 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenetically Aligned Patient Representations Improve Hematological Diagnosis
May 28, 2026Multimodal alignment of histopathology encoders with transcriptomic and genomic data has been shown to significantly improve performance in downstream diagnostic tasks. Hematological cytology is unique in that visual single-cell evaluation is often paired with cytogenetics and molecular genetics for blood cancer diagnosis. In this study, we present a framework to align single white blood cell images with chromosomal aberrations (karyotype) and somatic mutations from targeted gene panels. Our training strategy follows a two-stage approach: (i) self-supervised, vision-only pretraining of a transformer aggregator using an iBOT head on a cohort of over 1500 patients, and (ii) genetic alignment via supervised contrastive loss on acute myeloid leukemia patients. Our genetically aligned patient encoder improves hematological diagnostic tasks, outperforming slide-level histopathology foundation models. Additionally, the model provides off-the-shelf retrieval capabilities for diseases and genetic alterations. Incorporating genetic data into patient encoders increases the quality of patient representations, providing a framework that aligns with clinical diagnostic workflows and paves the way for future multimodal hematology-specific AI. The code and model weights are available at https://github.com/marrlab/GenBloom.
A Multicenter Benchmark of Multiple Instance Learning Models for Lymphoma Subtyping from HE-stained Whole Slide Images
Dec 16, 2025Timely and accurate lymphoma diagnosis is essential for guiding cancer treatment. Standard diagnostic practice combines hematoxylin and eosin (HE)-stained whole slide images with immunohistochemistry, flow cytometry, and molecular genetic tests to determine lymphoma subtypes, a process requiring costly equipment, skilled personnel, and causing treatment delays. Deep learning methods could assist pathologists by extracting diagnostic information from routinely available HE-stained slides, yet comprehensive benchmarks for lymphoma subtyping on multicenter data are lacking. In this work, we present the first multicenter lymphoma benchmarking dataset covering four common lymphoma subtypes and healthy control tissue. We systematically evaluate five publicly available pathology foundation models (H-optimus-1, H0-mini, Virchow2, UNI2, Titan) combined with attention-based (AB-MIL) and transformer-based (TransMIL) multiple instance learning aggregators across three magnifications (10x, 20x, 40x). On in-distribution test sets, models achieve multiclass balanced accuracies exceeding 80% across all magnifications, with all foundation models performing similarly and both aggregation methods showing comparable results. The magnification study reveals that 40x resolution is sufficient, with no performance gains from higher resolutions or cross-magnification aggregation. However, on out-of-distribution test sets, performance drops substantially to around 60%, highlighting significant generalization challenges. To advance the field, larger multicenter studies covering additional rare lymphoma subtypes are needed. We provide an automated benchmarking pipeline to facilitate such future research.
DomainLab: A modular Python package for domain generalization in deep learning
Mar 21, 2024
Poor generalization performance caused by distribution shifts in unseen domains often hinders the trustworthy deployment of deep neural networks. Many domain generalization techniques address this problem by adding a domain invariant regularization loss terms during training. However, there is a lack of modular software that allows users to combine the advantages of different methods with minimal effort for reproducibility. DomainLab is a modular Python package for training user specified neural networks with composable regularization loss terms. Its decoupled design allows the separation of neural networks from regularization loss construction. Hierarchical combinations of neural networks, different domain generalization methods, and associated hyperparameters, can all be specified together with other experimental setup in a single configuration file. Hierarchical combinations of neural networks, different domain generalization methods, and associated hyperparameters, can all be specified together with other experimental setup in a single configuration file. In addition, DomainLab offers powerful benchmarking functionality to evaluate the generalization performance of neural networks in out-of-distribution data. The package supports running the specified benchmark on an HPC cluster or on a standalone machine. The package is well tested with over 95 percent coverage and well documented. From the user perspective, it is closed to modification but open to extension. The package is under the MIT license, and its source code, tutorial and documentation can be found at https://github.com/marrlab/DomainLab.
