 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Voice-Face Representation Learning by Cross-Modal Prototype Contrast
Paper and Code

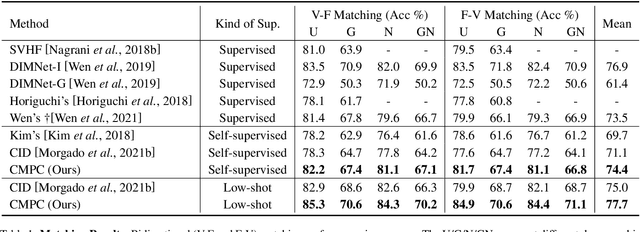
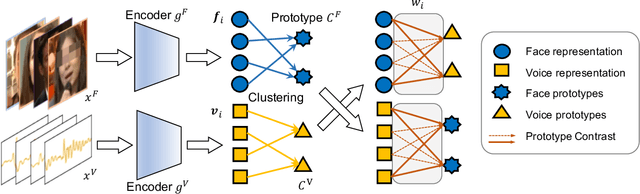
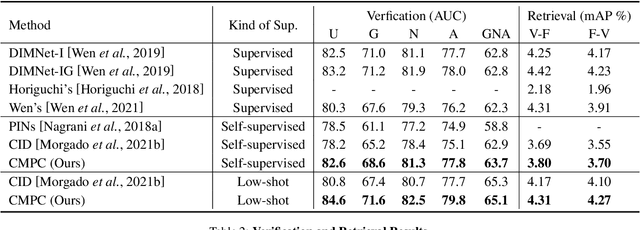
We present an approach to learn voice-face representations from the talking face videos, without any identity labels. Previous works employ cross-modal instance discrimination tasks to establish the correlation of voice and face. These methods neglect the semantic content of different videos, introducing false-negative pairs as training noise. Furthermore, the positive pairs are constructed based on the natural correlation between audio clips and visual frames. However, this correlation might be weak or inaccurate in a large amount of real-world data, which leads to deviating positives into the contrastive paradigm. To address these issues, we propose the cross-modal prototype contrastive learning (CMPC), which takes advantage of contrastive methods and resists adverse effects of false negatives and deviate positives. On one hand, CMPC could learn the intra-class invariance by constructing semantic-wise positives via unsupervised clustering in different modalities. On the other hand, by comparing the similarities of cross-modal instances from that of cross-modal prototypes, we dynamically recalibrate the unlearnable instances' contribution to overall loss. Experiments show that the proposed approach outperforms state-of-the-art unsupervised methods on various voice-face association evaluation protocols. Additionally, in the low-shot supervision setting, our method also has a significant improvement compared to previous instance-wise contrastive learning.