 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent Homology for Structural Characterization in Disordered Systems
Nov 22, 2024



We propose a unified framework based on persistent homology (PH) to characterize both local and global structures in disordered systems. It can simultaneously generate local and global descriptors using the same algorithm and data structure, and has shown to be highly effective and interpretable in predicting particle rearrangements and classifying global phases. Based on this framework, we define a non-parametric metric, the Separation Index (SI), which not only outperforms traditional bond-orientational order parameters in phase classification tasks but also establishes a connection between particle environments and the global phase structure. Our methods provide an effective framework for understanding and analyzing the properties of disordered materials, with broad potential applications in materials science and even wider studies of complex systems.
Large Language Model Enabled Semantic Communication Systems
Jul 19, 2024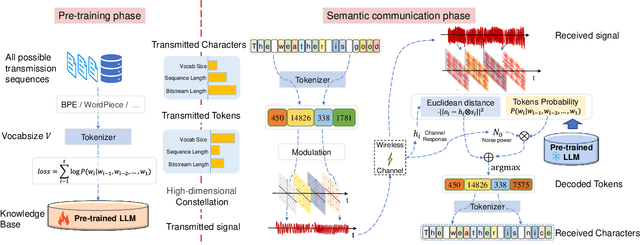
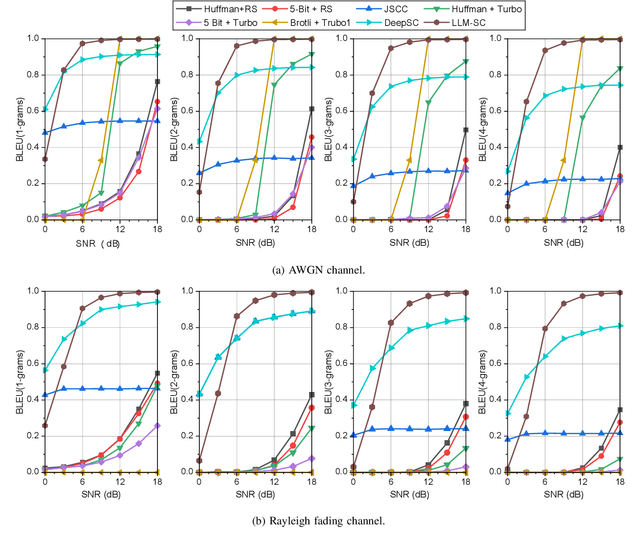
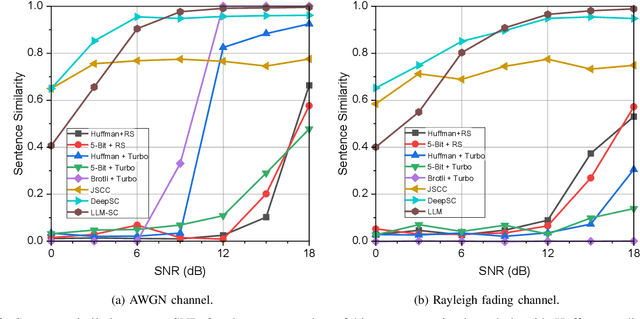
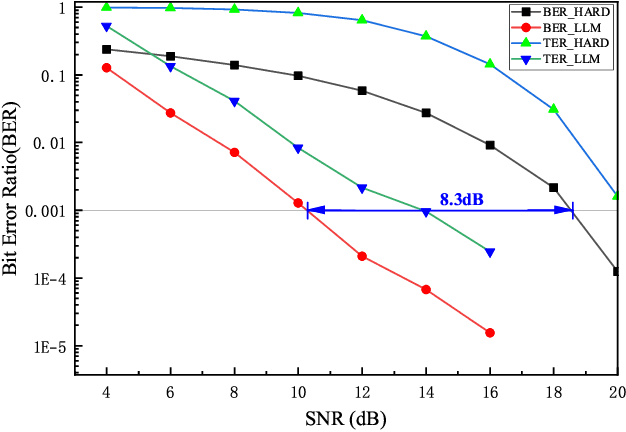
Large language models (LLMs) have recently demonstrated state-of-the-art performance across various natural language processing (NLP) tasks, achieving near-human levels in multiple language understanding challenges and aligning closely with the core principles of semantic communication. Inspired by LLMs' advancements in semantic processing, we propose an innovative LLM-enabled semantic communication system framework, named LLM-SC, that applies LLMs directly to the physical layer coding and decoding for the first time. By analyzing the relationship between the training process of LLMs and the optimization objectives of semantic communication, we propose training a semantic encoder through LLMs' tokenizer training and establishing a semantic knowledge base via the LLMs' unsupervised pre-training process. This knowledge base aids in constructing the optimal decoder by providing the prior probability of the transmitted language sequence. Based on this foundation, we derive the optimal decoding criterion for the receiver and introduce the beam search algorithm to further reduce the complexity. Furthermore, we assert that existing LLMs can be employed directly for LLM-SC without additional re-training or fine-tuning. Simulation results demonstrate that LLM-SC outperforms classical DeepSC at signal-to-noise ratios (SNR) exceeding 3 dB, enabling error-free transmission of semantic information under high SNR, which is unattainable by DeepSC. In addition to semantic-level performance, LLM-SC demonstrates compatibility with technical-level performance, achieving approximately 8 dB coding gain for a bit error ratio (BER) of $10^{-3}$ without any channel coding while maintaining the same joint source-channel coding rate as traditional communication systems.
