 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Dropout for Audio Scene Classification Using Multi-Scale Dense Connected Convolutional Neural Network
Paper and Code
Jun 12, 2018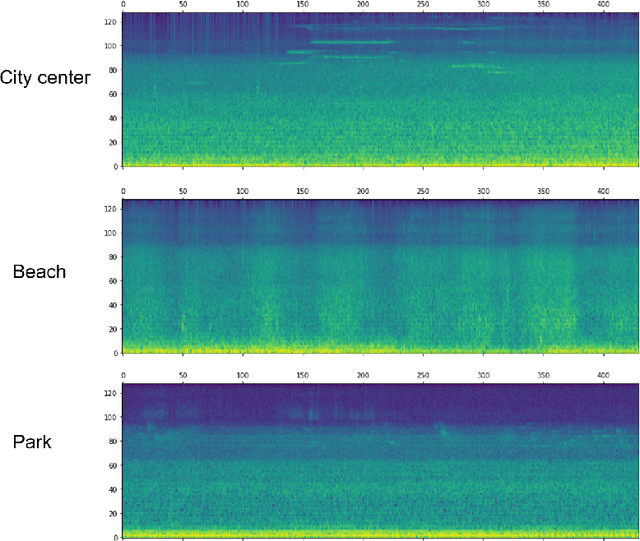
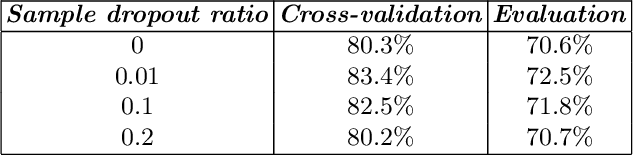
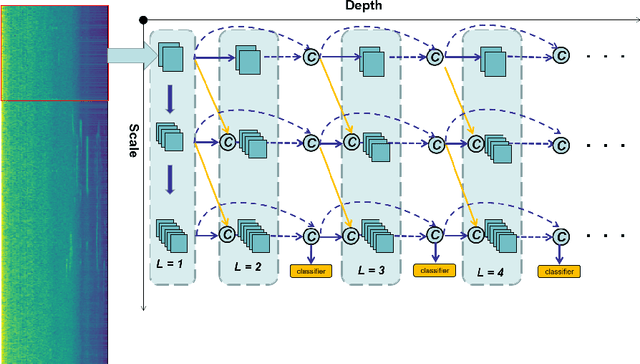

Acoustic scene classification is an intricate problem for a machine. As an emerging field of research, deep Convolutional Neural Networks (CNN) achieve convincing results. In this paper, we explore the use of multi-scale Dense connected convolutional neural network (DenseNet) for the classification task, with the goal to improve the classification performance as multi-scale features can be extracted from the time-frequency representation of the audio signal. On the other hand, most of previous CNN-based audio scene classification approaches aim to improve the classification accuracy, by employing different regularization techniques, such as the dropout of hidden units and data augmentation, to reduce overfitting. It is widely known that outliers in the training set have a high negative influence on the trained model, and culling the outliers may improve the classification performance, while it is often under-explored in previous studies. In this paper, inspired by the silence removal in the speech signal processing, a novel sample dropout approach is proposed, which aims to remove outliers in the training dataset. Using the DCASE 2017 audio scene classification datasets, the experimental results demonstrates the proposed multi-scale DenseNet providing a superior performance than the traditional single-scale DenseNet, while the sample dropout method can further improve the classification robustness of multi-scale DenseNet.