 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Enabled Semantic Communication Systems
Jul 19, 2024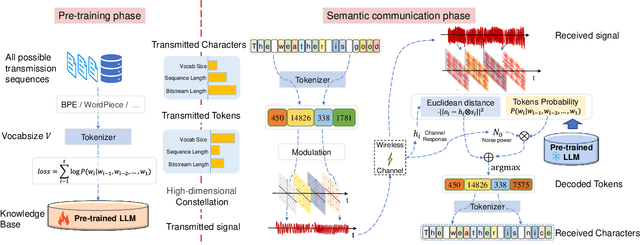
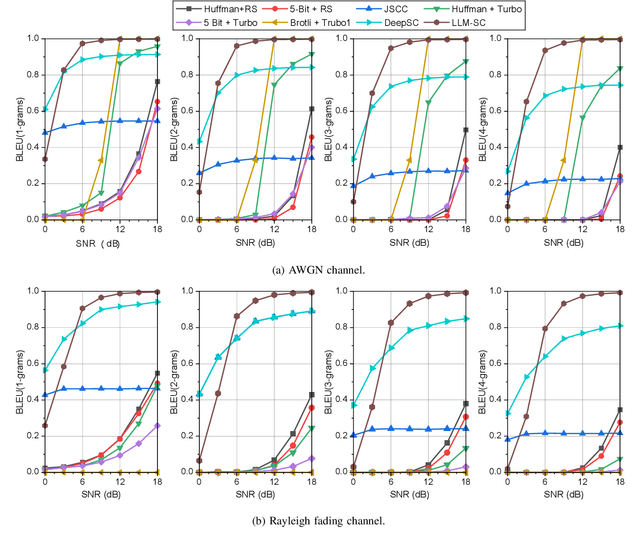
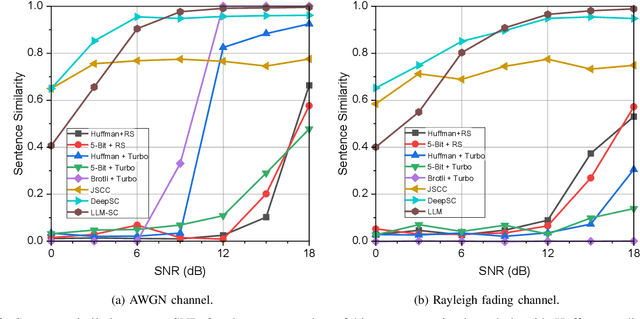
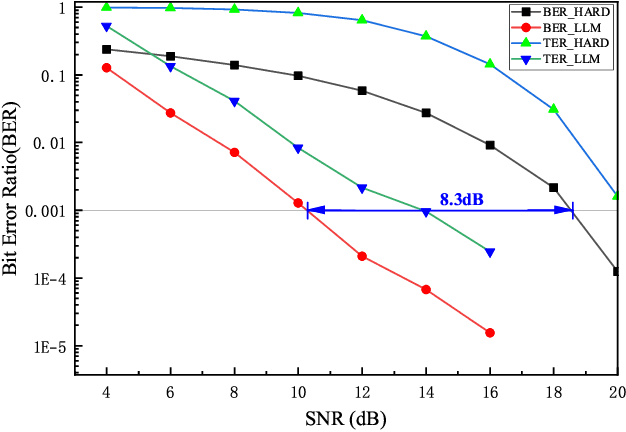
Large language models (LLMs) have recently demonstrated state-of-the-art performance across various natural language processing (NLP) tasks, achieving near-human levels in multiple language understanding challenges and aligning closely with the core principles of semantic communication. Inspired by LLMs' advancements in semantic processing, we propose an innovative LLM-enabled semantic communication system framework, named LLM-SC, that applies LLMs directly to the physical layer coding and decoding for the first time. By analyzing the relationship between the training process of LLMs and the optimization objectives of semantic communication, we propose training a semantic encoder through LLMs' tokenizer training and establishing a semantic knowledge base via the LLMs' unsupervised pre-training process. This knowledge base aids in constructing the optimal decoder by providing the prior probability of the transmitted language sequence. Based on this foundation, we derive the optimal decoding criterion for the receiver and introduce the beam search algorithm to further reduce the complexity. Furthermore, we assert that existing LLMs can be employed directly for LLM-SC without additional re-training or fine-tuning. Simulation results demonstrate that LLM-SC outperforms classical DeepSC at signal-to-noise ratios (SNR) exceeding 3 dB, enabling error-free transmission of semantic information under high SNR, which is unattainable by DeepSC. In addition to semantic-level performance, LLM-SC demonstrates compatibility with technical-level performance, achieving approximately 8 dB coding gain for a bit error ratio (BER) of $10^{-3}$ without any channel coding while maintaining the same joint source-channel coding rate as traditional communication systems.
