 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Voice-Face Representation Learning by Cross-Modal Prototype Contrast
May 02, 2022
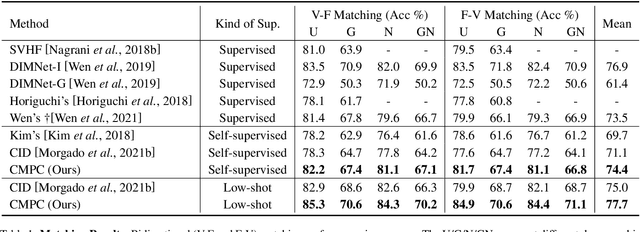
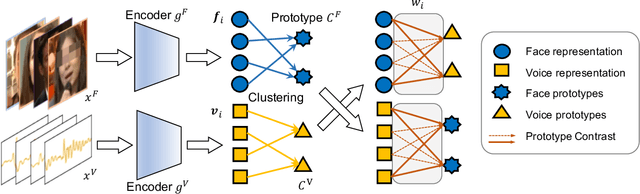
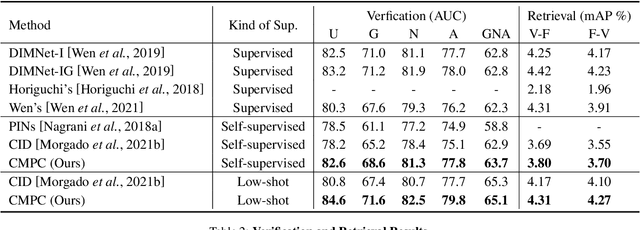
We present an approach to learn voice-face representations from the talking face videos, without any identity labels. Previous works employ cross-modal instance discrimination tasks to establish the correlation of voice and face. These methods neglect the semantic content of different videos, introducing false-negative pairs as training noise. Furthermore, the positive pairs are constructed based on the natural correlation between audio clips and visual frames. However, this correlation might be weak or inaccurate in a large amount of real-world data, which leads to deviating positives into the contrastive paradigm. To address these issues, we propose the cross-modal prototype contrastive learning (CMPC), which takes advantage of contrastive methods and resists adverse effects of false negatives and deviate positives. On one hand, CMPC could learn the intra-class invariance by constructing semantic-wise positives via unsupervised clustering in different modalities. On the other hand, by comparing the similarities of cross-modal instances from that of cross-modal prototypes, we dynamically recalibrate the unlearnable instances' contribution to overall loss. Experiments show that the proposed approach outperforms state-of-the-art unsupervised methods on various voice-face association evaluation protocols. Additionally, in the low-shot supervision setting, our method also has a significant improvement compared to previous instance-wise contrastive learning.
Audio Tagging by Cross Filtering Noisy Labels
Jul 16, 2020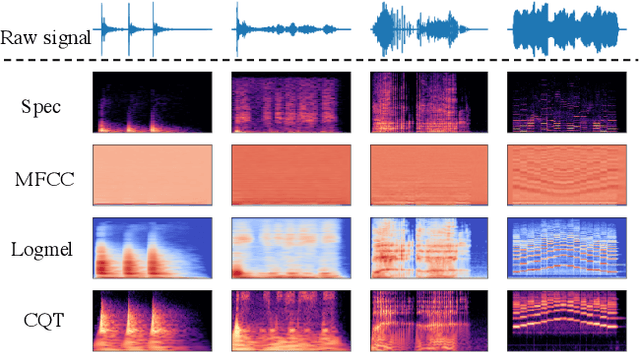
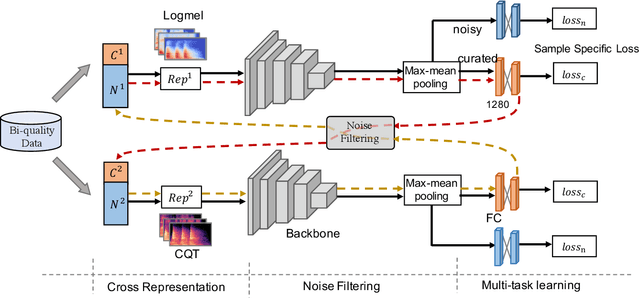
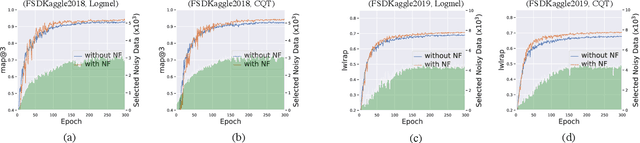
High quality labeled datasets have allowed deep learning to achieve impressive results on many sound analysis tasks. Yet, it is labor-intensive to accurately annotate large amount of audio data, and the dataset may contain noisy labels in the practical settings. Meanwhile, the deep neural networks are susceptive to those incorrect labeled data because of their outstanding memorization ability. In this paper, we present a novel framework, named CrossFilter, to combat the noisy labels problem for audio tagging. Multiple representations (such as, Logmel and MFCC) are used as the input of our framework for providing more complementary information of the audio. Then, though the cooperation and interaction of two neural networks, we divide the dataset into curated and noisy subsets by incrementally pick out the possibly correctly labeled data from the noisy data. Moreover, our approach leverages the multi-task learning on curated and noisy subsets with different loss function to fully utilize the entire dataset. The noisy-robust loss function is employed to alleviate the adverse effects of incorrect labels. On both the audio tagging datasets FSDKaggle2018 and FSDKaggle2019, empirical results demonstrate the performance improvement compared with other competing approaches. On FSDKaggle2018 dataset, our method achieves state-of-the-art performance and even surpasses the ensemble models.