Federated Learning for Data and Model Heterogeneity in Medical Imaging
Jul 31, 2023



Federated Learning (FL) is an evolving machine learning method in which multiple clients participate in collaborative learning without sharing their data with each other and the central server. In real-world applications such as hospitals and industries, FL counters the challenges of data heterogeneity and model heterogeneity as an inevitable part of the collaborative training. More specifically, different organizations, such as hospitals, have their own private data and customized models for local training. To the best of our knowledge, the existing methods do not effectively address both problems of model heterogeneity and data heterogeneity in FL. In this paper, we exploit the data and model heterogeneity simultaneously, and propose a method, MDH-FL (Exploiting Model and Data Heterogeneity in FL) to solve such problems to enhance the efficiency of the global model in FL. We use knowledge distillation and a symmetric loss to minimize the heterogeneity and its impact on the model performance. Knowledge distillation is used to solve the problem of model heterogeneity, and symmetric loss tackles with the data and label heterogeneity. We evaluate our method on the medical datasets to conform the real-world scenario of hospitals, and compare with the existing methods. The experimental results demonstrate the superiority of the proposed approach over the other existing methods.
Imbalanced Domain Generalization for Robust Single Cell Classification in Hematological Cytomorphology
Mar 14, 2023



Accurate morphological classification of white blood cells (WBCs) is an important step in the diagnosis of leukemia, a disease in which nonfunctional blast cells accumulate in the bone marrow. Recently, deep convolutional neural networks (CNNs) have been successfully used to classify leukocytes by training them on single-cell images from a specific domain. Most CNN models assume that the distributions of the training and test data are similar, i.e., that the data are independently and identically distributed. Therefore, they are not robust to different staining protocols, magnifications, resolutions, scanners, or imaging protocols, as well as variations in clinical centers or patient cohorts. In addition, domain-specific data imbalances affect the generalization performance of classifiers. Here, we train a robust CNN for WBC classification by addressing cross-domain data imbalance and domain shifts. To this end, we use two loss functions and demonstrate the effectiveness on out-of-distribution (OOD) generalization. Our approach achieves the best F1 macro score compared to other existing methods, and is able to consider rare cell types. This is the first demonstration of imbalanced domain generalization in hematological cytomorphology and paves the way for robust single cell classification methods for the application in laboratories and clinics.
