging field of research, deep Convolutional Neural Networks (CNN) achieve convincing results. In this paper, we explore the use of multi-scale Dense connected convolutional neural network (DenseNet) for the classification task, with the goal to improve the classification performance as multi-scale features can be extracted from the time-frequency representation of the audio signal. On the other hand, most of previous CNN-based audio scene classification approaches aim to improve the classification accuracy, by employing different regularization techniques, such as the dropout of hidden units and data augmentation, to reduce overfitting. It is widely known that outliers in the training set have a high negative influence on the trained model, and culling the outliers may improve the classification performance, while it is often under-explored in previous studies. In this paper, inspired by the silence removal in the speech signal processing, a novel sample dropout approach is proposed, which aims to remove outliers in the training dataset. Using the DCASE 2017 audio scene classification datasets, the experimental results demonstrates the proposed multi-scale DenseNet providing a superior performance than the traditional single-scale DenseNet, while the sample dropout method can further improve the classification robustness of multi-scale DenseNet.
Mixup-Based Acoustic Scene Classification Using Multi-Channel Convolutional Neural Network
May 18, 2018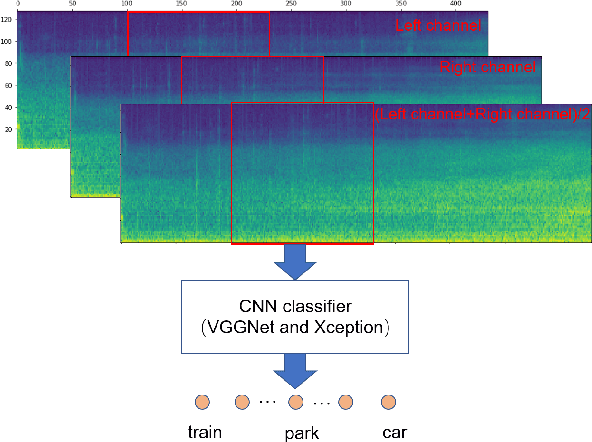
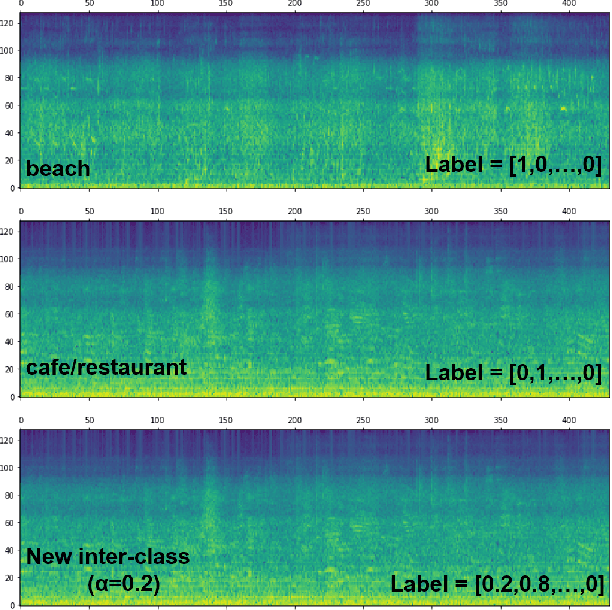
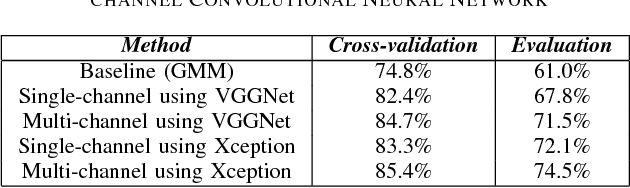
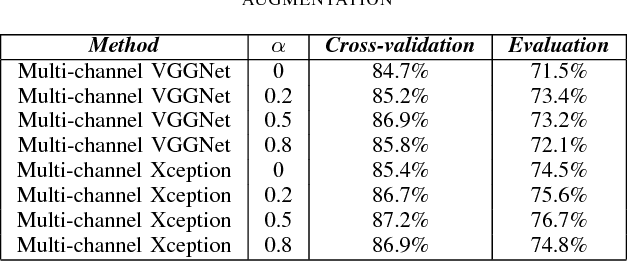
Audio scene classification, the problem of predicting class labels of audio scenes, has drawn lots of attention during the last several years. However, it remains challenging and falls short of accuracy and efficiency. Recently, Convolutional Neural Network (CNN)-based methods have achieved better performance with comparison to the traditional methods. Nevertheless, conventional single channel CNN may fail to consider the fact that additional cues may be embedded in the multi-channel recordings. In this paper, we explore the use of Multi-channel CNN for the classification task, which aims to extract features from different channels in an end-to-end manner. We conduct the evaluation compared with the conventional CNN and traditional Gaussian Mixture Model-based methods. Moreover, to improve the classification accuracy further, this paper explores the using of mixup method. In brief, mixup trains the neural network on linear combinations of pairs of the representation of audio scene examples and their labels. By employing the mixup approach for data argumentation, the novel model can provide higher prediction accuracy and robustness in contrast with previous models, while the generalization error can also be reduced on the evaluation data.