 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical semantics enhanced neural word embeddings
Oct 03, 2022
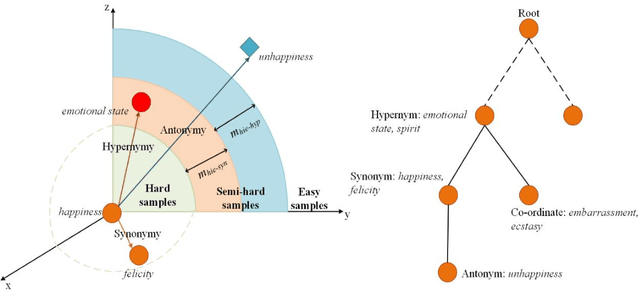
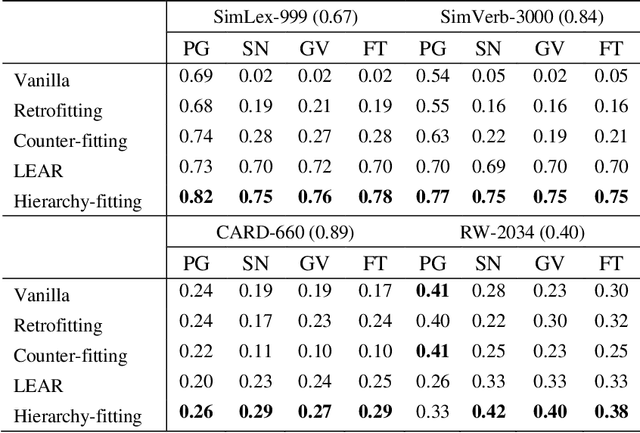
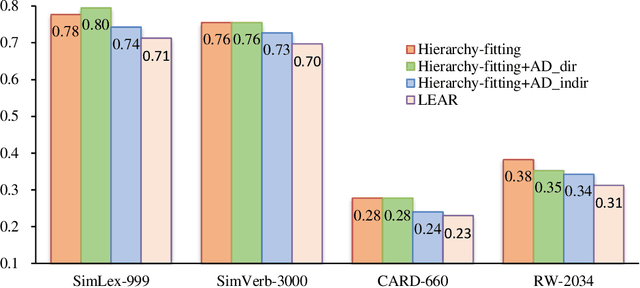
Current breakthroughs in natural language processing have benefited dramatically from neural language models, through which distributional semantics can leverage neural data representations to facilitate downstream applications. Since neural embeddings use context prediction on word co-occurrences to yield dense vectors, they are inevitably prone to capture more semantic association than semantic similarity. To improve vector space models in deriving semantic similarity, we post-process neural word embeddings through deep metric learning, through which we can inject lexical-semantic relations, including syn/antonymy and hypo/hypernymy, into a distributional space. We introduce hierarchy-fitting, a novel semantic specialization approach to modelling semantic similarity nuances inherently stored in the IS-A hierarchies. Hierarchy-fitting attains state-of-the-art results on the common- and rare-word benchmark datasets for deriving semantic similarity from neural word embeddings. It also incorporates an asymmetric distance function to specialize hypernymy's directionality explicitly, through which it significantly improves vanilla embeddings in multiple evaluation tasks of detecting hypernymy and directionality without negative impacts on semantic similarity judgement. The results demonstrate the efficacy of hierarchy-fitting in specializing neural embeddings with semantic relations in late fusion, potentially expanding its applicability to aggregating heterogeneous data and various knowledge resources for learning multimodal semantic spaces.
Synonym Detection Using Syntactic Dependency And Neural Embeddings
Sep 30, 2022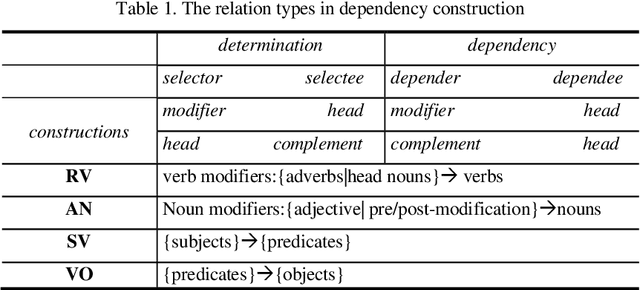
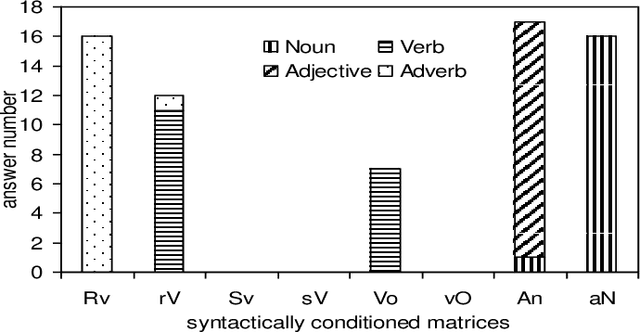
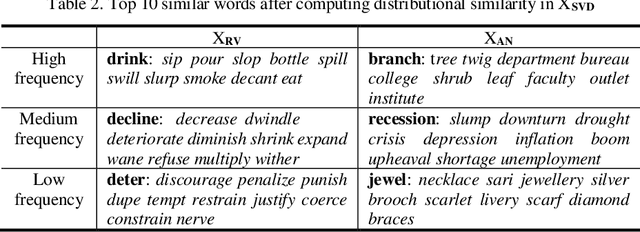
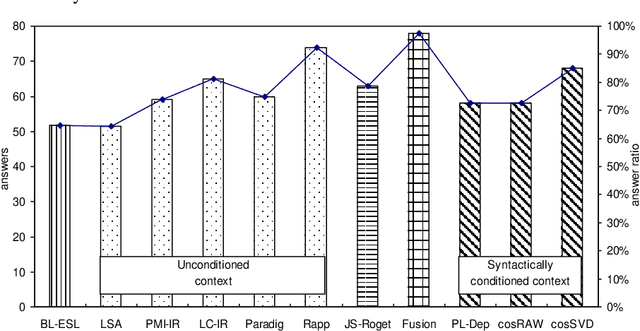
Recent advances on the Vector Space Model have significantly improved some NLP applications such as neural machine translation and natural language generation. Although word co-occurrences in context have been widely used in counting-/predicting-based distributional models, the role of syntactic dependencies in deriving distributional semantics has not yet been thoroughly investigated. By comparing various Vector Space Models in detecting synonyms in TOEFL, we systematically study the salience of syntactic dependencies in accounting for distributional similarity. We separate syntactic dependencies into different groups according to their various grammatical roles and then use context-counting to construct their corresponding raw and SVD-compressed matrices. Moreover, using the same training hyperparameters and corpora, we study typical neural embeddings in the evaluation. We further study the effectiveness of injecting human-compiled semantic knowledge into neural embeddings on computing distributional similarity. Our results show that the syntactically conditioned contexts can interpret lexical semantics better than the unconditioned ones, whereas retrofitting neural embeddings with semantic knowledge can significantly improve synonym detection.
