 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of taxonomic and neural embedding methods for calculating semantic similarity
Paper and Code
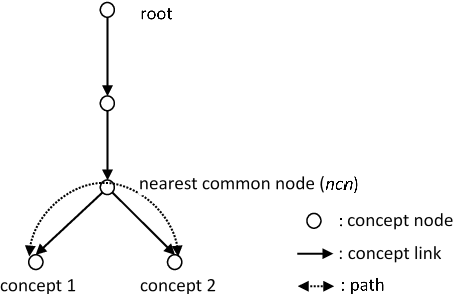
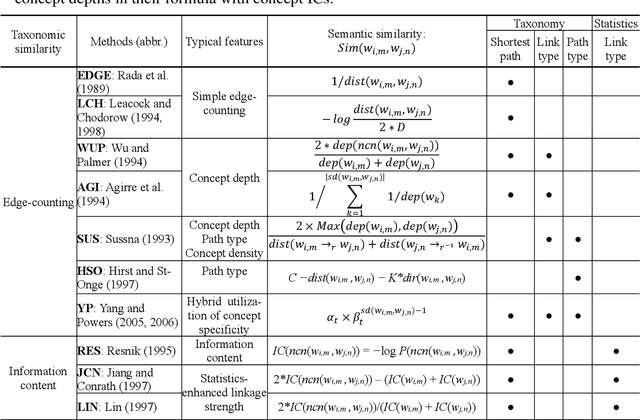
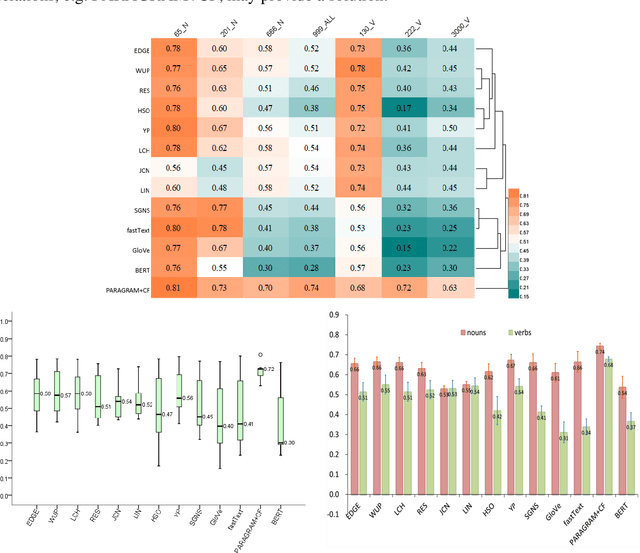
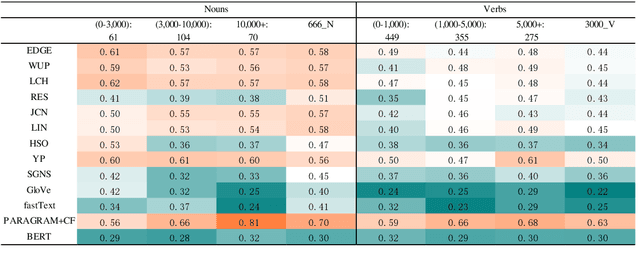
Modelling semantic similarity plays a fundamental role in lexical semantic applications. A natural way of calculating semantic similarity is to access handcrafted semantic networks, but similarity prediction can also be anticipated in a distributional vector space. Similarity calculation continues to be a challenging task, even with the latest breakthroughs in deep neural language models. We first examined popular methodologies in measuring taxonomic similarity, including edge-counting that solely employs semantic relations in a taxonomy, as well as the complex methods that estimate concept specificity. We further extrapolated three weighting factors in modelling taxonomic similarity. To study the distinct mechanisms between taxonomic and distributional similarity measures, we ran head-to-head comparisons of each measure with human similarity judgements from the perspectives of word frequency, polysemy degree and similarity intensity. Our findings suggest that without fine-tuning the uniform distance, taxonomic similarity measures can depend on the shortest path length as a prime factor to predict semantic similarity; in contrast to distributional semantics, edge-counting is free from sense distribution bias in use and can measure word similarity both literally and metaphorically; the synergy of retrofitting neural embeddings with concept relations in similarity prediction may indicate a new trend to leverage knowledge bases on transfer learning. It appears that a large gap still exists on computing semantic similarity among different ranges of word frequency, polysemous degree and similarity intensity.