 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempDiffReg: Temporal Diffusion Model for Non-Rigid 2D-3D Vascular Registration
Jan 26, 2026Transarterial chemoembolization (TACE) is a preferred treatment option for hepatocellular carcinoma and other liver malignancies, yet it remains a highly challenging procedure due to complex intra-operative vascular navigation and anatomical variability. Accurate and robust 2D-3D vessel registration is essential to guide microcatheter and instruments during TACE, enabling precise localization of vascular structures and optimal therapeutic targeting. To tackle this issue, we develop a coarse-to-fine registration strategy. First, we introduce a global alignment module, structure-aware perspective n-point (SA-PnP), to establish correspondence between 2D and 3D vessel structures. Second, we propose TempDiffReg, a temporal diffusion model that performs vessel deformation iteratively by leveraging temporal context to capture complex anatomical variations and local structural changes. We collected data from 23 patients and constructed 626 paired multi-frame samples for comprehensive evaluation. Experimental results demonstrate that the proposed method consistently outperforms state-of-the-art (SOTA) methods in both accuracy and anatomical plausibility. Specifically, our method achieves a mean squared error (MSE) of 0.63 mm and a mean absolute error (MAE) of 0.51 mm in registration accuracy, representing 66.7\% lower MSE and 17.7\% lower MAE compared to the most competitive existing approaches. It has the potential to assist less-experienced clinicians in safely and efficiently performing complex TACE procedures, ultimately enhancing both surgical outcomes and patient care. Code and data are available at: \textcolor{blue}{https://github.com/LZH970328/TempDiffReg.git}
Well Begun, Half Done: Reinforcement Learning with Prefix Optimization for LLM Reasoning
Dec 17, 2025Reinforcement Learning with Verifiable Rewards (RLVR) significantly enhances the reasoning capability of Large Language Models (LLMs). Current RLVR approaches typically conduct training across all generated tokens, but neglect to explore which tokens (e.g., prefix tokens) actually contribute to reasoning. This uniform training strategy spends substantial effort on optimizing low-return tokens, which in turn impedes the potential improvement from high-return tokens and reduces overall training effectiveness. To address this issue, we propose a novel RLVR approach called Progressive Prefix-token Policy Optimization (PPPO), which highlights the significance of the prefix segment of generated outputs. Specifically, inspired by the well-established human thinking theory of Path Dependence, where early-stage thoughts substantially constrain subsequent thinking trajectory, we identify an analogous phenomenon in LLM reasoning termed Beginning Lock-in Effect (BLE). PPPO leverages this finding by focusing its optimization objective on the prefix reasoning process of LLMs. This targeted optimization strategy can positively influence subsequent reasoning processes, and ultimately improve final results. To improve the learning effectiveness of LLMs on how to start reasoning with high quality, PPPO introduces two training strategies: (a) Progressive Prefix Retention, which shapes a progressive learning process by increasing the proportion of retained prefix tokens during training; (b) Continuation Accumulated Reward, which mitigates reward bias by sampling multiple continuations for one prefix token sequence, and accumulating their scores as the reward signal. Extensive experimental results on various reasoning tasks demonstrate that our proposed PPPO outperforms representative RLVR methods, with the accuracy improvements of 18.02% on only 26.17% training tokens.
Fast-Slow-Thinking: Complex Task Solving with Large Language Models
Apr 11, 2025Nowadays, Large Language Models (LLMs) have been gradually employed to solve complex tasks. To face the challenge, task decomposition has become an effective way, which proposes to divide a complex task into multiple simpler subtasks and then solve them separately so that the difficulty of the original task can be reduced. However, the performance of existing task decomposition methods can be suboptimal when the task contains overly complex logic and constraints. In this situation, the solution generated by LLMs may deviate from the original purpose of the task, or contain redundant or even erroneous content. Therefore, inspired by the fact that humans possess two thinking systems including fast thinking and slow thinking, this paper introduces a new task decomposition method termed ``Fast-Slow-Thinking'' (FST), which stimulates LLMs to solve tasks through the cooperation of Fast Thinking (FT) and Slow Thinking (ST) steps. Here FT focuses more on the general and concise aspect of the task, and ST focuses more on the details of the task. In FT, LLMs are prompted to remove the constraints of the original task, therefore simplifying it to a general and concise one. In ST, we recall the constraints removed in FT, so that LLMs can improve the answer generated in FT to meet the requirements of the original task. Therefore, our FST method enables LLMs to consider a complex problem via a human-like cognition process from coarse to fine, the effectiveness of which has been well demonstrated by the experiments on three types of tasks.
Large Language Models as an Indirect Reasoner: Contrapositive and Contradiction for Automated Reasoning
Feb 06, 2024Recently, increasing attention has been focused drawn on to improve the ability of Large Language Models (LLMs) to perform complex reasoning. However, previous methods, such as Chain-of-Thought and Self-Consistency, mainly follow Direct Reasoning (DR) frameworks, so they will meet difficulty in solving numerous real-world tasks which can hardly be solved via DR. Therefore, to strengthen the reasoning power of LLMs, this paper proposes a novel Indirect Reasoning (IR) method that employs the logic of contrapositives and contradictions to tackle IR tasks such as factual reasoning and mathematic proof. Specifically, our methodology comprises two steps. Firstly, we leverage the logical equivalence of contrapositive to augment the data and rules to enhance the comprehensibility of LLMs. Secondly, we design a set of prompt templates to trigger LLMs to conduct IR based on proof by contradiction that is logically equivalent to the original DR process. Our IR method is simple yet effective and can be straightforwardly integrated with existing DR methods to further boost the reasoning abilities of LLMs. The experimental results on popular LLMs, such as GPT-3.5-turbo and Gemini-pro, show that our IR method enhances the overall accuracy of factual reasoning by 27.33% and mathematical proof by 31.43%, when compared with traditional DR methods. Moreover, the methods combining IR and DR significantly outperform the methods solely using IR or DR, further demonstrating the effectiveness of our strategy.
More Industry-friendly: Federated Learning with High Efficient Design
Dec 16, 2020
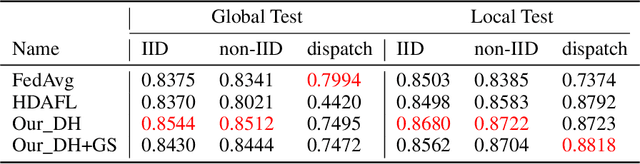


Although many achievements have been made since Google threw out the paradigm of federated learning (FL), there still exists much room for researchers to optimize its efficiency. In this paper, we propose a high efficient FL method equipped with the double head design aiming for personalization optimization over non-IID dataset, and the gradual model sharing design for communication saving. Experimental results show that, our method has more stable accuracy performance and better communication efficient across various data distributions than other state of art methods (SOTAs), makes it more industry-friendly.