 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynonym Detection Using Syntactic Dependency And Neural Embeddings
Sep 30, 2022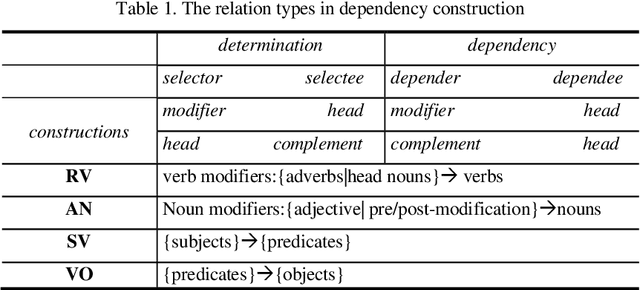
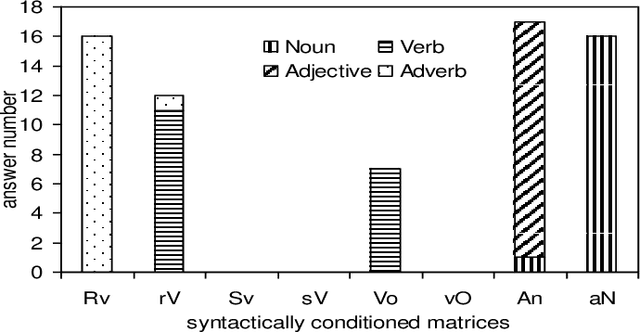
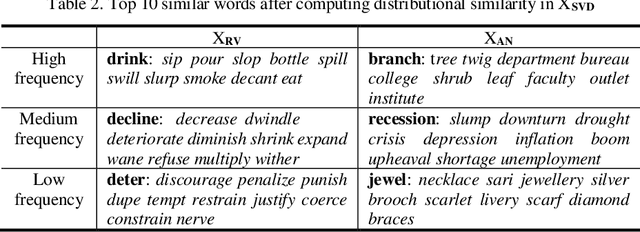
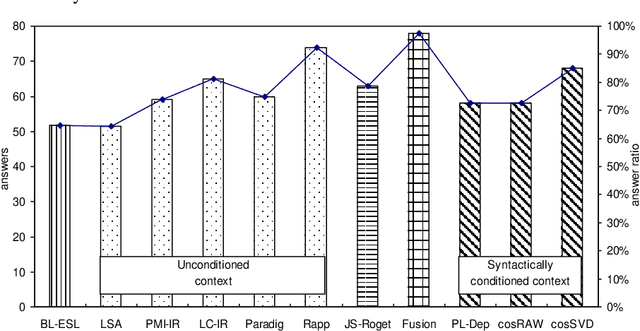
Recent advances on the Vector Space Model have significantly improved some NLP applications such as neural machine translation and natural language generation. Although word co-occurrences in context have been widely used in counting-/predicting-based distributional models, the role of syntactic dependencies in deriving distributional semantics has not yet been thoroughly investigated. By comparing various Vector Space Models in detecting synonyms in TOEFL, we systematically study the salience of syntactic dependencies in accounting for distributional similarity. We separate syntactic dependencies into different groups according to their various grammatical roles and then use context-counting to construct their corresponding raw and SVD-compressed matrices. Moreover, using the same training hyperparameters and corpora, we study typical neural embeddings in the evaluation. We further study the effectiveness of injecting human-compiled semantic knowledge into neural embeddings on computing distributional similarity. Our results show that the syntactically conditioned contexts can interpret lexical semantics better than the unconditioned ones, whereas retrofitting neural embeddings with semantic knowledge can significantly improve synonym detection.