Real Image Super-Resolution using GAN through modeling of LR and HR process
Oct 19, 2022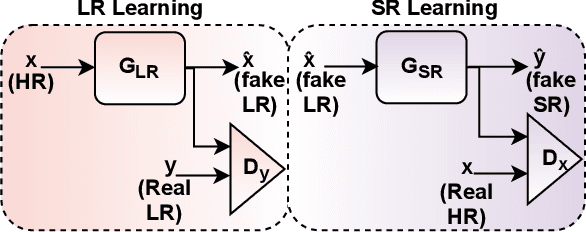
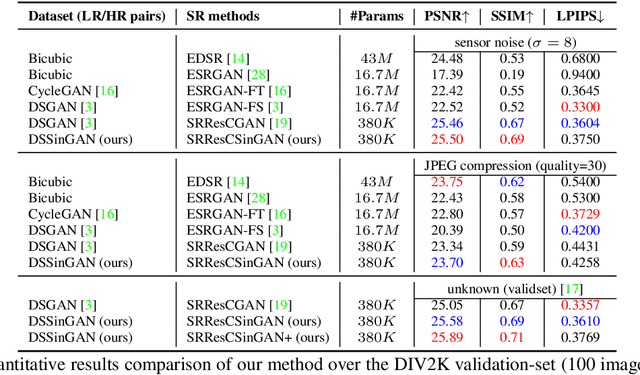
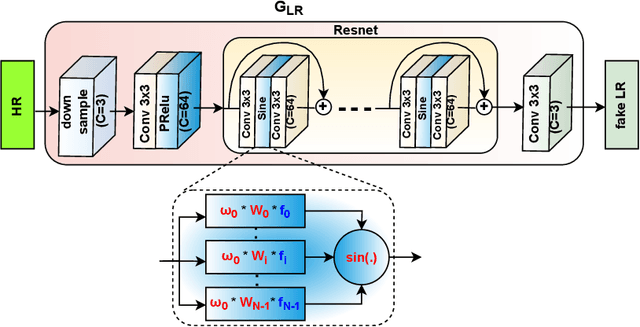
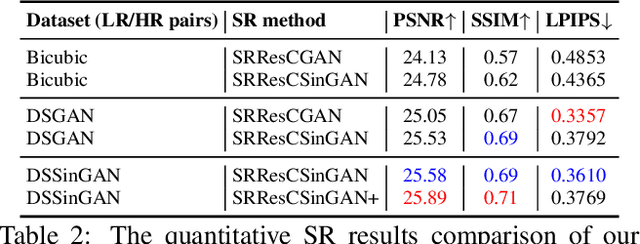
The current existing deep image super-resolution methods usually assume that a Low Resolution (LR) image is bicubicly downscaled of a High Resolution (HR) image. However, such an ideal bicubic downsampling process is different from the real LR degradations, which usually come from complicated combinations of different degradation processes, such as camera blur, sensor noise, sharpening artifacts, JPEG compression, and further image editing, and several times image transmission over the internet and unpredictable noises. It leads to the highly ill-posed nature of the inverse upscaling problem. To address these issues, we propose a GAN-based SR approach with learnable adaptive sinusoidal nonlinearities incorporated in LR and SR models by directly learn degradation distributions and then synthesize paired LR/HR training data to train the generalized SR model to real image degradations. We demonstrate the effectiveness of our proposed approach in quantitative and qualitative experiments.
RBSRICNN: Raw Burst Super-Resolution through Iterative Convolutional Neural Network
Nov 10, 2021
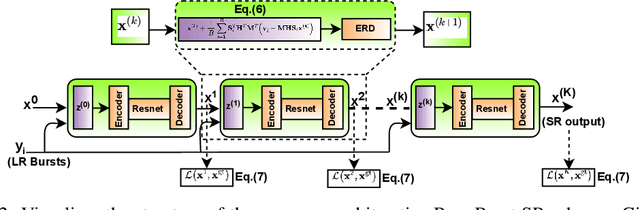

Modern digital cameras and smartphones mostly rely on image signal processing (ISP) pipelines to produce realistic colored RGB images. However, compared to DSLR cameras, low-quality images are usually obtained in many portable mobile devices with compact camera sensors due to their physical limitations. The low-quality images have multiple degradations i.e., sub-pixel shift due to camera motion, mosaick patterns due to camera color filter array, low-resolution due to smaller camera sensors, and the rest information are corrupted by the noise. Such degradations limit the performance of current Single Image Super-resolution (SISR) methods in recovering high-resolution (HR) image details from a single low-resolution (LR) image. In this work, we propose a Raw Burst Super-Resolution Iterative Convolutional Neural Network (RBSRICNN) that follows the burst photography pipeline as a whole by a forward (physical) model. The proposed Burst SR scheme solves the problem with classical image regularization, convex optimization, and deep learning techniques, compared to existing black-box data-driven methods. The proposed network produces the final output by an iterative refinement of the intermediate SR estimates. We demonstrate the effectiveness of our proposed approach in quantitative and qualitative experiments that generalize robustly to real LR burst inputs with onl synthetic burst data available for training.