Lexical semantics enhanced neural word embeddings
Oct 03, 2022
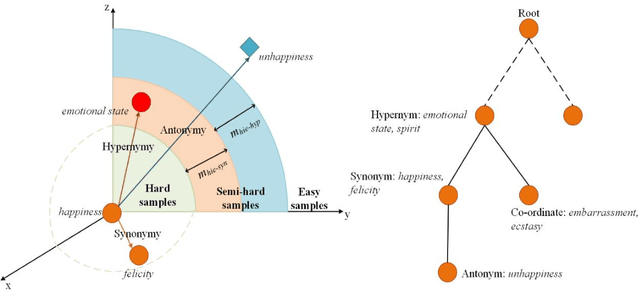
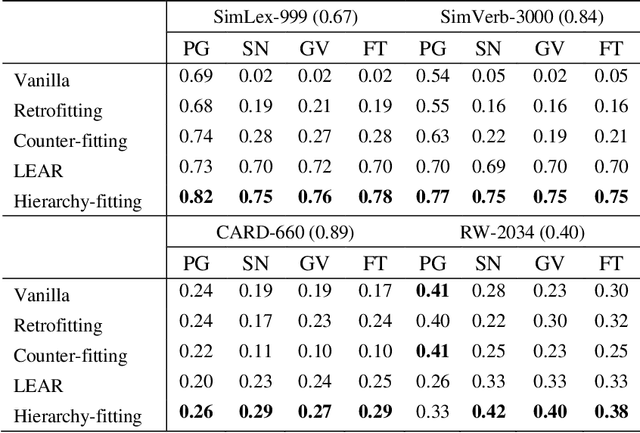
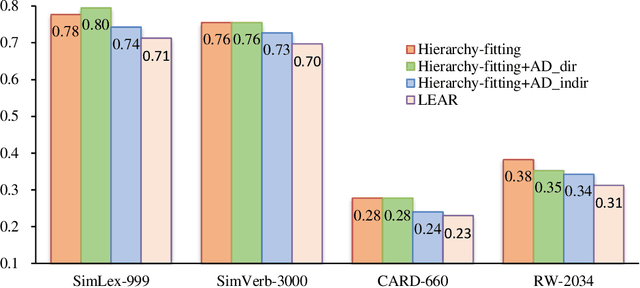
Current breakthroughs in natural language processing have benefited dramatically from neural language models, through which distributional semantics can leverage neural data representations to facilitate downstream applications. Since neural embeddings use context prediction on word co-occurrences to yield dense vectors, they are inevitably prone to capture more semantic association than semantic similarity. To improve vector space models in deriving semantic similarity, we post-process neural word embeddings through deep metric learning, through which we can inject lexical-semantic relations, including syn/antonymy and hypo/hypernymy, into a distributional space. We introduce hierarchy-fitting, a novel semantic specialization approach to modelling semantic similarity nuances inherently stored in the IS-A hierarchies. Hierarchy-fitting attains state-of-the-art results on the common- and rare-word benchmark datasets for deriving semantic similarity from neural word embeddings. It also incorporates an asymmetric distance function to specialize hypernymy's directionality explicitly, through which it significantly improves vanilla embeddings in multiple evaluation tasks of detecting hypernymy and directionality without negative impacts on semantic similarity judgement. The results demonstrate the efficacy of hierarchy-fitting in specializing neural embeddings with semantic relations in late fusion, potentially expanding its applicability to aggregating heterogeneous data and various knowledge resources for learning multimodal semantic spaces.