Evaluation of taxonomic and neural embedding methods for calculating semantic similarity
Sep 30, 2022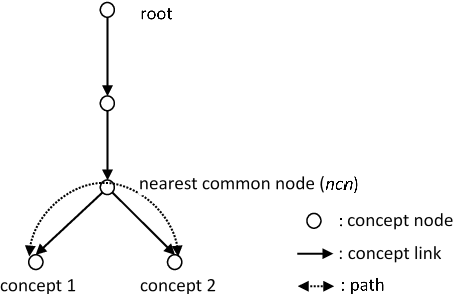
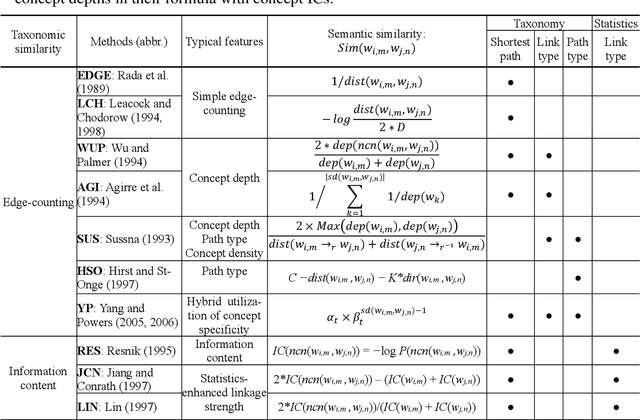
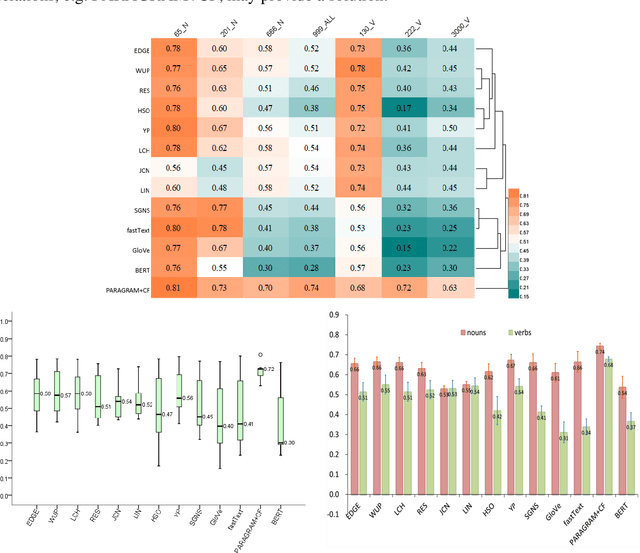
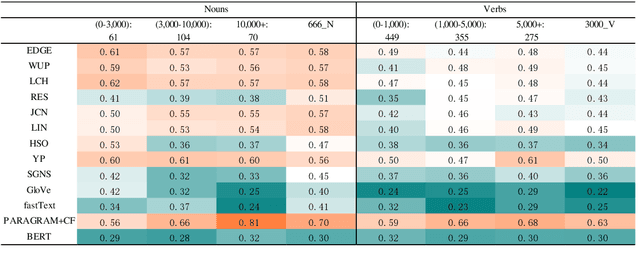
Modelling semantic similarity plays a fundamental role in lexical semantic applications. A natural way of calculating semantic similarity is to access handcrafted semantic networks, but similarity prediction can also be anticipated in a distributional vector space. Similarity calculation continues to be a challenging task, even with the latest breakthroughs in deep neural language models. We first examined popular methodologies in measuring taxonomic similarity, including edge-counting that solely employs semantic relations in a taxonomy, as well as the complex methods that estimate concept specificity. We further extrapolated three weighting factors in modelling taxonomic similarity. To study the distinct mechanisms between taxonomic and distributional similarity measures, we ran head-to-head comparisons of each measure with human similarity judgements from the perspectives of word frequency, polysemy degree and similarity intensity. Our findings suggest that without fine-tuning the uniform distance, taxonomic similarity measures can depend on the shortest path length as a prime factor to predict semantic similarity; in contrast to distributional semantics, edge-counting is free from sense distribution bias in use and can measure word similarity both literally and metaphorically; the synergy of retrofitting neural embeddings with concept relations in similarity prediction may indicate a new trend to leverage knowledge bases on transfer learning. It appears that a large gap still exists on computing semantic similarity among different ranges of word frequency, polysemous degree and similarity intensity.