A Deep Residual Star Generative Adversarial Network for multi-domain Image Super-Resolution
Jul 07, 2021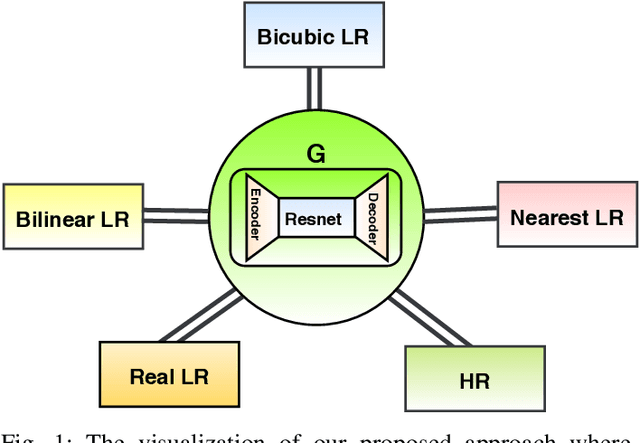
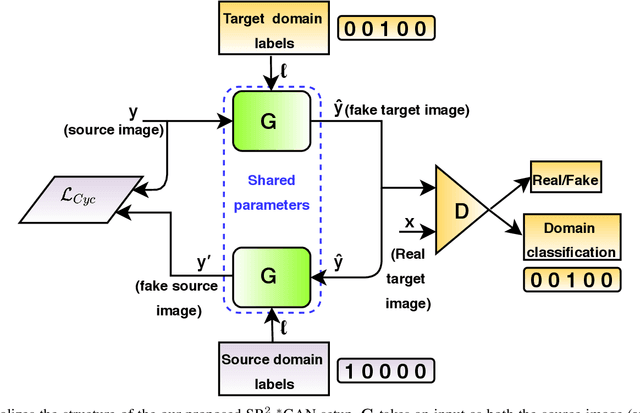
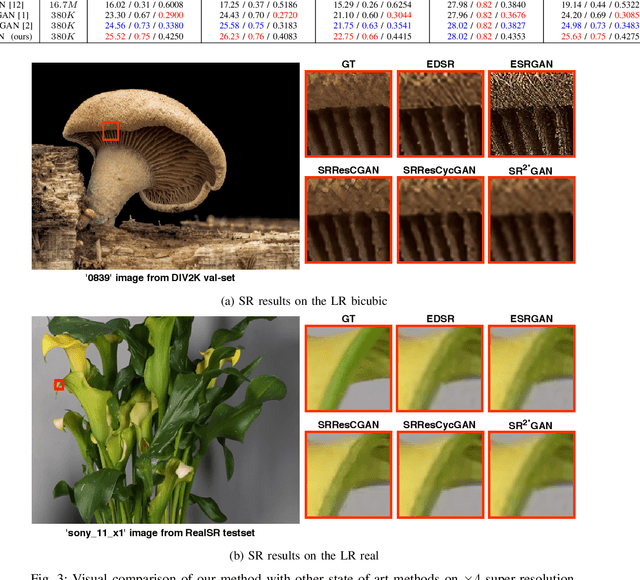
Recently, most of state-of-the-art single image super-resolution (SISR) methods have attained impressive performance by using deep convolutional neural networks (DCNNs). The existing SR methods have limited performance due to a fixed degradation settings, i.e. usually a bicubic downscaling of low-resolution (LR) image. However, in real-world settings, the LR degradation process is unknown which can be bicubic LR, bilinear LR, nearest-neighbor LR, or real LR. Therefore, most SR methods are ineffective and inefficient in handling more than one degradation settings within a single network. To handle the multiple degradation, i.e. refers