Sample Dropout for Audio Scene Classification Using Multi-Scale Dense Connected Convolutional Neural Network
Jun 12, 2018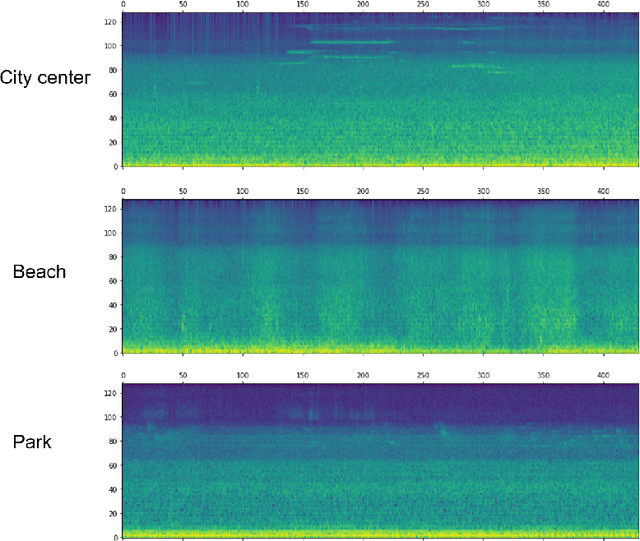
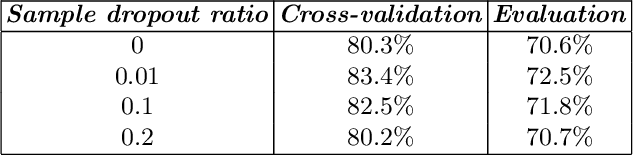
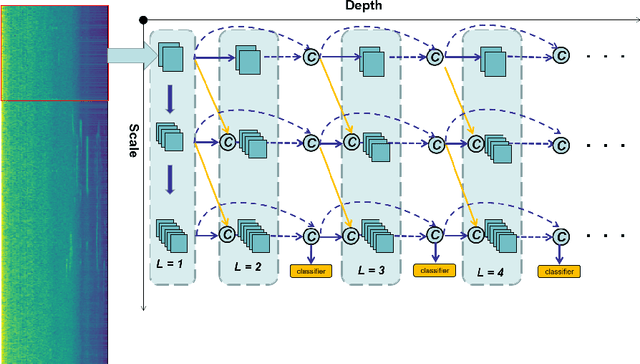

Acoustic scene classification is an intricate problem for a machine. As an emerging field of research, deep Convolutional Neural Networks (CNN) achieve convincing results. In this paper, we explore the use of multi-scale Dense connected convolutional neural network (DenseNet) for the classification task, with the goal to improve the classification performance as multi-scale features can be extracted from the time-frequency representation of the audio signal. On the other hand, most of previous CNN-based audio scene classification approaches aim to improve the classification accuracy, by employing different regularization techniques, such as the dropout of hidden units and data augmentation, to reduce overfitting. It is widely known that outliers in the training set have a high negative influence on the trained model, and culling the outliers may improve the classification performance, while it is often under-explored in previous studies. In this paper, inspired by the silence removal in the speech signal processing, a novel sample dropout approach is proposed, which aims to remove outliers in the training dataset. Using the DCASE 2017 audio scene classification datasets, the experimental results demonstrates the proposed multi-scale DenseNet providing a superior performance than the traditional single-scale DenseNet, while the sample dropout method can further improve the classification robustness of multi-scale DenseNet.