 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical semantics enhanced neural word embeddings
Oct 03, 2022
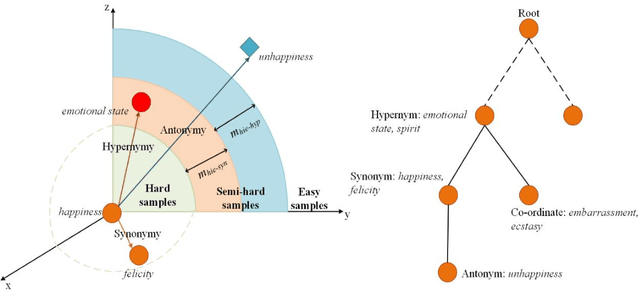
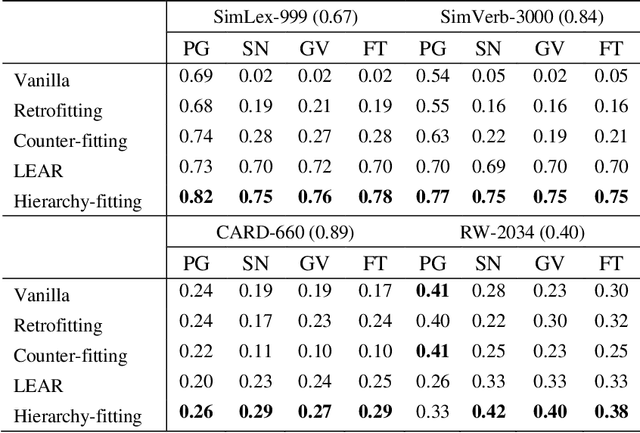
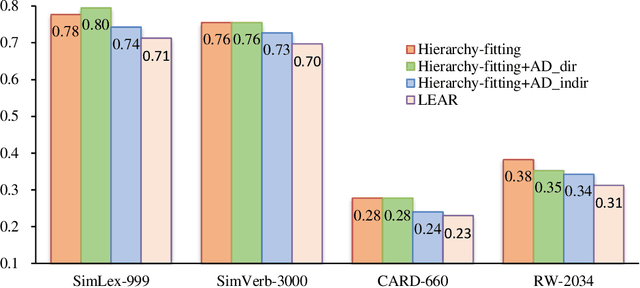
Current breakthroughs in natural language processing have benefited dramatically from neural language models, through which distributional semantics can leverage neural data representations to facilitate downstream applications. Since neural embeddings use context prediction on word co-occurrences to yield dense vectors, they are inevitably prone to capture more semantic association than semantic similarity. To improve vector space models in deriving semantic similarity, we post-process neural word embeddings through deep metric learning, through which we can inject lexical-semantic relations, including syn/antonymy and hypo/hypernymy, into a distributional space. We introduce hierarchy-fitting, a novel semantic specialization approach to modelling semantic similarity nuances inherently stored in the IS-A hierarchies. Hierarchy-fitting attains state-of-the-art results on the common- and rare-word benchmark datasets for deriving semantic similarity from neural word embeddings. It also incorporates an asymmetric distance function to specialize hypernymy's directionality explicitly, through which it significantly improves vanilla embeddings in multiple evaluation tasks of detecting hypernymy and directionality without negative impacts on semantic similarity judgement. The results demonstrate the efficacy of hierarchy-fitting in specializing neural embeddings with semantic relations in late fusion, potentially expanding its applicability to aggregating heterogeneous data and various knowledge resources for learning multimodal semantic spaces.