to multi-domain image super-resolution, we propose a deep Super-Resolution Residual StarGAN (SR2*GAN), a novel and scalable approach that super-resolves the LR images for the multiple LR domains using only a single model. The proposed scheme is trained in a StarGAN like network topology with a single generator and discriminator networks. We demonstrate the effectiveness of our proposed approach in quantitative and qualitative experiments compared to other state-of-the-art methods.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021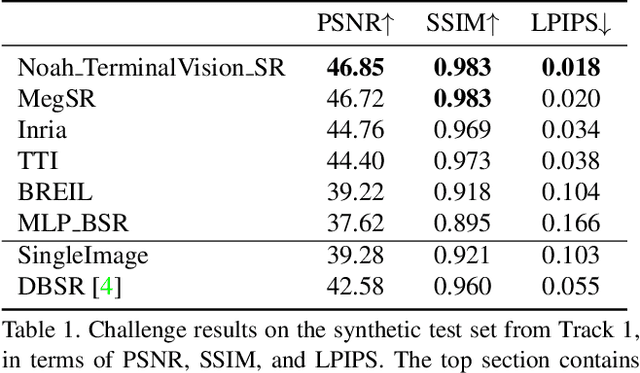

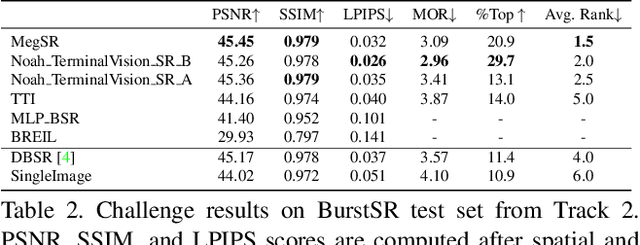

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020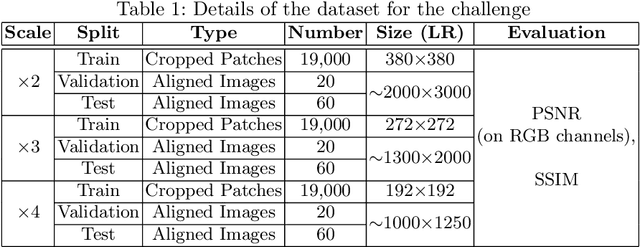
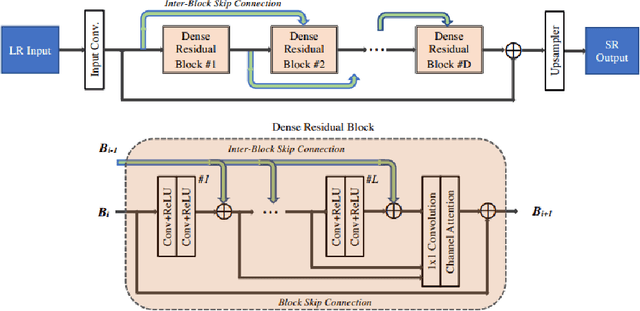
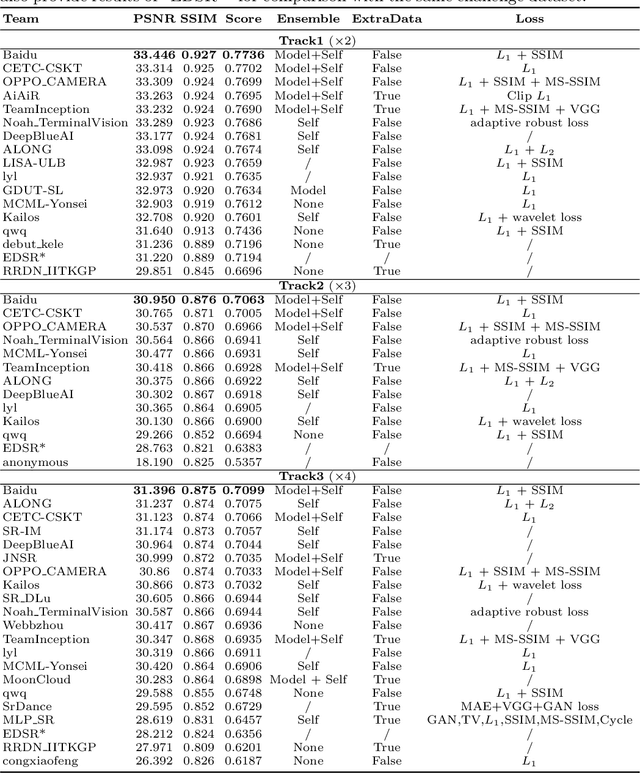
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.