General audio tagging with ensembling convolutional neural network and statistical features
Oct 30, 2018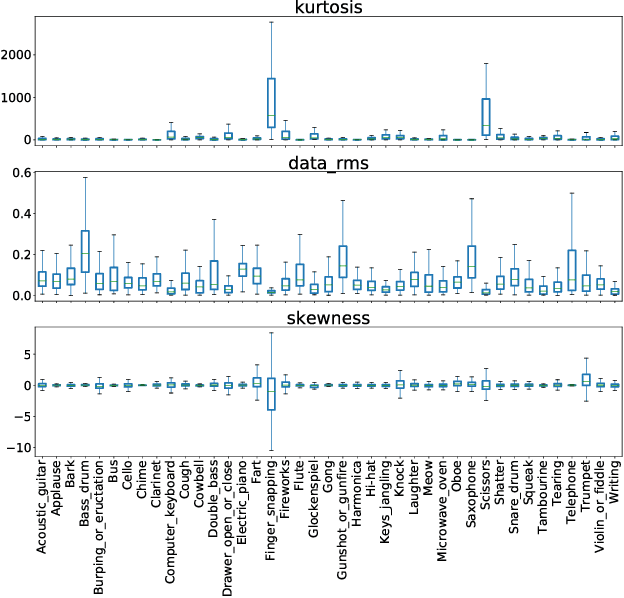
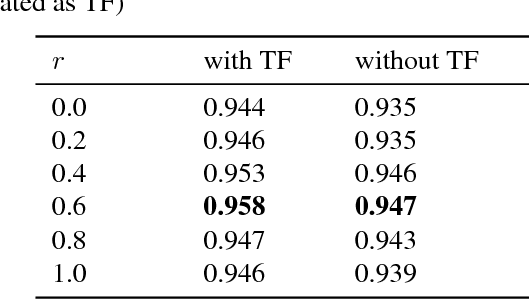
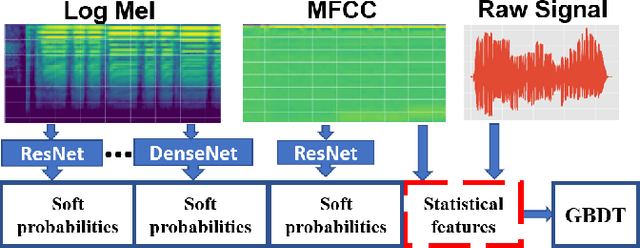
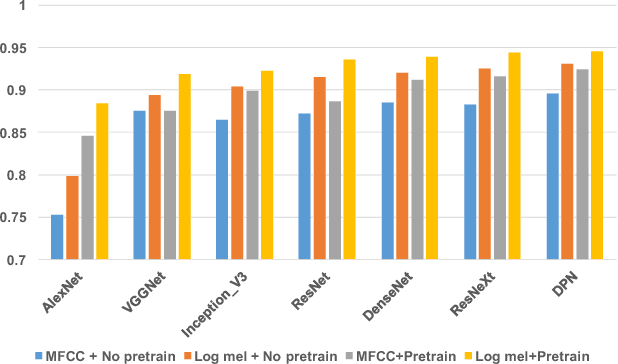
Audio tagging aims to infer descriptive labels from audio clips. Audio tagging is challenging due to the limited size of data and noisy labels. In this paper, we describe our solution for the DCASE 2018 Task 2 general audio tagging challenge. The contributions of our solution include: We investigated a variety of convolutional neural network architectures to solve the audio tagging task. Statistical features are applied to capture statistical patterns of audio features to improve the classification performance. Ensemble learning is applied to ensemble the outputs from the deep classifiers to utilize complementary information. a sample re-weight strategy is employed for ensemble training to address the noisy label problem. Our system achieves a mean average precision (mAP@3) of 0.958, outperforming the baseline system of 0.704. Our system ranked the 1st and 4th out of 558 submissions in the public and private leaderboard of DCASE 2018 Task 2 challenge. Our codes are available at https://github.com/Cocoxili/DCASE2018Task2/.
Mixup-Based Acoustic Scene Classification Using Multi-Channel Convolutional Neural Network
May 18, 2018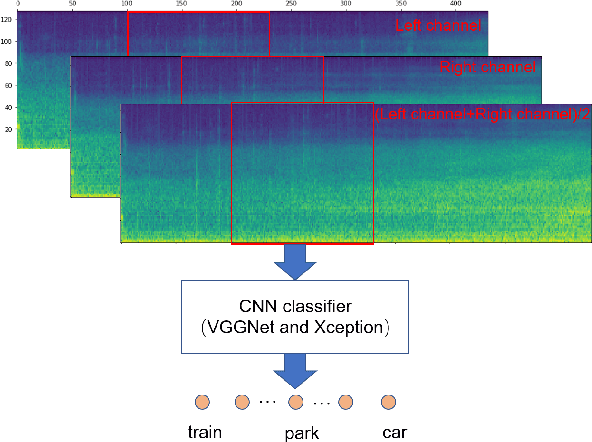
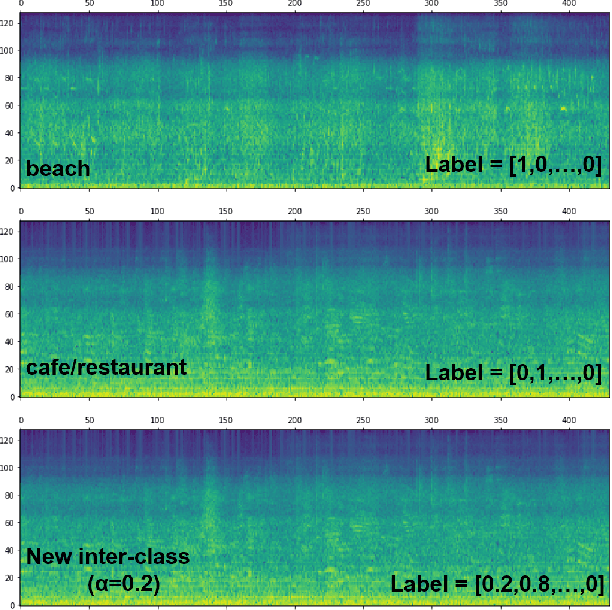
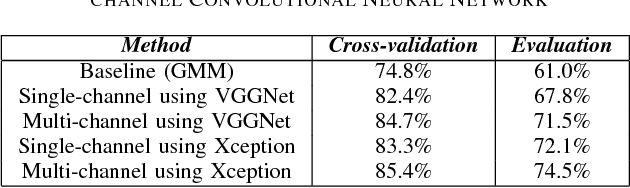
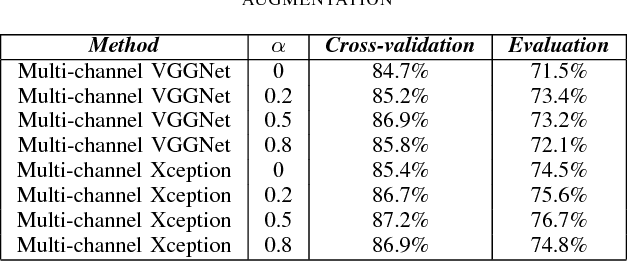
Audio scene classification, the problem of predicting class labels of audio scenes, has drawn lots of attention during the last several years. However, it remains challenging and falls short of accuracy and efficiency. Recently, Convolutional Neural Network (CNN)-based methods have achieved better performance with comparison to the traditional methods. Nevertheless, conventional single channel CNN may fail to consider the fact that additional cues may be embedded in the multi-channel recordings. In this paper, we explore the use of Multi-channel CNN for the classification task, which aims to extract features from different channels in an end-to-end manner. We conduct the evaluation compared with the conventional CNN and traditional Gaussian Mixture Model-based methods. Moreover, to improve the classification accuracy further, this paper explores the using of mixup method. In brief, mixup trains the neural network on linear combinations of pairs of the representation of audio scene examples and their labels. By employing the mixup approach for data argumentation, the novel model can provide higher prediction accuracy and robustness in contrast with previous models, while the generalization error can also be reduced on the evaluation data.